You may be able to improve Tru64 UNIX performance by optimizing your memory resources. This chapter describes how to perform the following tasks:
Understand how the operating system allocates memory to processes and to file system caches and how memory is reclaimed (Section 6.1)
Configure swap space for high performance (Section 6.2)
Obtain information about memory performance and consumption (Section 6.3)
Provide more memory resources to processes (Section 6.4)
Modify paging and swapping operation (Section 6.5)
Reserve physical memory for shared memory (Section 6.6)
The operating system allocates physical memory in 8-KB units called pages. The virtual memory subsystem tracks and manages all the physical pages in the system and efficiently distributes the pages among three areas:
Static wired memory
Allocated at boot time and used for operating system data and text and for system tables, static wired memory is also used by the metadata buffer cache, which holds recently accessed UNIX File System (UFS) and CD-ROM File System (CDFS) metadata.
You can reduce the amount of static wired memory only by removing subsystems or by decreasing the size of the metadata buffer cache (see Section 6.1.2.1).
Dynamically wired memory
Allocated at boot time and used for dynamically allocated data structures, such as address space wired by user processes, the amount of dynamically wired memory varies according to the demand, but is limited, by default, to 80 percent of physical memory.
You can reduce the amount of dynamically wired memory by reducing the
value of the
vm
subsystem attribute
vm-syswiredpercent, or by allocating more kernel resources to processes
(for example, by increasing the value of the
maxusers
attribute).
See
Section 5.1
and
Section 6.4.3.
Virtual memory
Used for processes' most-recently accessed anonymous memory (modifiable virtual address space) and file-backed memory (memory that is used for program text or shared libraries). Virtual memory is also allocated to the Unified Buffer Cache (UBC), which caches most-recently accessed UFS file system data for reads and writes and for page faults from mapped file regions, in addition to AdvFS metadata and file data.
Processes and the UBC compete for a limited about of physical memory, and the virtual memory subsystem allocates physical pages according to the process and file system demand. To be able to meet the demands of competing claims on memory resources, the virtual memory subsystem periodically reclaims the oldest pages by writing their contents to swap space. Under heavy loads, entire processes may be suspended (swapped out) to free memory.
You can control virtual memory allocation and operation by tuning
various
vm
subsystem attributes, as described in
Section 6.1.2
and
Section 6.5.
You must understand memory operation to determine which tuning recommendations will improve performance for your workload. The following sections describe how the virtual memory subsystem:
Tracks physical pages (Section 6.1.1)
Allocates memory to file system buffer caches (Section 6.1.2)
Allocates memory to processes (Section 6.1.3)
Reclaims pages (Section 6.1.4)
The virtual memory subsystem tracks all the physical pages of memory in the system. Page lists are used to identify the location and age of all the physical memory pages. The oldest pages are the first to be reclaimed. At any one time, each physical page can be found on one of the following lists:
Free list--Pages that are clean and are not being used
Page reclamation begins when the size of the free list decreases to a tunable limit.
Active list--Pages that are currently being used by processes or the UBC
To determine which active pages should be reclaimed first, the page-stealer daemon identifies the oldest pages on the active list. Inactive pages are the oldest pages that are being used by processes. UBC LRU (least-recently used) pages are the oldest pages that are being used by the UBC.
Use the
vmstat
command to determine the number of pages that are on the page lists.
Remember
that pages on the active list (the
act
field in the
vmstat
output) include both inactive and UBC LRU pages.
The operating system uses three caches to store file system user data and metadata. If the cached data is later reused, a disk I/O operation is avoided, which improves performance. This is because memory access is faster than disk access.
The following sections describe these file system caches:
Metadata buffer cache (Section 6.1.2.1)
Unified Buffer Cache (Section 6.1.2.2)
AdvFS buffer cache (Section 6.1.2.3)
At boot time, the kernel allocates wired memory for the metadata buffer cache. The cache acts as a layer between the operating system and disk by storing recently accessed UFS and CDFS metadata, which includes file header information, superblocks, inodes, indirect blocks, directory blocks, and cylinder group summaries. Performance is improved if the data is later reused and a disk operation is avoided.
The metadata buffer cache uses
bcopy
routines to
move data in and out of memory.
Memory in the metadata buffer cache
is not subject to page reclamation.
The size of the metadata buffer cache is specified by the value of the
vfs
subsystem attribute
bufcache.
See
Section 9.4.3.1
for tuning information.
After the kernel wires memory at boot time, the remaining memory is available to processes and to the Unified Buffer Cache (UBC), which compete for this memory.
The UBC functions as a layer between the operating system and disk by temporarily holding recently accessed UFS file system data for reads and writes from conventional file activity and holding page faults from mapped file sections. The UBC also holds AdvFS metadata, which it wires so that the transaction log is written to disk before metadata, and AdvFS file data. Performance is improved if the data in the UBC is later reused and a disk I/O operation is avoided.
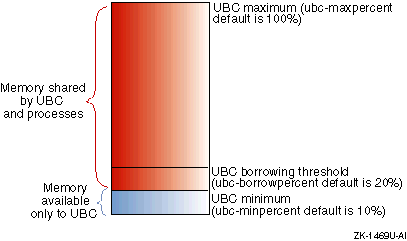
Figure 6-1 shows how the virtual memory subsystem allocates physical memory to the UBC and for processes.
The amount of memory that the UBC can utilize is determined by three
vm
subsystem attributes:
Specifies the minimum percentage of virtual memory that only the UBC can utilize. The remaining memory is shared with processes. The default is 10 percent.
