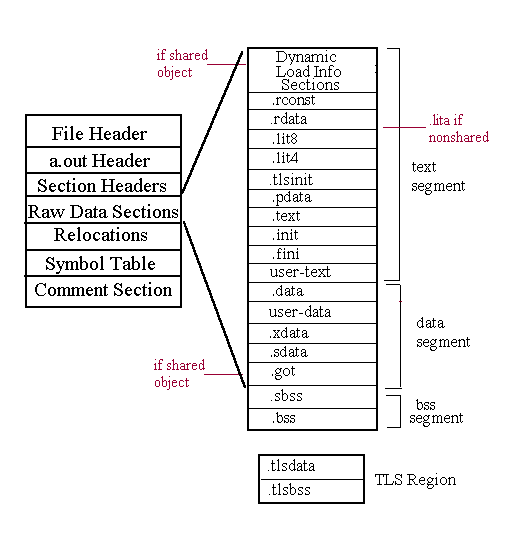
Instructions and data are the portions of the object file that are logically copied into the final process image. Instructions include all executable machine code. Data includes initialized and zero-initialized data, constant data, exception-handling data structures, and thread local storage (TLS) data. The breakdown of the instructions and data into object file sections is shown in Figure 3-1.
Object file sections are organized into three loadable segments: text, data, and bss. Multiple TLS regions may also be loaded. The mapping of sections into segments is principally determined by segment access permissions and object file. Figure 3-1 illustrates the layout of a typical dynamic executable file. See Section 2.3.2 for details.
Figure 3-1: Raw Data Sections of an Object File
The object file sections containing dynamic load information are covered
separately in
Chapter 14.
Chapter 15
describes
the
.comment
section data.
This chapter covers all other
raw data sections.
3.1 New or Changed Instructions and Data Features
Version 5.1 of Tru64 UNIX adds new fields to the code range descriptor (see Section 3.2.1) and the run-time procedure descriptor (see Section 3.2.2).
Version 5.0 of Tru64 UNIX supports a new name-recognition mechanism for ordering subsystem-generated initialization and termination routines. See Section 3.3.5.2.4 for details.
Version 3.13 of the object file format does not introduce any new features
for the instructions or data contained within the object file.
3.2 Structures, Fields, and Values for Instructions and Data
Section 3.2.1
and
Section 3.2.2
contain structure declarations for the exception-handling
data structures as stored in the
.xdata
and
.pdata
object file sections.
These are the only two sections covered in
this chapter that contain structured data.
Text sections containing machine
instructions use the Alpha instruction formats and other sections contain
binary and character data.
3.2.1 Code Range Descriptor (pdsc.h)
The
.pdata
section contains a table of code range descriptors ordered by address.
typedef unsigned int pdsc_mask;
typedef unsigned int pdsc_space;
typedef int pdsc_offset;
union pdsc_crd {
struct {
pdsc_offset begin_address;
pdsc_offset rpd_offset;
} words;
struct {
pdsc_mask context_t :1; (V5.1 - )
pdsc_mask context_s :1; (V5.1 - )
pdsc_offset shifted_begin_address :30;
pdsc_mask no_prolog :1;
pdsc_mask memory_speculation :1;
pdsc_offset shifted_rpd_offset :30;
} fields;
}
SIZE - 8 bytes, ALIGNMENT - 4 bytes
Version Note The fields marked "V5.1" in the preceding structure definition are new fields for Tru64 UNIX V5.1 and greater. The new fields take the place of a reserved field so there is no change in the structure size.
See the
Calling Standard for Alpha Systems
for a full description.
3.2.2 Run-time Procedure Descriptor (pdsc.h)
The
.xdata
section contains run-time procedure descriptors.
These descriptors
are not necessarily sorted, and may be intermixed with unstructured exception-handling
data.
