![[Return to Library]](BOOKSHELF.GIF)
![[Contents]](TOC.GIF)
![[Previous Chapter]](REW.GIF)
![[Next Section]](NEXT.GIF)
![[Next Chapter]](FF.GIF)
![[Index]](INDEX.GIF)
![[Help]](HELP.GIF)
![]()
Before you attempt to tune your system to improve performance, you must fully understand your applications, users, and system environment and you must correctly diagnose the source of your performance problem. This chapter provides information on the major elements of the system environment that must be considered in a performance and tuning analysis:
For more information on all components of the operating system, refer to the manual Technical Overview.
![]()
The Alpha architecture contains instructions that can operate directly on 64- and 32-bit data items. It does not contain instructions that operate directly on data items that are smaller than 32 bits. As a result, if a program uses a data item that is smaller than 32 bits, the compilers generate a sequence of instructions to extract the data item from a 32-bit quantity. Thus, it consumes more system resources to access a data item that is less than 32 bits than it does to access a 32-bit or 64-bit data item.
This increase in overhead will not cause a problem if a program uses small data only occasionally. However, if a program uses small data regularly (for example, in the body of a critical loop), this overhead can be significant. For information on how to modify data declarations in your program to avoid this problem, see the Programmer's Guide.
The Alpha architecture also affects disk space and memory usage. While the 64-bit architecture benefits applications that would otherwise exhaust the address space in a 32-bit implementation, the Digital UNIX operating system implementation on Alpha systems does result in larger memory and disk space requirements than those associated with operating systems based on a 32-bit architecture. For details on the Alpha architecture, see the Alpha Architecture Reference Manual.
![[Previous Section]](PREV.GIF)
Programs that are being executed by the Digital UNIX operating system are known as processes. Each process runs within a protected virtual address space. The process abstraction is separated into two low-level abstractions, the task and the thread:
The kernel schedules threads. A process priority can be managed by the nice interface or by the real-time interface. The nice interface allows adjustments of priorities within the range 19 through -19, where 19 is the lowest priority. You can adjust real-time priorities on those systems running the real-time kernel by using the sched_setscheduler interface.
Under the Digital UNIX operating system, most applications will execute as traditional UNIX processes (that is, as a task with a single thread).
Interprocess communication (IPC) is the mechanism that facilitates the exchange of information among processes. The IPC facilities include shared memory, pipes, semaphores, and messages. The IPC facilities are described in Section 1.4.
The memory management system is responsible for distributing the available main memory space among competing processes and buffers. You have some level of control over the following components of the memory management system:
The Digital UNIX memory management components constantly interact with each other. As a result, a change in one of the components can also affect the other components. The following sections discuss each component in more detail.
The virtual memory subsystem controls the allocation of pages in
physical memory
and keeps track of the pages that have been paged out.
Specifically, the virtual memory subsystem coordinates the allocation
of resources for a task among the hardware components shown in
Table 1-1
(in the order of fastest to slowest access time).
| Resource | Description |
| CPU cache | Internal instruction and data caches (one each) that reside in the CPU chip and vary in size up to a maximum of 64KB (depending upon processor types). Also includes instruction and data translation lookaside buffers (ITLBs and DTLBs). |
| Secondary cache | Secondary direct-mapped physical data cache that is external to the CPU, but usually resides on the main processor board. Block sizes for the secondary cache vary from 32 bytes to 256 bytes (depending upon processor type). Secondary cache ranges in size from 128KB to 8MB. |
| Tertiary cache | Not available on all Alpha CPUs, and typically does not reside on main processor board. Otherwise, same as the secondary cache. |
| System memory | The actual physical memory. Size varies from 24 megabytes to 14 gigabytes. |
| Swap disk | Block special device. (Avoiding the file system saves overhead.) |
For more information on the CPU, secondary cache, and tertiary cache, see the Alpha Architecture Reference Manual.
Figure 1-1 gives an overview of how instructions and data can be moved among various storage components during the execution of a program.