Specifies the maximum percentage of virtual memory that the UBC can utilize. The default is 100 percent.
ubc-borrowpercent
attribute
Specifies the UBC borrowing threshold.
The default is 20 percent.
From
the value of the
ubc-borrowpercent
attribute to the value
of the
ubc-maxpercent
attribute, the UBC is only borrowing
virtual
memory from processes.
When paging starts, pages are first reclaimed from
the UBC until the amount of memory allocated to the UBC decreases to the value
of the
ubc-borrowpercent
attribute.
At any one time, the amount of virtual memory allocated to the UBC and to processes depends on the file system and process demands. For example, if file system activity is heavy and process demand is low, most of the pages will be allocated to the UBC, as shown in Figure 6-2.
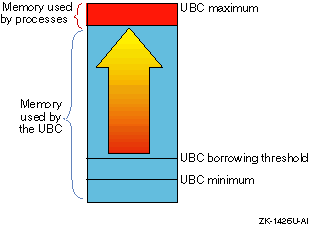
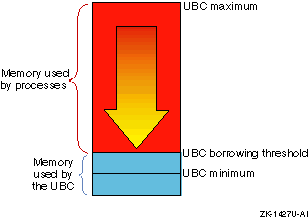
In contrast, heavy process activity, such as large increases in the
working sets for large executables, will cause the virtual memory subsystem
to reclaim UBC borrowed pages, down to the value of the
ubc-borrowpercent
attribute, as shown in
Figure 6-3.
The UBC uses a hashed list to quickly locate the physical pages that it is holding. A hash table contains file and offset information that is used to speed lookup operations.
The
UBC also uses a buffer to facilitate the movement of data between memory and
disk.
The
vm
subsystem attribute
vm-ubcbuffers
specifies maximum file system device I/O queue depth for writes
(that is, the number of UBC I/O requests that can be outstanding).
See
Section 9.2.6
for tuning information.
The AdvFS buffer cache is part of the UBC and acts as a layer between the operating system and disk by storing recently accessed AdvFS file system data, including file system reads and writes. Performance is improved if the cached data is later reused and a disk operation is avoided.
At boot time, the kernel determines the amount of physical memory that is available for AdvFS buffer cache headers, and allocates a buffer cache header for each possible page. Buffer headers are maintained in a global array and temporarily assigned a buffer handle that refers to an actual buffer page.
The number of AdvFS buffer cache headers depends on the number of 8-KB
pages that can be obtained from the amount of memory specified by the
advfs
subsystem attribute
AdvfsCacheMaxPercent.
The default value is 7 percent of physical memory.
In addition, the
AdvFS buffer cache cannot be more than 50 percent of the UBC.
The AdvFS buffer cache is organized as a fixed-size hash chain table, which uses a file page offset, fileset handle, and domain handle to calculate the hash key that is used to look up a page.
When a page of data is requested, AdvFS searches the hash chain table for a match. If the entry is already in memory, AdvFS returns the buffer handle and a pointer to the page of data to the requester.
If no entry is found, AdvFS obtains a free buffer header and initializes it to represent the requested page. AdvFS performs a read operation to obtain the page from disk and attaches the buffer header to a UBC page. The UBC page is then wired into memory. AdvFS buffer cache pages remain wired until the buffer needs to be recycled, the file is deleted, or the fileset is unmounted.
See Section 6.4.5, and Section 9.3.4.1, and Section 9.3.4.2 for information about tuning the AdvFS buffer cache.
After the kernel wires memory at boot time, the remaining memory is available to processes and the UBC, which compete for this memory. The virtual memory subsystem allocates memory resources to processes and to the UBC according to the demand, and reclaims the oldest pages if the demand depletes the number of available free pages.
The following sections describe how the virtual memory subsystem allocates memory to processes.
The
fork
system call creates new processes.
When
you invoke a process, the
fork
system call:
Creates a UNIX process body, which includes a set of data
structures that the kernel uses to track the process and a set of resource
limitations.
See
fork(2)
for more information.
Allocates a contiguous block of virtual address space to the process. Virtual address space is the array of virtual pages that the process can use to map into actual physical memory. Virtual address space is used for anonymous memory (memory that holds data elements and structures that are modified during process execution) and for file-backed memory (memory used for program text or shared libraries).
Because physical memory is limited, a process' entire virtual address space cannot be in physical memory at one time. However, a process can execute when only a portion of its virtual address space (its working set) is mapped to physical memory. Pages of anonymous memory and file-backed memory are paged in only when needed. If the memory demand increases and pages must be reclaimed, the pages of anonymous memory are paged out and their contents moved to swap space, while the pages of file-backed memory are simply released.
Creates one or more threads of execution. The default is one thread for each process. Multiprocessing systems support multiple process threads.
Although the virtual memory subsystem allocates a large amount of virtual address space for each process, it uses only part of this space. Only 4 TB is allocated for user space. User space is generally private and maps to a nonshared physical page. An additional 4 TB of virtual address space is used for kernel space. Kernel space usually maps to shared physical pages. The remaining space is not used for any purpose.
Figure 6-4 shows the use of process virtual address space.

In addition, user space is sparsely populated
with valid pages.
Only valid pages are able to map to physical pages.
The
vm
subsystem attribute
vm-maxvas
specifies the maximum amount of valid virtual address space for a process
(that is, the sum of all the valid pages).
The default is 128000 pages (1
GB).