typedef unsigned char pdsc_uchar_offset;
typedef unsigned short pdsc_ushort_offset;
typedef unsigned int pdsc_count;
typedef unsigned int pdsc_register;
typedef unsigned long pdsc_address;
typedef union pdsc_rpd {
struct pdsc_short_stack_rpd {
pdsc_mask flags:8;
pdsc_uchar_offset rsa_offset;
pdsc_mask fmask:8;
pdsc_mask imask:8;
pdsc_count frame_size:16;
pdsc_count sp_set:8;
pdsc_count entry_length:8;
} short_stack_rpd;
struct pdsc_short_reg_rpd {
pdsc_mask flags:8;
pdsc_space reserved1:3;
pdsc_register entry_ra:5;
pdsc_register save_ra:5;
pdsc_space reserved2:11;
pdsc_count frame_size:16;
pdsc_count sp_set:8;
pdsc_count entry_length:8;
} short_reg_rpd;
struct pdsc_long_stack_rpd {
pdsc_mask flags:11;
pdsc_register entry_ra:5;
pdsc_ushort_offset rsa_offset;
pdsc_count sp_set:16;
pdsc_count entry_length:16;
pdsc_count frame_size;
pdsc_mask reserved:2; (V5.1 - )
pdsc_offset return_address:30; (V5.1 - )
pdsc_mask imask;
pdsc_mask fmask;
} long_stack_rpd;
struct pdsc_long_reg_rpd {
pdsc_mask flags:11;
pdsc_register entry_ra:5;
pdsc_register save_ra:5;
pdsc_space reserved1:11;
pdsc_count sp_set:16;
pdsc_count entry_length:16;
pdsc_count frame_size;
pdsc_mask reserved2:2; (V5.1 - )
pdsc_offset return_address:30; (V5.1 - )
pdsc_mask imask;
pdsc_mask fmask;
} long_reg_rpd;
struct pdsc_short_with_handler {
union {
struct pdsc_short_stack_rpd short_stack_rpd;
struct pdsc_short_reg_rpd short_reg_rpd;
} stack_or_reg;
pdsc_address handler;
pdsc_address handler_data;
} short_with_handler;
struct pdsc_long_with_handler {
union {
struct pdsc_long_stack_rpd long_stack_rpd;
struct pdsc_long_reg_rpd long_reg_rpd;
} stack_or_reg;
pdsc_address handler;
pdsc_address handler_data;
} long_with_handler;
} pdsc_rpd;
SIZE - 40 bytes, ALIGNMENT - 8 bytes
Version Note The fields marked "V5.1" in the preceding structure definition are new fields for Tru64 UNIX V5.1 and greater. The new fields take the place of a reserved field so there is no change in the structure size.
See the
Calling Standard for Alpha Systems
for a full description.
3.3 Instructions and Data Usage
3.3.1 Minimal Objects
Many sections may be missing from a still-viable object file. Sections may not be present due to the type of the object file or to the contents of a particular program.
The
.init
and
.fini
sections of
the text segment are typically not present in relocatable objects.
They contain
code generated during final link.
The allocation of data in the "small" and "large" writable data sections
(.sdata, .data, .sbss, .bss) can be controlled by the user in some
situations.
See
Section 3.3.6
for more details.
The
.lit4
and
.lit8
sections,
which hold 4- and 8-byte literal values respectively, may be omitted from
an object file.
Compilers may choose not to emit these sections.
The
.xdata
and
.pdata
sections,
which contain exception-handling information, may not be present.
All pre-link
objects with a non-empty text segment contain these sections because compilers
are expected to provide exception-handling information for their code.
Statically
linked executables will only contain these sections if they include code which
handles exceptions.
The linker identifies exception handling code by looking
for references to the
_fpdata_size
symbol.
By default, shared
objects will contain these sections.
The
.xdata
and
.pdata
sections are required if a shared object includes exception
handling code or if it is used in conjunction with another shared object that
includes exception handling code.
Although most objects contain both text and data segments, only one
loadable segment is required for an object to be loadable.
A minimal pre-link
object file may contain no sections.
3.3.2 Position-Independent Code (PIC)
Position-independent code is generated code that is not constrained to any particular location in the virtual address space. Eventually, code must be assigned to a portion of the address space where it can execute. However, on Tru64 UNIX, code is kept position-independent as long as possible.
The implementation of position-independent code in eCOFF relies upon address tables to store full virtual addresses for procedures and data locations invoked or referenced in the text segment. Programs refer to these addresses using a technique called GP-relative addressing.
Most eCOFF objects have address tables that hold
64-bit addresses.
Address tables in shared objects are called Global Offset
Tables (GOTs) and are found in the
.got
section.
Address
tables for relocatable and static objects are called literal address pools
and are found in the
.lita
section.
Address table entries
are accessed in code by adding a signed 16-bit offset to the currently active
GP value, which is stored in the
$gp
register:
ldq t12,-31656(gp)
Multiple GP ranges can be associated with a program, each corresponding to a different portion of the address table. See Section 2.3.4 for details.
In some cases, special instruction sequences may be required to update
the contents of the
$gp
register.
In particular, the GP
value used by a procedure may or may not be the same as the value used by
the calling code.