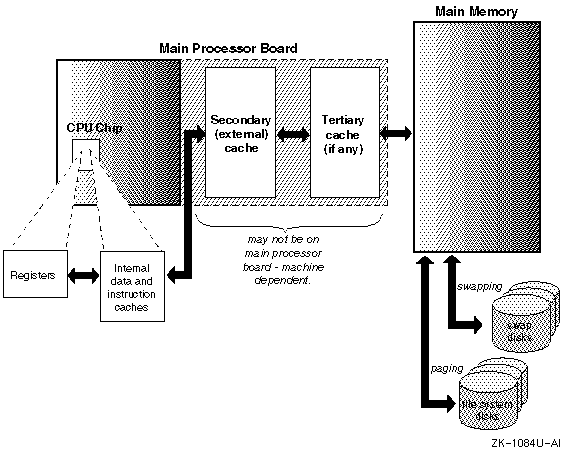
Much of the movement of addresses and data among the CPU cache, secondary and tertiary cache, and physical memory is controlled by the hardware logic and the Privileged Architecture Library (PAL) code, which is transparent to the Digital UNIX operating system. The virtual memory subsystem becomes involved when the CPU's translation buffer is unable to map a requested virtual address to a physical address and then traps to the PAL's page lookup code, which is responsible for monitoring and loading addresses from the page table into the CPU's translation buffer.
If the requested address is in the page table, the PAL lookup code loads the address into the translation buffer, which in turn passes the address to the CPU. If the address is not in the page table, the PAL code issues a virtual memory fault, which is the virtual memory subsystem's cue to locate the requested page and to load its physical address into the page table for use by the PAL lookup code:
Page-in and copy-on-write page faults are handled by the virtual memory subsystem's paging and swapping mechanism, which is described in Section 1.3.1.1.
The virtual memory subsystem attempts to keep the movement of pages as fast as possible. To do this, it tracks the utilization and the location of all pages in the memory subsystem.
The virtual memory subsystem maintains five lists to perform its tasks.
Each existing page can be found on one of the following lists:
The virtual memory subsystem tries to maintain a reasonable number of pages on the free page list so that pages are available for use by processes. All pages are shared by virtual memory and the UBC. Four configuration attributes in the sysconfigtab file define the size of the free page list and thus control when paging and swapping occur:
See Section 2.2.9 for general information on sysconfigtab configuration attributes.
Figure 1-2 shows the default values of the sysconfigtab configuration attributes that control paging and swapping.

If the number of pages on the free page list falls below the value associated with the vm-page-free-min attribute, the virtual memory subsystem first trims down the size of the UBC until the percentage associated with the ubc-borrowpercent attribute is reached. If this does not satisfy the memory deficit, it then activates two page-stealer routines that reclaim the least recently used pages from the virtual memory system's inactive list and the UBC's LRU list. This process continues until the number of pages on the free page list reaches the value associated with the vm-page-free-target attribute. If necessary, the contents of the reclaimed pages are moved to swap space.
When the maximum number of pages is reached, the page-stealer daemon becomes dormant again. This procedure enables the virtual memory subsystem to keep the most recently used pages in memory and move the least recently used pages to swap space, where they can be easily accessed if necessary.
The value associated with the vm-page-free-reserved attribute specifies the absolute minimum number of pages on the free page list. If the free page list falls below the value associated with the vm-page-free-reserved attribute, only privileged tasks can get memory, thus preventing deadlocks.
The page-stealer daemon maintains a ratio of one active page to two inactive pages. If the inactive list becomes too small, the page-stealer daemon deactivates the oldest and least recently used pages and moves them to the inactive list.
When the virtual memory subsystem maps an application into memory, it tries to anticipate which pages the task will need next. Using an algorithm that checks which pages were most recently used and the size of the free page list (as well as other factors), it passes some number of pages to the task in addition to the requested page. It tries to anticipate the pages that a task will need, thus accelerating the execution of the application by lowering the chances that a page fault will occur.
The virtual memory subsystem also attempts to optimize the utilization of the secondary cache. To do this, it uses a nontunable technique called page coloring. Essentially, it attempts to map the most recently referenced pages of a running task's virtual address space into the secondary cache and to execute the entire task, text, and data out of that cache. If the task is loaded in the secondary cache, the task does not have to fetch from physical memory and the task's execution time is decreased.
The virtual memory subsystem maintains system-wide counters for all of the physical pages that it manages. The following counters, which can be viewed with the vmstat command, track the overall use of physical memory:
See Section 2.2.3 for additional information on the vmstat command.
To determine how much memory an application uses, you can use the ps command. The ps aux command displays the virtual address size (VSZ), which is the total amount of virtual memory allocated to the process, and its resident set size (RSS), which is the total amount of physical memory mapped to virtual pages at some point in time. See Section 2.2.1 for additional information on the ps command.