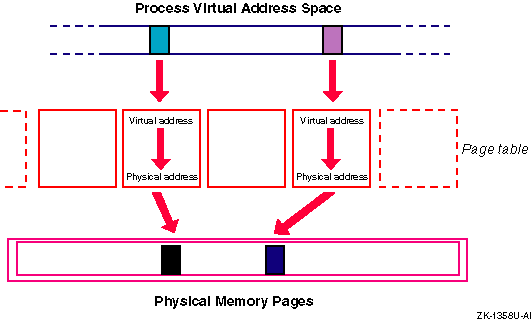
When a virtual page is touched (accessed), the virtual memory subsystem must locate the physical page and then translate the virtual address into a physical address. Each process has a page table, which is an array containing an entry for each current virtual-to-physical address translation. Page table entries have a direct relation to virtual pages (that is, virtual address 1 corresponds to page table entry 1) and contain a pointer to the physical page and protection information.
Figure 6-5 shows the translation of a virtual address into a physical address.
A process resident set is the complete set of all the virtual addresses that have been mapped to physical addresses (that is, all the pages that have been accessed during process execution). Resident set pages may be shared among multiple processes.
A process working set is the set of virtual addresses that are currently mapped to physical addresses. The working set is a subset of the resident set and represents a snapshot of the process resident set at one point in time.
When an anonymous (nonfile-backed) virtual address is requested, the virtual memory subsystem must locate the physical page and make it available to the process. This occurs at different speeds, depending on whether the page is in memory or on disk (see Figure 1-1).
If a requested address is currently being used (that is, the address is in the active page list), it will have an entry in the page table. In this case, the PAL code loads the physical address into the translation lookaside buffer, which then passes the address to the CPU. Because this is a memory operation, it occurs quickly.
If a requested address is not active in the page table, the PAL lookup code issues a page fault, which instructs the virtual memory subsystem to locate the page and make the virtual-to-physical address translation in the page table.
There are different types of page faults:
If a requested virtual address is being accessed for the first time, a zero-filled-on-demand page fault occurs. The virtual memory subsystem performs the following tasks:
Allocates an available page of physical memory.
Fills the page with zeros.
Enters the virtual-to-physical address translation in the page table.
If a requested virtual address has already been accessed and is located in the memory subsystem's internal data structures, a short page fault occurs. For example, if the physical address is located in the hash queue list or the page queue list, the virtual memory subsystem passes the address to the CPU and enters the virtual-to-physical address translation in the page table. This occurs quickly because it is a memory operation.
If a requested virtual address has already been accessed, but the physical page has been reclaimed, the page contents will be found in swap space and a page-in page fault occurs.
The virtual memory subsystem copies the contents of the page from swap space into the physical address and enters the virtual-to-physical address translation in the page table. Because this requires a disk I/O operation, it requires more time than a memory operation.
If a process needs to modify a read-only virtual page, a copy-on-write page fault occurs. The virtual memory subsystem allocates an available page of physical memory, copies the read-only page into the new page, and enters the translation in the page table.
The virtual memory subsystem uses several techniques to improve process execution time and decrease the number of page faults:
Mapping additional pages
The virtual memory subsystem attempts to anticipate which pages the task will need next. Using an algorithm that checks which pages were most recently used, the number of available pages, and other factors, the subsystem maps additional pages along with the page that contains the requested address.
If possible, the virtual memory subsystem maps a process' entire resident set into the secondary cache and executes the entire task, text, and data within the cache.
The
vm
subsystem attribute
private-cache-percent
specifies the
percentage of the secondary cache that is reserved for anonymous memory and
can be used for benchmarking.
The default is to reserve 50 percent of the
cache for anonymous memory and 50 percent for file-backed memory (shared).
To cache more anonymous memory, increase the value of the
private-cache-percent
attribute.
Because memory resources are limited, the virtual memory subsystem must periodically reclaim pages. The free page list contains clean pages that are available to processes and the UBC. As the demand for memory increases, the list may become depleted. If the number of pages falls below a tunable limit, the virtual memory subsystem will reclaim the least-recently used pages from processes and the UBC to replenish the free list.
To reclaim pages, the virtual memory subsystem:
Prewrites modified pages to swap space, in an attempt to forestall a memory shortage. See Section 6.1.4.1 for more information.
Begins paging if the demand for memory is not satisfied, as follows:
Reclaims pages that the UBC has borrowed and puts them on the free list.
Reclaims the oldest inactive and UBC LRU pages from the active page list, moves the contents of the modified pages to swap space, and puts the clean pages on the free list.
More aggressively reclaims pages from the active list, if needed.
See Section 6.1.4.2 for more information about paging.
Begins swapping if the demand for memory is not met. The virtual memory subsystem temporarily suspends processes and moves entire resident sets to swap space, which frees large numbers of pages. See Section 6.1.4.3 for information about swapping.
The point at which paging and swapping start and stop depends
on the values of some
vm
subsystem attributes.
Figure 6-6
shows the default values of these attributes.
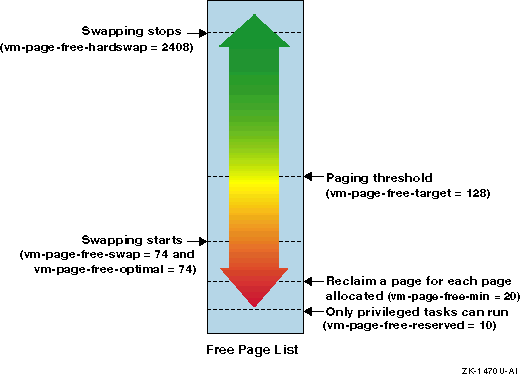
Detailed descriptions of the attributes are as follows:
vm-page-free-target--Paging starts when the number of pages
on the free list is less than this value.
Paging stops when the number of
pages is equal to or more than this value.