Under most circumstances, the called procedure's GP value
is calculated when a procedure is invoked.
Upon completion of the procedure's
execution, the calling code's GP value must be reestablished.
Refer to the
Calling Standard for Alpha Systems
for details.
Different kinds of objects use address tables in different ways:
Pre-link objects usually have a
.lita
section with
associated section relocation information.
The literal address pool contains
addresses that must be adjusted at link time.
Addresses in static executables are fixed at link time. The image must be loaded and executed at addresses the linker has chosen. Library addresses as well as segment base addresses are known at link time.
Static executables store addresses in a
.lita
section
that encompasses one or more GP ranges.
The contents of the address table
are accessed by means of the GP value or values, which are also fixed at link
time.
Each
.lita
entry in the input object files is relocated
by the linker to form the GOT in the output object.
The loader may need to
update the GOT entries when mapping the process image.
The addresses are then
absolute and may be extracted at run time to obtain the final locations of
referenced items.
The loader may also update GOT entries at run time, such as when it replaces lazy text stubs with resolved procedure addresses or dynamically loads new objects.
The GOT may contain entries for nonsymbolic text and data addresses. These are known as local GOT entries. The GOT may also contain entries for unresolvable symbols; which are either set to NULL or to the address of a lazy text stub routine.
Special semantics are associated with multiple GP ranges in shared objects. See Section 14.3.3.3 for details on multiple GOT representation and usage.
Code can be only partially position independent.
For example, shared
libraries can be mapped anywhere in the address space that is not in conflict
with previously mapped objects, but executable objects must be mapped at their
link-time base addresses.
Dynamic executables are thus partly PIC because
their own segment addresses are fixed, but the addresses of shared libraries
they use are not.
Static executables are position dependent (nonPIC) and can
be optimized to rely on more efficient position dependent methods for accessing
program addresses.
3.3.3 Lazy-Text Stubs
This section applies to shared objects only. See Section 14.3.4.5 for related information.
Final addresses may be unknown at link time for subroutines that are defined in shared libraries and called by dynamic executables. Instructions reference these routines in an address-independent manner, and the dynamic loader resolves the procedure's actual address the first time it is invoked.
Stubs are specially constructed code fragments
used for this run-time symbol resolution.
They serve as placeholders for the
definitions of functions that cannot be resolved at static link time.
The
linker builds the stub for each called procedure and allocates GOT table entries
that point to the stubs.
The stubs themselves are inserted in the
.text
section of the shared object file by the linker.
A stub looks like this:
stub_xyz:
ldq t12, got_index(gp) //load register with .got entry
// of lazy text resolver
lda $at, dynsym_index_low(zero) //load register with external
ldah $at, dynsym_index_high($at) // symbol's .dynsym index
jmp t12, (t12) //jump to lazy text resolver
The first time the procedure is called, its stub is invoked. The stub, in turn, calls the loader to resolve the associated symbol. The dynamic loader then replaces the stub address with the correct procedure address, which is used for subsequent calls.
The calling standard requires that when control actually reaches the
procedure's entry point, register
$r27
must contain the
procedure value of the newly loaded routine (as if no intermediate processing
had occurred).
3.3.4 Constant Data
Constant data is data that cannot be changed over the course of program execution. It can include constants appearing in the source program, constants that are generated during the compilation process (usually addresses), and literal values (also referred to as immediate values).
Constant data may appear in any
data section.
It is likely to appear in the
.lit4,
.lit8,
.lita,
.rconst, and
.rdata
sections.
Compilers and other object file producers may make
varying choices concerning data placement in object file sections.
The literal sections contain only literal values sorted by sizes.
4-byte
literals are stored in the
.lit4
section, 8-byte literals
in the
.lit8
section, and 8-byte address literals in the
.lita
section.
However, these sections do not necessarily contain
all the literals in the program.
String literals, for example, are assigned
to the
.data
section (or
.rconst
section
when the
-read_only_strings
compiler option is specified).
There are compile-time, link-time, and run-time constants. Examples of compile-time constants include numeric constant data such as floating-point constants and literals appearing in the source file. Examples of link-time constants include addresses that are fully resolved at link time. Examples of run-time constants include addresses established by the dynamic loader.
The linker places
the
.rconst
section and all three literal sections with
the text segment because they contain nonwritable data.
The advantage of mapping
constant data with a program's read-only segment is that it allows the data
to be shared among processes.
The
.rdata
section contains constant data with values
that may not be known until run time (such as global symbol addresses).