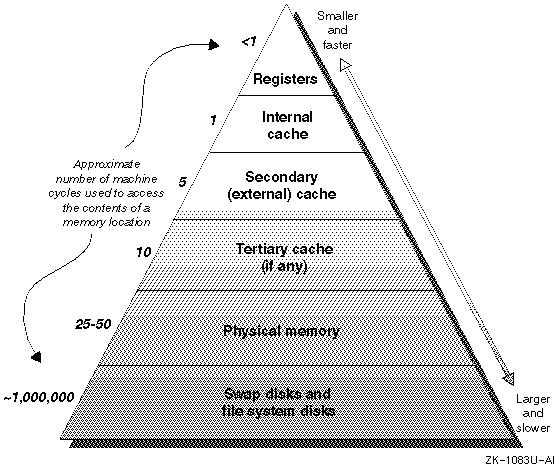
Figure 1-3 shows the amount of time that it takes to access data and instructions in memory and on disk. It illustrates the impact that excessive paging and swapping could have on the performance of an application.
Paging and swapping is the process of moving pages between memory and disk to ensure that a task has the pages in memory that it needs to run. The virtual memory subsystem controls this activity. It initiates paging and swapping activity under the following circumstances:
To perform a page in, the virtual memory subsystem allocates a physical page off the free page list, which is a linked list of available pages. When it has the address, the virtual memory subsystem fills the physical page with the contents of the page that it obtained from disk, loads the physical address into the page table, and marks the page as active.
If the number of pages in the free page list falls below the value associated with the vm-page-free-optimal attribute for more than five seconds, the task swapper (an extension of the page reclamation code) is activated. The task swapper thread suspends processes, writes to disk all of the dirtied pages associated with the suspended processes, and places those pages on the free page list.
The task swapper first swaps out all swappable tasks that have been idle for 30 seconds or more. If this does not satisfy the memory demand, it begins swapping out the lowest priority tasks with the largest resident set size, one at a time, until the memory demands are satisfied (that is, until the number of pages on the free page list reaches the value associated with the vm-page-free-target attribute).
From a performance viewpoint, swapping is worse than paging because swapped out processes can experience a long latency that is unsuitable for interactive processes. In addition, swapping can reduce system throughput. However, swapping does move long-sleeping threads out of memory and thus "cleans up" memory.
The virtual memory subsystem prewrites pages to disk under the following circumstances:
To facilitate the movement of data between memory and disk, the virtual memory subsystem uses two types of swap buffers: synchronous and asynchronous.
The virtual memory subsystem uses the two types of swap buffers in order to satisfy the immediate demands of a page-in request without having to wait for the completion of a page out, which is a relatively slow process.
How swap space is allocated is determined by two modes: immediate mode and deferred mode. The two strategies differ in the point in time at which swap space is allocated.
The Digital UNIX operating system's default swap mode is immediate mode. The operating system will reserve swap space for anonymous memory (for example, stack space, heap space, and memory allocated by the malloc or sbrk routines) when that memory is allocated. This results in more swap space being reserved than is probably required. (Note: anonymous memory is any memory that is not backed by a file; it is backed by swap space.)
You can change the swap mode to deferred (or overcommitment) mode. This causes the reservation and allocation of swap space used to back up anonymous memory to be postponed until the physical memory actually needs to be reclaimed.
Deferred mode requires less swap space than immediate mode and causes the system to run faster because less swap bookkeeping is required. However, because deferred mode does not reserve swap space in advance, the swap space may not be available when it is needed by a task and the process may be killed asynchronously. You should ensure that you have sufficient swap space if you want to use deferred mode.
Immediate swap mode is used if the /sbin/swapdefault file exists. This file is a symbolic link to /dev/rzxx, which is the first defined swap device. If this file does not exist, the system uses deferred mode. If you change from one mode to another, you must reboot the system to activate the new mode.
Refer to the manual System Administration for more information on swap space allocation modes.
The Digital UNIX operating system uses a unified buffer cache (UBC) to hold the actual file data, which includes reads and writes from conventional file activity and page faults from mapped file sections. The UBC and the virtual memory subsystem share and compete for all of main memory and utilize the same physical pages. This means that all available physical memory can be used both for buffering I/O and for the address space of the processes.
For AdvFS, the UBC contains file data and metadata. For UFS, the UBC contains only file data, and metadata (for example, file header information, blocks, directories, and inodes) is contained in the metadata buffer cache.