The default is 128 pages.
vm-page-free-min--Specifies the threshold at which a page must be reclaimed
for each page allocated (the default is 20 pages).
vm-page-free-swap--Idle task swapping starts when the number
of pages on the free list is less than this value for a period of time (the
default is 74 pages).
vm-page-free-optimal--Hard swapping starts when the number
of pages on the free list is less than this value for five seconds (the default
is 74 pages).
The first processes to be swapped out include those with the
lowest scheduling priority and those with the largest resident set size.
vm-page-free-hardswap--Swapping stops when the number of pages
on the free list is equal to or
more than this value (the default is 2048 pages).
vm-page-free-reserved--Only privileged tasks can get memory
when the number of pages on the free list is less than this value (the default
is 10 pages).
See Section 6.5 for information about modifying paging and swapping attributes.
The following sections describe the page reclamation procedure in detail.
The virtual memory subsystem attempts to prevent a memory shortage by prewriting modified pages to swap space.
When
the virtual memory subsystem anticipates that the pages on the free list
will soon be depleted, it prewrites to swap space the oldest modified (dirty)
inactive pages.
The value of the
vm
subsystem
attribute
vm-page-prewrite-target
determines the number
of pages
that the subsystem will prewrite and keep clean.
The default value is 256
pages.
In addition, when the
number of modified UBC LRU pages exceeds the value of the
vm
subsystem attribute
vm-ubcdirtypercent, the virtual
memory subsystem prewrites to swap space the oldest modified UBC LRU pages.
The default value of the
vm-ubcdirtypercent
attribute
is 10 percent of the total UBC LRU pages.
To minimize the impact of
sync
(steady state flushes)
when prewriting UBC pages, the
vm
subsystem
attribute
ubc-maxdirtywrites
specifies the maximum number
of disk
writes that the kernel can perform each second.
The default value is 5.
See Section 6.5.2 for information about modifying dirty page prewriting.
When the
memory demand is high and the number of pages on the free page list falls
below the value of the
vm
subsystem attribute
vm-page-free-target, the virtual memory subsystem uses
paging to replenish the free page list.
The page-out daemon and task swapper
daemon are extensions of the page reclamation code, which controls paging
and swapping.
The paging process is as follows:
The page reclamation code activates the page-stealer
daemon, which first reclaims the pages that the UBC has borrowed from the
virtual memory subsystem, until the size of the UBC reaches the borrowing
threshold that is specified by the value of the
ubc-borrowpercent
attribute (the default is 20 percent).
Freeing borrowed UBC pages
is a
fast way to reclaim pages, because UBC pages are usually not modified.
If
the reclaimed pages are dirty (modified), their contents must be
written to disk before the pages can be moved to the free page list.
If freeing UBC borrowed memory does not sufficiently replenish the free list, a pageout occurs. The page-stealer daemon reclaims the oldest inactive and UBC LRU pages from the active page list, moves the contents of the modified pages to swap space, and puts the clean pages on the free list.
Paging becomes increasingly aggressive if the number of free
pages continues to decrease.
If the number of pages on the free page list
falls below the value of the
vm
subsystem
attribute
vm-page-free-min
(the default is 20 pages),
a page must
be reclaimed for each page taken from the list.
Figure 6-7 shows the movement of pages during paging operations.
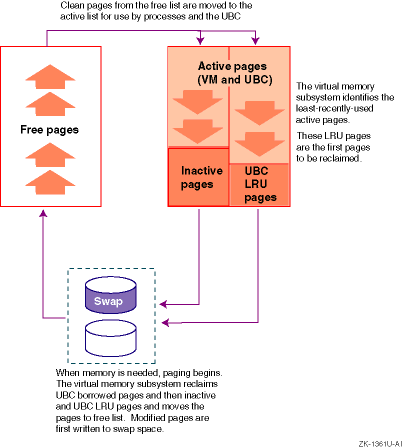
Paging stops when the number of pages on the free list increases to
the limit specified by the
vm
subsystem attribute
vm-page-free-target.
However, if paging individual pages does not
sufficiently
replenish the free list, swapping is used to free a large amount of memory
(see
Section 6.1.4.3).
If there is a continuously high demand for memory, the virtual memory subsystem may be unable to replenish the free page list by reclaiming single pages. To dramatically increase the number of clean pages, the virtual memory subsystem uses swapping to suspend processes, which reduces the demand for physical memory.
The task swapper will swap out a process by suspending the process, writing its resident set to swap space, and moving the clean pages to the free page list. Swapping has a serious impact on system performance because a swapped out process cannot execute, and should be avoided on VLM systems and systems running large programs.
The point at which swapping starts and stops is controlled by a number
of
vm
subsystem attributes, as follows:
Idle task swapping
begins
when the number of pages on the free list falls below the value of the
vm-page-free-swap
attribute for a period of time (the default is
74 pages).
The task swapper suspends all tasks that have been idle for 30
seconds or more.
Hard task swapping
begins when the
number of pages on the free page list falls below the value of the
vm-page-free-optimal
attribute (the default is 74 pages) for more
than five seconds.
The task swapper suspends, one at a time, the tasks with
the lowest priority and the largest resident set size.
Swapping stops
when the number of pages on the free list increases to the value of
the
vm-page-free-hardswap
attribute (the default is 2048).
A
swapin
occurs when the number of
pages on the free list increases to the value of the
vm-page-free-optimal
attribute for a period of time.
The
task's working set is paged
in from swap space and it can now execute.
The value of the
vm-inswappedmin
attribute specifies the minimum amount of time, in seconds, that
a task must remain in the inswapped state before it can be outswapped.
The
default value is 1 second.