For
shared objects, the
.rdata
section is mapped with the data
segment so the loader can perform relocations for that section without affecting
the shareability of text or page table pages.
If there are no dynamic relocations,
the
.rdata
section may be mapped with the text segment.
3.3.5 INIT/FINI Driver Routines
Every
compilation unit in an executable or shared library has the opportunity to
contribute initialization or termination code to be run at startup and exit,
respectively.
INIT routines perform initialization actions and are run automatically
at load time or by the routine
dlopen().
FINI routines
are termination functions that are executed by
dlclose()
or at program termination by
exit().
The
.init
and
.fini
sections consist of a series of calls
to the initialization and termination routines.
These calls, or drivers, are
generated by the linker.
They are not present in pre-link objects.
The
.init
driver is invoked by a call from startup code in
/usr/lib/cmplrs/cc/crt0.o, which must be linked into every executable
object file.
The driver code in the
.init
and
.fini
sections has the following characteristics:
No associated symbolic information
No associated call frame information
Use of self-relative code for jumping to the routines; therefore, no use of the GOT table or GP value
The initialization and termination routines themselves are in the
.text
section and have the following characteristics:
No arguments
No return value
Defined in one of the objects or archives being linked
Figure 3-2 presents a graphical overview of the INIT/FINI mechanism for shared objects:
Figure 3-2: INIT/FINI Routines in Shared Objects
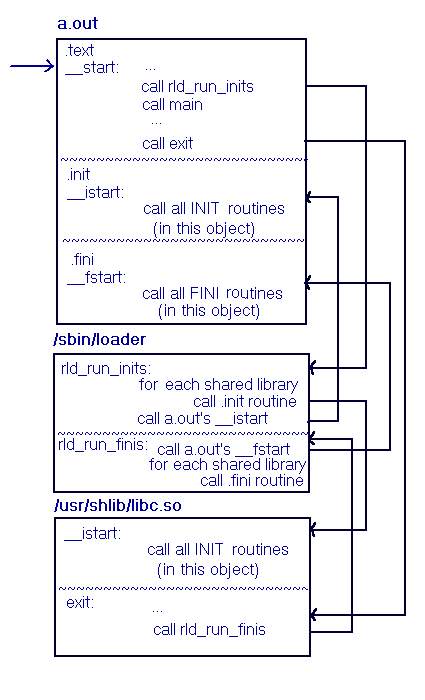
For static executables, the first call is to the main object's
__istart()
symbol instead of
rld_run_init().
The
dynamic loader is not involved.
System tools can generate initialization and termination routines. For example, global constructor and destructor routines for static objects are implemented as INIT/FINI routines by the C++ compiler.
The INIT/FINI mechanism
is used for allocation and deallocation of thread-specific data.
Every object
using TLS has its own INIT routine to take care of the TLS data associated
with that object.
The purpose of this INIT routine is to allocate a TSD key
that will be used for the object's TLS for the duration of the object mapping.
See
Section 3.3.9
for more information on TLS data.
3.3.5.1 Linking
INIT and FINI routines can be included implicitly, by prefix recognition,
or explicitly, by option processing.
With either linking method, as the routine's
symbols are identified, a list determining the execution order is built.
When
the list is complete, code to invoke the routines is generated by the linker
and placed in the
.init
and
.fini
sections.
To link explicitly, the -init and -fini linker options are used with a symbol parameter. The symbol should meet the criteria listed above for INIT and FINI routines.
To link implicitly, it is necessary to conform to naming and usage conventions. A symbol is recognized as an initialization or termination symbol if:
Automatic recognition of special symbols is not disabled.
The symbol is defined in an object included in the link.
The symbol bears the correct prefix (__init_
or
__fini_).
The symbol is a procedure.
Library archives may contain aptly named routines that are not implicitly linked into an object as INIT or FINI routines. The reason this situation can occur is that prefix recognition alone is not sufficient cause to extract a module from an archive.
Figure 3-3: INIT/FINI Recognition in Archive Libraries
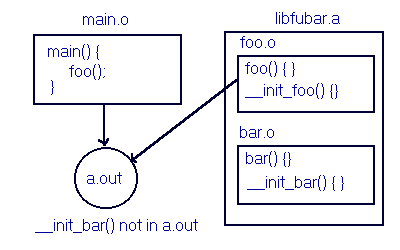
On the other hand, if the archived object is already linked into the object, prefix recognition will apply to routines contained in that module. Explicit inclusion can be used to ensure an archived routine is included as an initialization or termination routine in all cases. See the Programmer's Guide for more information on linking with archive libraries.