The UBC uses a buffer to facilitate the movement of data between memory and disk. The vm-ubcbuffers attribute specifies the number of UBC I/O requests that can be outstanding.
The UBC is dynamic, and it can potentially utilize all physical memory; thus the UBC can respond to changing file system demands. You can limit the amount of memory allocated to the UBC:
Changes in relative rates of demand can enlarge or shrink the size of the UBC. Heavy virtual memory activity, such as large increases in the working set caused by large executable files or by large amounts of uninitialized data being accessed, will increase the number of pages reserved for virtual memory and decrease the number reserved for the UBC. Conversely, heavy file system activity will increase the number of pages reserved for the UBC and decrease the number of pages reserved for virtual memory.
Interprocess communication (IPC) is the exchange of information between two or more processes. Some examples of IPC include messages, shared memory, semaphores, pipes, signals, process tracing, and processes communicating with other processes over a network. IPC is a functional interrelationship of several operating system subsystems. Elements are found in scheduling and networking.
In single-process programming, modules within a single process communicate with each other using global variables and function calls, with data passing between the functions and the callers. When programming using separate processes, with images in separate address spaces, you need to use additional communication mechanisms.
The Digital UNIX operating system provides the following facilities for interprocess communication:
The I/O subsystems involve the software and hardware that performs all reading and writing operations:
The sections that follow describe the various I/O subsystems: disk systems (Section 1.5.1), file systems (Section 1.5.3), and network systems (Section 1.5.4).
The Digital UNIX operating system supports two hardware storage architectures: Small Computer System Interface (SCSI) and Digital Storage Architecture (DSA).
All Alpha systems support SCSI devices. This support is provided through the Common Access Method (CAM) architecture. The CAM architecture defines a software model that is layered, providing hardware independence for SCSI device drivers. In the CAM model, a single SCSI/CAM peripheral driver controls SCSI devices of the same type, for example, direct access devices. This driver communicates with a device on the bus through a defined interface. Using this interface makes a SCSI/CAM peripheral device driver independent of the underlying SCSI Host Bus Adapter.
This hardware independence is achieved by using the Transport (XPT) and SCSI Interface Module (SIM) components of CAM. Because the XPT/SIM interface is defined and standardized, users and third parties can write SCSI/CAM peripheral device drivers for a variety of devices and use existing operating system support for SCSI. The drivers do not contain SCSI HBA dependencies; therefore, they can run any hardware platform that has an XPT/SIM interface present.
The Digital Storage Architecture (DSA) conforms to the Mass Storage Control Protocol (MSCP).
LSM is a disk storage management subsystem that protects against data loss and improves disk I/O performance. It also allows you to perform administrative tasks, such as performance monitoring and online disk reconfiguration.
LSM builds virtual disks, called volumes. A volume is a Digital UNIX special device that contains data used by a file system (UFS or AdvFS), a database, or other application. A volume exists transparently between a physical disk and an application. Under LSM, file system I/O operations are handled at the volume level, not the physical disk level. I/O operations involving a physical disk are handled by LSM.
Duplicate copies of file systems and databases can be set up under LSM. This capability is referred to as mirroring. Mirroring speeds up read operations and protects against data loss from disk malfunctions. (Mirroring can slightly degrade the performance of applications with more write requests than read requests because of the need to perform multiple writes in parallel to multiple disks.)
Striping can also be used under LSM to improve disk I/O performance by spreading the data within a volume across several physical disks.
The file system architecture for the Digital UNIX operating system is based on the OSF/1 Virtual File System (VFS), which is based on Berkeley 4.3 Reno VFS. VFS provides an abstract layer interface into files regardless of the file systems in which the files reside. Included in VFS is the namei cache, which stores recently used file system pathname/inode number pairs. It also stores inode information for files that were referenced but not found. Having this information in the cache substantially reduces the amount of searching that is needed to perform pathname translations. (See Section 3.6.1.1 for information on VFS tuning.)
Layered below VFS, the Digital UNIX operating system supports the following file systems:
The UFS file system uses the UBC to avoid disk I/O. Because of this, I/O accesses may appear random. The UBC shares all of memory with the virtual memory subsystem and adjusts itself dynamically to accommodate varying I/O loads. As the I/O load increases, the UBC increases to the limit defined by the ubc-maxpercent attribute. All I/O passes through the UBC and is periodically flushed to disk by the update daemon.