You may be able to improve system performance by modifying the attributes that control when swapping starts and stops, as described in Section 6.5. Large-memory systems or systems running large programs should avoid paging and swapping, if possible.
Increasing the rate of swapping (swapping earlier during page reclamation) may increase throughput. As more processes are swapped out, fewer processes are actually executing and more work is done. Although increasing the rate of swapping moves long-sleeping threads out of memory and frees memory, it may degrade interactive response time because when an outswapped process is needed, it will have a long latency period.
Decreasing the rate of swapping (by swapping later during page reclamation) may improve interactive response time, but at the cost of throughput. See Section 6.5.1 for more information about changing the rate of swapping.
To facilitate the movement of data between memory and disk, the virtual memory subsystem uses synchronous and asynchronous swap buffers. The virtual memory subsystem uses these two types of buffers to immediately satisfy a page-in request without having to wait for the completion of a page-out request, which is a relatively slow process.
Synchronous swap buffers are used for page-in page faults and for swap outs. Asynchronous swap buffers are used for asynchronous pageouts and for prewriting modified pages. See Section 6.5.4 and Section 6.5.5 for swap buffer tuning information.
Use the
swapon
command to display swap space, and to configure additional
swap space after system installation.
To make this
additional swap space permanent, you must specify the swap file entry
in the
/etc/fstab
file.
See Section 2.3.2.2 and Section 2.3.2.3 for information about swap space allocation modes and swap space requirements.
The following list describes how to configure swap space for high performance:
Ensure that all your swap devices are configured when you boot the system, instead of adding swap space while the system is running.
Use fast disks for swap space to decrease page-fault latency.
Use disks that are not busy for swap space.
Use the
iostat
command to determine which disks are not being used.
Spread out swap space across multiple disks; do not put multiple swap partitions on the same disk. This makes paging and swapping more efficient and helps to prevent any single adapter, disk, or bus from becoming a bottleneck. The page reclamation code uses a form of disk striping (known as swap space interleaving) that improves performance when data is written to multiple disks.
Spread out your swap disks across multiple I/O buses to prevent a single bus from becoming a bottleneck.
Use the Logical Storage Manager (LSM) to stripe your swap disks.
Use RAID 1 (mirroring) or RAID 5 for swap disks to provide data availability if a failure occurs. Mirroring may degrade performance for configurations that are paging heavily, because this increases the write load on the swap disks.
See the System Administration manual for more information about adding swap devices. See Chapter 8 for more information about configuring and tuning disks for high performance and availability.
Table 6-1 describes the tools that you can use to gather information about memory usage.
| Name | Use | Description |
|
Analyzes system configuration and displays statistics (Section 4.2) |
Creates an HTML file that describes
the system configuration, and can be used to diagnose problems.
The
The
|
Displays total system memory |
Use the
|
|
Displays virtual memory and CPU usage statistics (Section 6.3.2) |
Displays information about process threads, virtual memory usage (page lists, page faults, pageins, and pageouts), interrupts, and CPU usage (percentages of user, system and idle times). First reported are the statistics since boot time; subsequent reports are the statistics since a specified interval of time. |
|
|
Displays CPU and virtual memory usage by processes (Section 6.3.1) |
Displays current statistics for running processes, including CPU usage, the processor and processor set, and the scheduling priority. The
|
Displays IPC statistics |
Displays interprocess communication (IPC) statistics for currently active message queues, shared-memory segments, semaphores, remote queues, and local queue headers. The information
provided in the following fields reported by the
|
|
|
Displays information about swap space utilization (Section 6.3.3) |
Displays the total amount of allocated
swap space, swap space in use, and free swap space, and also displays this
information for each swap device.
You can also use the
|
Reports virtual memory and UBC statistics (Section 6.3.4 and Section 6.3.5) |
You can check virtual memory by using
the
|
|
Exercises system memory |
Exercises memory by running a number
of processes.
You can specify the amount of memory to exercise, the number
of processes to run, and a file for diagnostic output.
Errors are written
to a log file.
See
|
|
Exercises shared memory |
Exercises shared memory segments by
running a
You can
specify the number of memory segments to test, the size of the segment, and
a file for diagnostic output.
Errors are written to a log file.
See
|
The following sections describe some of these tools in detail.
The
ps
command displays the current status of the system
processes.
You can use it to determine the current running processes (including
users), their state, and how they utilize system memory.
The command lists
processes in order of decreasing CPU usage, so you can identify which processes
are using the most CPU time.
The
ps
command provides only a snapshot of the system;
by the time the command finishes executing, the system state has probably
changed.
In addition, one of the first lines of the command may refer to
the
ps
command itself.
An example of the
ps
command is as follows:
#/usr/ucb/ps auxUSER PID %CPU %MEM VSZ RSS TTY S STARTED TIME COMMAND chen 2225 5.0 0.3 1.35M 256K p9 U 13:24:58 0:00.36 cp /vmunix /tmp root 2236 3.0 0.5 1.59M 456K p9 R + 13:33:21 0:00.08 ps aux sorn 2226 1.0 0.6 2.75M 552K p9 S + 13:25:01 0:00.05 vi met.ps root 347 1.0 4.0 9.58M 3.72 ?? S Nov 07 01:26:44 /usr/bin/X11/X -a root 1905 1.0 1.1 6.10M 1.01 ?? R 16:55:16 0:24.79 /usr/bin/X11/dxpa mat 2228 0.0 0.5 1.82M 504K p5 S + 13:25:03 0:00.02 more mat 2202 0.0 0.5 2.03M 456K p5 S 13:14:14 0:00.23 -csh (csh) root 0 0.0 12.7 356M 11.9 ?? R < Nov 07 3-17:26:13 [kernel idle] [1] [2] [3] [4] [5] [6] [7]
The
ps
command output includes the following information
that you can use to diagnose CPU and virtual memory problems:
Percentage of CPU time usage (%CPU).