The linker's
-no_prefix_recognition
option disables
implicit linking of INIT and FINI routines.
3.3.5.2 Execution Order
This section describes the execution order of initialization and termination
routines in dynamic and static executables.
It also covers the determining
factors used by the linker and loader to establish this order.
3.3.5.2.1 Dynamic Executables
The INIT driver routine for each shared object is executed after INIT drivers for all of its dependencies. Dependencies are processed in a post-order traversal of the dependency graph. The dependency graphs shown in this section are based on link-line ordering (a left "sibling" appears first on the link line) as well as the shared library dependency information.
FINI drivers are executed in precisely the reverse order of INIT drivers.
Figure 3-4: INIT/FINI Example (I)
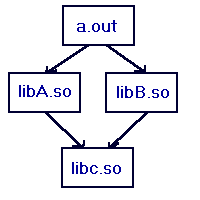
INIT order:
libc.so
libB.so
libA.so
a.out
FINI order:
a.out
libA.so
libB.so
libc.so
Cyclic dependencies are handled using a first-seen approach, while still conforming to the preceding rules. For example:
Figure 3-5: INIT/FINI Example (II)
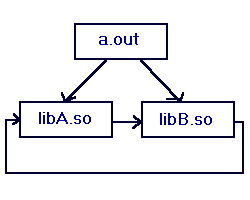
INIT order:
libA.so
libB.so
a.out
Initialization and termination routines may
also be executed when shared objects are loaded and unloaded dynamically during
run time.
dlopen()
runs INIT routines for any shared objects
that it loads.
dlclose()
runs FINI routines for each shared
object that it unloads.
Figure 3-6: INIT/FINI Example (III)
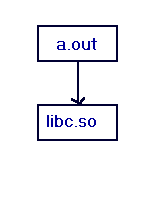
INIT order before dlopen call:
libc.so
a.out
Figure 3-7: INIT/FINI Example (IV)
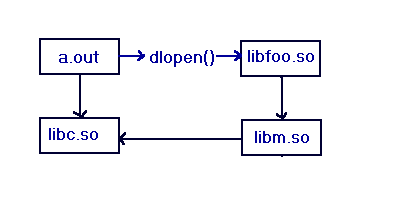
INIT order after dlopen call:
libm.so
libfoo.so
FINI order after dlopen call:
libfoo.so
libm.so
a.out
libc.so
3.3.5.2.2 Static Executables
For static executables, the execution order for initialization and termination routines is determined at link time. The linker establishes the execution order for INIT routines by the order in which they are encountered within an object's external symbol table and by the ordering of objects on the command line. It also takes into account the ordering of archive libraries on the command line. The INIT routines from each archive are executed in the reverse order of their occurrence on the command line. For example:
$ ld x.o y.o z.o libm.a libfoo.a
INIT order:
libfoo.a
libm.a
x.o
y.o
z.o
FINI order:
z.o
y.o
x.o
libm.a
libfoo.a
3.3.5.2.3 Ordering Within Objects
It is also possible to have multiple INIT or FINI routines within an object. The number of initialization or termination functions that can be included from a single object is unlimited. When multiple routines are encountered in an input object, they are placed as a group within the overall ordering.
If both methods of linking are used, explicitly linked initialization routines are executed prior to the implicitly linked routines for that object. Because the FINI order is always the opposite of the INIT order, any explicitly linked termination routines are executed last.
If the linker's range table generating routines are
present, they execute first and last, respectively in INIT/FINI ordering on
a per-object basis.
These initialization routines set up code range and GP
range tables used in exception-handling.
They execute first so that range
information is added before other INIT routines are executed.
These termination
routines run last so that all others are run before range information is removed.
These precautions allow other INIT and FINI routines to utilize exception
handling.
3.3.5.2.4 Subsystem Control of INIT/FINI Order
Version Note Subsystem generated initialization and termination routines are supported in Tru64 UNIX V5.0 and greater.
Compilers may need to generate initialization and termination routines and to control the order in which they execute. For this reason, subsystem-generated INIT and FINI routines are distinguished from user INIT and FINI routines.
The linker recognizes a subsystem-generated routine by the prefixes
__INIT_
and
__FINI_.
Routines recognized with
the
__INIT_
prefix always run prior to any routines recognized
with the
__init_
prefix within the same executable or shared
library.