Laying out your file system tree across multiple disks can improve performance. The access time tends to be more important than the transfer rate for most workstation, time-share, and server environments. Access time is the seek time plus the rotational delay time, that is, the time the disk takes to access the requested block.
You can modify file system fragment sizes to optimize either I/O performance or disk space usage. Large fragment sizes optimize for I/O performance, and small fragment sizes optimize for disk space usage.
Block clustering is an important factor in UFS performance. Block clustering causes the file system and the UBC to combine multiple small I/O operations into a larger single I/O operation to disk. This results in a dramatic decrease in read/write requests to disk, which reduces kernel overhead. With clustering, I/O can nearly attain a raw device bandwidth for sequential operations.
Clusters are groups of file system blocks in a contiguous sequence. For a standard 8KB/1KB (block size/fragment size) UNIX file system, the default cluster size is 8 blocks (64KB). This is determined by multiplying the default number of blocks (8) by the block size (8192 bytes). You can modify the number of blocks that are combined into a single read request by using either the tunefs or newfs command to establish a new value for maxcontig. You can modify the number of blocks that are combined into a single write request by using dbx to establish a new value for the cluster_maxcontig global variable.
UFS tries to group contiguous writes into clusters. Individual contiguous block writes are collected into a cluster. The cluster is written asynchronously as a unit either when its full size is reached or a discontiguous block is encountered. Specifically, contiguous writes are done in 64KB units, which is the file system block size (8KB) multiplied by the default value of cluster_maxcontig.
UFS uses clusters to make read-ahead more efficient and effective as follows:
See Section 3.6.1.2 for information on how to tune read-ahead and write clusters.
A network provides a means to move data from one computer to another. This data may be no more complicated than electronic mail. You can copy files containing printable data (for example, word processor files), or binary data from a local computer to a remote computer, with the same ease as files copied from one directory to another on the local computer. With remote login, users can log in to a remote computer on which they have an account and access programs and data as if they were at a terminal connected to their own host computer.
A network consists of two essential component parts: the hardware implementation and the software that runs the network. The hardware consists of controllers and connectors.
The controller sends and receives packets of data over the network. Controllers are specialized and are designed to work with a particular type of computer (bus architecture). For example, controllers designed to work with a Digital workstation will not work with a Sun or Hewlett-Packard workstation, or an IBM-PC.
The cables or wires connecting different computers (or nodes) on a network can be twisted-pair (as with telephone wires), thick or thin Ethernet cable, or optical fiber. The type of controller determines the type of connector.
![]()
The Digital UNIX operating system supports one network software implementation by default, TCP/IP (Transmission Control Protocol/Internet Protocol). It also supports a variety of other network software implementations as layered products, for example, DECnet, PATHWORKS, and X.25. Each of these network software implementations uses its own set of protocols, which are the rules and formats that are used to conduct communications on a network. Protocols govern relationships among network nodes, polling, the exchange of control information, and the way messages are packaged, addressed, and routed.
The following list provides some general background information on TCP/IP, NFS (Network File System), and UDP (User Datagram Protocol).
NFS allows users to mount remote file systems in their own local directories, thereby giving the appearance of an extension of their local file system. The machine that offers file systems for other machines to access is called the server or file server; the machines that access these file systems by remotely mounting them are called clients.
NFS, however, is not a network extension of UNIX and does not adhere to UNIX semantics. It does not support all UNIX file system operations, cannot obtain access to remote devices (that is, files and file systems can be operated on, but not the physical devices on which they reside), and does not guarantee atomic operations. It operates independently of the machine and operating system and can be used on non-UNIX machines as well as those running UNIX.
UDP is similar to TCP and it provides a mechanism for user applications to communicate with IP. UDP differs from TCP in that it is a simple protocol that is entirely dependent upon IP to provide reliability. UDP does not guarantee delivery, occasionally generates duplicate data packets, and may send data in the incorrect order. However, layers above UDP can create reliable services using UDP.
Both the host (client) and remote (server) machines start network daemon processes running when they are booted. Machines that can be reached from the network are listed in a data file with their network addresses. Each local machine knows its own name and network address. As data is sent out over the network, the address and routing information are filled in by the sending network daemon. Network daemons on receiving machines decode the address to determine for whom the message is intended. If the message is intended for the receiving machine, it decodes the message and processes it; otherwise, it does nothing.