[Return to example]
Percentage of real memory usage (%MEM).
[Return to example]
Process virtual address size (VSZ)--This
is the total amount of virtual memory allocated to the process (in bytes).
[Return to example]
Real memory (resident set) size of the process
(RSS)--This is the total amount of physical memory
(in bytes) mapped to virtual pages (that is, the total amount of memory that
the application has physically used).
Shared memory is included in the resident
set size figures; as a result, the total of these figures may exceed the total
amount of physical memory available on the system.
[Return to example]
Process status or state (S)--This specifies
whether a process is in one of the following states:
Runnable (R)
Uninterruptible sleeping (U)
Sleeping (S)
Idle (I)
Stopped (T)
Halted (H)
Swapped out (W)
Has exceeded the soft limit on memory requirements (>)
A process group leader with a controlling terminal (+)
Has a reduced priority (N)
Has a raised priority (<)
Current CPU time used (TIME), in the format
hh:mm:ss.ms.
[Return to example]
The command that is running (COMMAND).
[Return to example]
From the output of the
ps
command, you can determine
which processes are consuming most of your system's CPU time and memory resources
and whether processes are swapped out.
Concentrate on processes that are
running or paging.
Here are some concerns to keep in mind:
If a process is using a large amount of memory (see the
RSS
and
VSZ
fields), the process may have excessive
memory requirements.
See
Section 11.2
for information about
decreasing an application's use of memory.
Are duplicate processes running? Use the
kill
command to terminate any unnecessary processes.
See
kill(1)
for more information.
If a process is using a large amount of CPU time, it may be
in an infinite loop.
You may have to use the
kill
command
to terminate the process and then correct the problem by making changes to
its source code.
You can also use the Class Scheduler to allocate a percentage of CPU
time to a specific task or application (see
Section 7.2.2)
or lower the process' priority by using either the
nice
or
renice
command.
These commands have no effect on memory
usage by a process.
See
nice(8)
or
renice(8)
for more information.
Check the processes that are swapped out.
Examine the
S
(state) field.
A
W
entry indicates a process
that has been swapped out.
If processes are continually being swapped out,
this could indicate a lack of memory resources.
See
Section 6.4
for information.
The
vmstat
command shows
the virtual memory, process, and CPU statistics for a specified time interval.
The first line of the output is for all time since a reboot, and each subsequent
report is for the last interval.
Invoke the
vmstat
command when the system is idle
and also when the system is busy to compare the resulting data.
You can use
the
memx
memory exerciser to put a load on the memory subsystem.
An example of the
vmstat
command is as follows;
output is provided in one-second intervals:
#/usr/ucb/vmstat 1Virtual Memory Statistics: (pagesize = 8192) procs memory pages intr cpu r w u act free wire fault cow zero react pin pout in sy cs us sy id 2 66 25 6417 3497 1570 155K 38K 50K 0 46K 0 4 290 165 0 2 98 4 65 24 6421 3493 1570 120 9 81 0 8 0 585 865 335 37 16 48 2 66 25 6421 3493 1570 69 0 69 0 0 0 570 968 368 8 22 69 4 65 24 6421 3493 1570 69 0 69 0 0 0 554 768 370 2 14 84 4 65 24 6421 3493 1570 69 0 69 0 0 0 865 1K 404 4 20 76 [1] [2] [3] [4]
The
vmstat
command includes information that you
can use to diagnose CPU and virtual memory problems.
The following fields
are particularly important:
Virtual memory information (memory):
the number of pages that are on the active list, including inactive pages
and UBC LRU pages (act); the number of pages on the free
list (free), and the number of pages on the wired list
(wire).
Pages on the wired list cannot be reclaimed.
See
Section 6.1.1
for more information on page lists.
[Return to example]
The
number of pages that have been paged out (pout).
[Return to example]
Interrupt information (intr),
including the number of nonclock device interrupts per second (in), the number of system calls called per second (sy),
and the number of task and thread context switches per second (cs).
[Return to example]
CPU usage information (cpu), including the
percentage of user time for normal and priority processes (us),
the percentage of system time (sy), and the percentage
of idle time (id).
User time includes the time the CPU
spent executing library routines.
System time includes the time the CPU spent
executing system calls.
[Return to example]
To use the
vmstat
command to diagnose a performance
problem:
Check the size of the free page list (free).
Compare the number of free pages to the values for the active pages (act) and the wired pages (wire).
The sum of the
free, active, and wired pages should be close to the amount of physical memory
in your system.
Although the value for
free
should be
small, if the value is consistently small (less than 128 pages) and accompanied
by excessive paging and swapping, you may not have enough physical memory
for your workload.
See
Section 6.4
for information
about increasing memory resources.
Examine
the
pout
field.
If the number of pageouts is consistently
high, you may have insufficient memory.
See
Section 6.4
for information about increasing memory resources.
You also may have insufficient swap space or your swap space may be
configured inefficiently.
Use the
swapon -s
command to
display your swap device configuration, and use the
iostat
command to determine which swap disk is being used the most.
See
Section 2.3.2.3
for information about configuring swap space.
Check the user (us), system (sy), and idle (id) time split.
You must understand
how your applications use the system to determine the appropriate values
for these times.
The goal is to keep the CPU as productive as possible.
Idle CPU cycles occur when no runnable processes exist or when the CPU is
waiting to complete an I/O or memory request.