FINI routines recognized with the
__FINI_
prefix
always run after any routines recognized with the
__fini_
prefix.
Subsystem INIT and FINI routines also run, respectively, before and
after any routines added by a user using the linker's
-init
and
-fini
switches.
All routines with the
__INIT_
prefix execute in alphabetic
order, and all routines with the
__FINI_
prefix execute
in reverse alphabetic order.
For a name of the form
__INIT_ALPHANAME, the
ALPHANAME
portion
should be encoded as a variable-length hexadecimal string.
The string will
contain one or more hex digits followed by an underscore.
INIT routines generated by the linker for exception-handling,
speculative execution, and thread-local storage run prior to all other INIT
routines.
The associated FINI routines run last.
3.3.6 Initialized Data and Zero-Initialized Data (bss)
Writable user-program data is divided between data (initialized data) and bss (zero-initialized data) sections, which may then be subdivided according to data element size. Zero-initialized data consists of program variables whose values are not specified at compile time. Initialized data includes all variables that are explicitly initialized in declaration statements.
One example of zero-initialized data is Fortran commons
.
Another is uninitialized C data (int count;).
Note that a C-global or C-static data item explicitly initialized to
zero (int count = 0;) may be placed in an initialized data
section, even though its value is the same as if it were part of bss.
The primary advantage
of separating initialized and uninitialized data is to save space in the object
file.
All bss data elements are set to the same value (zero).
The only information
required in the object file is a description of the run-time size and location
of the bss sections.
This description is found in the
.bss
and
.sbss
section headers.
Zero-filled memory is allocated for the bss segment when an object is
mapped into memory.
Because the
.bss
and
.sbss
raw data sections do not require space in the object file, their
section header size field reports the size of the section in the process image
instead of in the object file.
To take advantage of all available space, zero-initialized data immediately follows initialized data in the image. An object can have bss sections but no bss segment. If the data in the bss sections does not exceed the size of the leftover space in the last page of the data segment, the bss segment will be empty. This situation is illustrated in Figure 3-8.
Figure 3-8: Data and Bss Segment Layout (1)
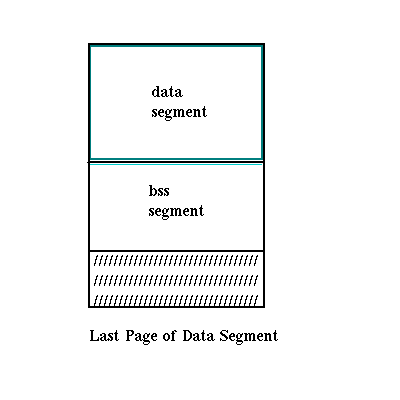
For the same reason, some bss data can potentially be present in the data segment, even if a separate bss segment exists. This situation is illustrated in Figure 3-9.
Figure 3-9: Data and Bss Segment Layout (II)
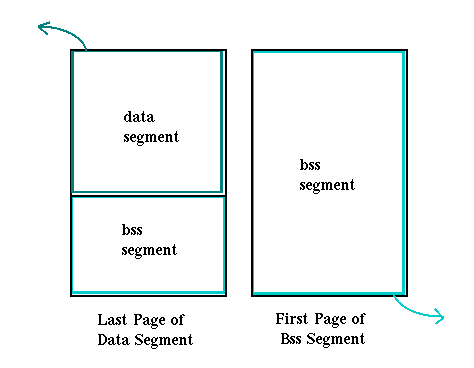
When part or all of the bss segment is contained in the last page of a data segment, that portion of the data page must be initialized to zero in the corresponding raw data area of the object file.
The division of initialized and uninitialized
data by size may split writable data into "small" (.sdata,
.sbss) and "large" (.data,
.bss)
sections.
It may be possible to exploit this division by grouping frequently
used data together in a section.
This strategy may enhance performance by
reducing page faults.
The size division may also allow post-link tools, such
as
om
and
spike, to generate more efficient
code sequences for accessing data items.
The default maximum value for an item allocated in a "small" section is eight bytes. Some compilers accept a -G option with a parameter to specify the maximum size of a "small" data item. However, the default compilers on Tru64 UNIX do not.
When speaking of item size, note that an aggregate data item is considered
as a whole.
For example, a string of ten characters has a size of ten bytes.
3.3.7 Permissions/Protections
When a process
image is created for a program, loadable segments are assigned access permissions.
These are determined by the file's MAGIC number and the segment type.
Table 3-1: Segment Access Permissions
| Image | Segment | Access Permissions |
OMAGIC |
text, data, bss | Read, Write, Execute |
NMAGIC |
text | Read, Execute |
NMAGIC |
data | Read, Write |
NMAGIC |
bss | Read, Write, Execute |
ZMAGIC |
text | Read, Execute |
ZMAGIC |
data | Read, Write |
ZMAGIC |
bss | Read, Write, Execute |
Exception handling is provided on the system to cope with unusual conditions. The object file contains two sections for storing exception-handling data structures. The declaration of these structures is shown in Section 3.2.
The object file sections
.xdata
and
.pdata
work together to provide exception-handling
support.
The
.xdata
section contains run-time procedure
descriptors, GP range information, and user-specified exception data.
The
.pdata
section contains code range descriptors.
Exception information
is produced for all pre-link object files.
The linker produces exception information
for dynamic executables and shared libraries because they will potentially
be utilized in conjunction with other dynamic executables or shared libraries
that rely on exception handling.
The linker also produces exception information
for static executables that reference
_fpdata_size, a linker-defined
symbol which represents the number of entries in the
.pdata
section.
A code range
descriptor associates a contiguous sequence of addresses with a run-time procedure
descriptor.
The
.pdata
code range descriptors are ordered
by run-time address.
The ranges never overlap.
The last
.pdata
entry is an end marker.
It may be followed by padding.
The code range descriptor points into both the text segment and the run-time procedure descriptors, as shown in Figure 3-10. The relationship between code range descriptors and run-time procedure descriptors can be a many-to-one relationship. Also note that a code range descriptor may not have an associated run-time procedure descriptor.
Figure 3-10: Exception-Handling Data Structures
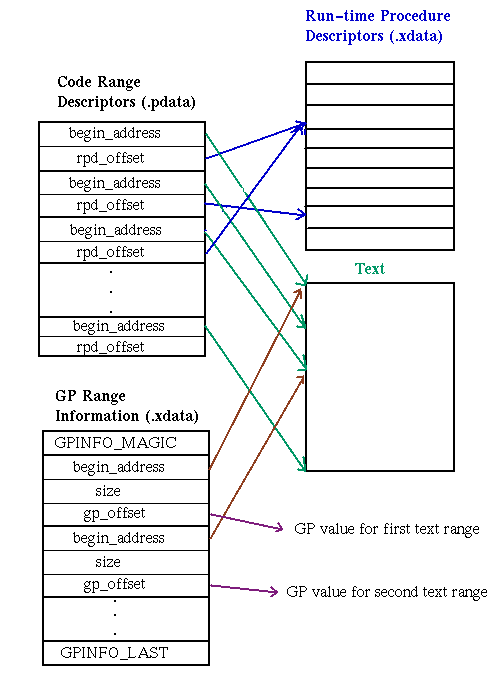
The virtual address space containing the text section of the object file is portioned into code ranges. Each code range descriptor has only one address, which indicates the beginning of the range. The range is implicitly ended just prior to the beginning address of the subsequent range. The final code range descriptor serves to end the range begun by the next-to-last descriptor, not to start a new range.
The GP range information can be accessed via
the special symbol
_gpinfo
(see
Section 2.3.7).
It is an array of signed 64 bit integers.
If the first entry is not
GPINFO_MAGIC
the GP range information should
be ignored.
The end of GP range information is identified by the constant
GPINFO_LAST.
(These constants can be found
in /usr/include/excpt.h.) Each range of instructions with a unique GP value
is represented by a set of three entries as shown in
Figure 3-10.
begin_addressThe address
of the first instruction in the GP range stored as an offset from
&_ftext.
sizeSize in bytes of the GP range.
gp_offsetThe GP value
used for the GP range stored as an offset from
&_fdata.
The
Programmer's Guide
and the
Calling Standard for Alpha Systems
provide detailed explanations
of the exception-handling mechanisms supported by Tru64 UNIX.
Related reference
pages such as
pdsc(4)exception_intro(3)
The data structures described in this section provide sufficient information
for general exception handling support.
Language-specific exception handling,
such as C++'s try/catch mechanism, layers additional information on top of
these basic structures.
An example illustrating the symbol table representation
of C++ exception information can be found in
Section 17.2.6.
3.3.9 Thread Local Storage (TLS) Data
Threads are available on Tru64 UNIX as a way to increase processor utilization and overall application performance. Thread Local Storage (TLS) provides a way for an application writer to declare data that has multiple instances, one per thread. The object file has specific structures designed to store and manage TLS. These structures and the impact of TLS on the object file and symbol table are described here. For general information about threads programming, see the Guide to DECthreads.