The following list describes how to interpret the values for user, idle, and system time:
Idle time--A high percentage of idle time on one or more processors indicates either:
Threads are blocked because the CPU is waiting for some event or resource (for example, memory or I/O)
Threads are idle because the CPU is not busy
If you have a high idle time and poor response time, and you are sure that your system has a typical load, one or more of the following problems may exist:
The hardware may have reached its capacity
One or more kernel data structures is being exhausted
You may have a hardware or kernel resource problem such as an application, disk I/O, or network bottleneck
If the idle time percentage is very low but performance is acceptable, your system is utilizing its CPU efficiently.
User time--A high percentage of user time can be a characteristic of a well-performing system. However, if the system has poor performance, a high percentage of user time may indicate a user code bottleneck, which can be caused by inefficient user code, insufficient processing power, or excessive memory latency or cache missing.
Use profiling to determine which sections of code consume the most processing time. See Section 11.1 and the Programmer's Guide for more information on profiling.
A high percentage of user time and a low percentage of idle time may indicate that your application code is consuming most of the CPU. You can optimize the application, or you may need a more powerful processor. See Section 7.2 for information on optimizing CPU resources.
System time--A high percentage of system time may indicate a system bottleneck, which can be caused by excessive system calls, device interrupts, context switches, soft page faults, lock contention, or cache missing.
A high percentage of system time and a low percentage of idle time
may indicate that something in the application load is stimulating the system
with high overhead operations.
Such overhead operations could consist of high
system call frequencies, high interrupt rates, large numbers of small I/O
transfers, or large numbers of IPCs or network transfers.
A high system time
and low idle time may be caused by failing hardware.
Use the
uerf
command to check your hardware.
A high percentage of system time may also indicate that the system is thrashing; that is, the amount of memory available to the virtual memory subsystem has gotten so low that the system is spending all its time paging and swapping in an attempt to regain memory. A system that spends more than 50 percent of its time in system mode and idle mode may be doing a lot of paging and swapping I/O, and therefore may not have enough memory resources. See Section 6.4 for information about increasing memory resources.
If you have excessive page-in and page-out activity from a swap partition, the system may have a high physical memory commitment ratio. Excessive paging also can increase the miss rate for the secondary cache, and may be indicated by the following output:
The output of the
ps
command shows high
task swapping activity.
See
Section 6.3.1
for more information.
The output of the
vmstat
shows a very
low free page count or shows high page-in and page-out activity.
The output of the
swapon
command shows
excessive use of swap space.
See
Section 6.3.3
for
more information.
The following command output may indicate that the size of the UBC is too small for your configuration:
The output of the
vmstat
or
monitor
command shows excessive file system page in activity, but little
or no page out activity or shows a very low free page count.
The output of the
iostat
command shows
little or no swap disk I/O activity or shows excessive file system I/O activity.
See
Section 8.2.1
for more information.
Use the
swapon -s
command to display your swap device configuration.
For each swap partition,
the command displays the total amount of allocated swap space, the amount
of swap space that is being used, and the amount of free swap space.
This
information can help you determine how your swap space is being utilized.
An example of the
swapon
command is as follows:
#/usr/sbin/swapon -sSwap partition /dev/rz1b (default swap): Allocated space: 16384 pages (128MB) In-use space: 10452 pages ( 63%) Free space: 5932 pages ( 36%) Swap partition /dev/rz4a: Allocated space: 128178 pages (1001MB) In-use space: 10242 pages ( 7%) Free space: 117936 pages ( 92%) Total swap allocation: Allocated space: 144562 pages (1.10GB) Reserved space: 34253 pages ( 23%) In-use space: 20694 pages ( 14%) Available space: 110309 pages ( 76%)
You can configure swap space when you first install the operating system, or you can add swap space at a later date. Application messages, such as the following, usually indicate that not enough swap space is configured into the system or that a process limit has been reached:
lack of paging space" swap space below 10 percent free"
See Section 2.3.2.3 for information about swap space requirements. See Section 6.2 for information about adding swap space and distributing swap space for high performance.
You
can check virtual memory by using the
dbx print
command
to examine the
vm_perfsum
data structure.
For example:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)print vm_perfsumstruct { vpf_pagefaults = 10079073 vpf_kpagefaults = 103387 vpf_cowfaults = 2696851 vpf_cowsteals = 840487 . . . vpf_allocatedpages = 7030 vpf_vmwiredpages = 485 vpf_ubcwiredpages = 0 vpf_mallocpages = 924 vpf_totalptepages = 307 vpf_contigpages = 7 vpf_rmwiredpages = 0 vpf_ubcpages = 3211 vpf_freepages = 128 vpf_vmcleanpages = 256 vpf_swapspace = 7879 } (dbx)
Important fields in the previous example include the following:
vpf_pagefaults--Number of hardware
page faults
vpf_swapspace--Number of pages of
swap space not reserved
vpf_freepages--Number of pages on
the free list
To obtain additional information about the current
use of memory, use the
dbx print
command to display the
values of the following kernel variables:
vm_page_active_count--Number of pages
on the active list
vm_page_inactive_count--Number of
inactive pages
ubc_lru_page_count--Number of UBC
LRU pages
For example:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)print vm_page_active_count708
See Chapter 6 for information on managing memory resources.
The Unified Buffer Cache (UBC) is flushed by the
update
daemon.
You can monitor the UBC usage lookup hit ratio by using
the
dbx print
command to examine the
vm_perfsum,
ufs_getapage_stats, and
vm_tune
data structures.