Three object file sections are devoted to TLS
data:
.tlsdata,
.tlsbss, and
.tlsinit.
The TLS region consists of the
.tlsdata
and
.tlsbss
sections.
The
.tlsinit
section,
which may be mapped with the object file's text or data segments, contains
initialization information for
.tlsdata.
Objects containing
TLS data are distinguished by the presence of these sections.
Structures outside the object file are used to reference TLS data. The Thread Environment Block (TEB) is an architected structure provided by system libraries. One of the fields in the TEB is the address of the Thread Specific Data (TSD) array, which contains pointers into the TLS region. Each object containing TLS will be allocated one or more TSD entries. In each thread, the TSD entries will contain the address of the start of a region of that thread's TLS area.
Figure 3-11: Thread Local Storage Data Structures
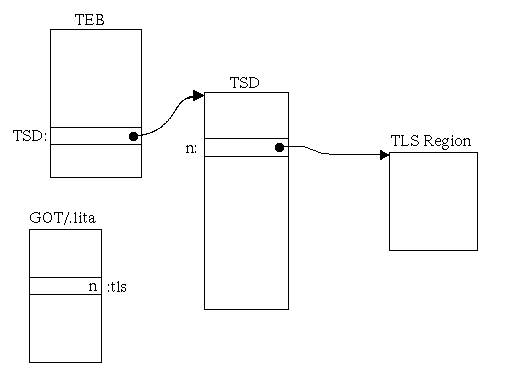
Because the TLS region is allocated dynamically and is unique per-thread, no address information can be recorded in the object file. All other attributes of the TLS region can be determined at link time and are recorded in the object file in the TLS data and TLS bss section headers.
The TLS data and bss sections occupy no space in the object file and do not have associated section relocation information.
The TLS INIT section contains the data which will be used to initialize
each thread's instance of the TLS data section at run time.
The TLS INIT
section can contain relocation information.
Only
R_REFQUAD
and
R_REFLONG
relocations are allowed, and the relocations must reference nonTLS symbols
or sections.
The TLS region for a shared object consists of the initialized and zero-initialized
TLS data defined by that object.
The TLS region is composed of two sections:
the TLS data section containing initialized TLS data (.tlsdata)
and the TLS bss section (.tlsbss) containing zero-initialized
TLS data.
If a shared object contains TLS data, an entry in the GOT (for the special
symbol
__tlsoffset
) contains the offset into the TSD array
to the array element that points to the TLS area.
If this is a multiple-GOT
shared object, the entry may be duplicated in each GOT.
The value of the GOT
entry is filled in at load time when the TLS initialization routine calls
the loader with the allocated TSD key value.
If a static executable contains TLS data, the address of
__tlsoffset
will normally be accessed through a
.lita
entry
that contains the value 2048, the offset to TSD key 256.
Special symbol types and relocation types are specific to TLS.
See
Chapter 6
and
Chapter 4
for more information.
3.3.10 User Text and User Data Sections
The linker contains provisions for creating and relocating user-defined object file sections. This feature was implemented for a specific customer at the customer's request. It is very rarely used and minimally supported. This section is designed to provide only a general overview.
Any number of user sections can be added to an object file. See Section 2.3.2 for the placement of the user sections in the various object file layouts.
The section header for a user section has the same semantics as those
used for other object file sections.
The section flags are set to
STYP_REG.
The user creating the section chooses
the section name.
User text sections are distinguished from user data sections
by their addresses.
User text sections have text segment addresses, and user
data sections have data segment addresses.
For user sections, the linker synthesizes special symbols for the start and end addresses of each section. These symbols take the form:
__fuser_section_SECTION_NAME
__euser_section_SECTION_NAME
where SECTION_NAME is the name in the section header. These linker-defined symbols are always strong symbols.
The linker also combines like-named user sections in multiple input files to form a single section in the output file.
User sections can only have external relocation records.
Namespace issues can arise due to the user's naming of these sections.
It is the responsibility of the user to protect against and recognize errors
caused by namespace issues.
3.4 Language-Specific Instructions and Data Features
Procedures with alternate entry points require multiple run-time procedure descriptors. See the Calling Standard for Alpha Systems for details.
C++ has exception handling facilities in addition to those discussed in this chapter.
C++ global constructors and destructors are implemented as initialization
and termination routines invoked by driver code stored in the
.init
and
.fini
sections.