The following example shows part of the
vm_perfsum
data structure:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)print vm_perfsumstruct { vpf_pagefaults = 10079139 vpf_kpagefaults = 103387 vpf_cowfaults = 2696861 vpf_cowsteals = 840499 vpf_zfod = 2332612 vpf_kzfod = 103217 vpf_pgiowrites = 28526 . . . vpf_ubcalloc = 678788 vpf_ubcpagepushes = 51 vpf_ubcdirtywra = 8 vpf_ubcreclaim = 0 vpf_ubcpagesteal = 330624 vpf_ubclookups = 7880454 vpf_ubclookuphits = 7472308 vpf_allocatedpages = 7030 vpf_vmwiredpages = 489 vpf_ubcwiredpages = 0 vpf_mallocpages = 924 vpf_totalptepages = 319 vpf_contigpages = 7 vpf_rmwiredpages = 0 vpf_ubcpages = 3179 vpf_freepages = 128 vpf_vmcleanpages = 256 vpf_swapspace = 7877 } (dbx)
Important fields include the following:
The
vpf_pgiowrites
field specifies the
number of I/O operations for pageouts generated by the page stealing daemon.
The
vpf_ubcalloc
field specifies the number
of times the UBC had to allocate a page from the virtual memory free page
list to satisfy memory demands.
The
vpf_ubcpages
field specifies the number
of pages of physical memory that the UBC is using to cache file data.
If
the UBC is using significantly more than half of the physical memory and the
paging rate is high (vpf_pgiowrites
field), you may want
to reduce the amount of memory available to the UBC by decreasing the value
of the
ubc-maxpercent
attribute.
See
Section 6.4.4
for information.
The
vpf_ubclookuphits
field specifies the
UBC hit rate.
You can also monitor the UBC by using the
dbx print
command to examine the
ufs_getapage_stats
data
structure.
For example:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)print ufs_getapage_statsstruct { read_looks = 2059022 read_hits = 2022488 read_miss = 36506 } (dbx)
To calculate the hit rate, divide the value of the
read_hits
field by the value of the
read_looks
field.
A good hit rate is a rate above 95 percent.
In the previous example, the
hit rate is approximately 98 percent.
You can also check the UBC by using the
dbx print
command to examine the
vm_tune
data
structure.
For example:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)print vm_tunestruct { vt_cowfaults = 4 vt_mapentries = 200 vt_maxvas = 1073741824 vt_maxwire = 16777216 vt_heappercent = 7 vt_anonklshift = 17 vt_anonklpages = 1 vt_vpagemax = 16384 vt_segmentation = 1 vt_ubcpagesteal = 24 vt_ubcdirtypercent = 10 vt_ubcseqstartpercent = 50 vt_ubcseqpercent = 10 vt_csubmapsize = 1048576 vt_ubcbuffers = 256 vt_syncswapbuffers = 128 vt_asyncswapbuffers = 4 vt_clustermap = 1048576 vt_clustersize = 65536 vt_zone_size = 0 vt_kentry_zone_size = 16777216 vt_syswiredpercent = 80 vt_inswappedmin = 1 } (dbx)
Important fields include the
vt_ubcseqpercent
and
vt_ubcseqstartpercent
fields.
The values of these fields
are used to prevent a large file from completely filling the UBC, which limits
the amount of memory available to processes.
When copying large files, the source and destination objects in the
UBC will grow very large (up to all of the available physical memory).
Reducing
the value of the
vm-ubcseqpercent
attribute decreases
the number of UBC pages that will be used to cache a large sequentially accessed
file.
The value represents the percentage of UBC memory that a sequentially
accessed file can consume before it starts reusing UBC memory.
The value imposes
a resident set size limit on a file.
See
Section 9.2.7
for
more information.
If you have insufficient memory for process execution, you may be able to increase the memory that is available to processes by tuning various kernel subsystem attributes. Some of the recommendations for increasing the memory available to processes may impact UBC operation and file system caching.
Table 6-2 shows the recommendations for increasing memory resources to processes and lists the performance benefits as well as tradeoffs.
| Recommendation | Performance Benefit | Tradeoff |
| Reduce the number of processes running at the same time (Section 6.4.1) | Decreases CPU load and demand for memory | System performs less work |
| Reduce the static size of the kernel (Section 6.4.2) | Decreases demand for memory | Not all functionality may be available |
| Reduce dynamically wired memory (Section 6.4.3) | Decreases demand for memory | None |
| Reduce the amount of physical memory available to the UBC (Section 6.4.4) | Provides more memory resources to processes | May degrade file system performance |
| Decrease the size of the AdvFS buffer cache (Section 6.4.5) | Provides more memory resources to processes | May degrade AdvFS performance on systems that open and reuse files |
| Decrease the size of the metadata buffer cache (Section 6.4.6) | Provides more memory resources to processes | May degrade UFS performance on small systems |
| Decrease the size of the namei cache (Section 6.4.7) | Decreases demand for memory | May slow lookup operations and degrade file system performance |
| Increase the percentage of memory reserved for kernel allocations (Section 6.4.8) | Enables large database programs to run | Applicable only to large database applications |
| Reduce process memory requirements (Section 11.2.6) | Decreases demand for memory | Program may not run optimally |
The following sections describe the recommendations that will increase the memory available to processes in detail.
You can improve performance and reduce the demand for memory by running
fewer applications simultaneously.
Use the
at
or the
batch
command to run applications at offpeak hours.
See
at(1)
for more information.
You
can reduce the static size of the kernel by deconfiguring any unnecessary
subsystems.
Use the
sysconfig
command to display the configured
subsystems and to delete subsystems.
Be sure not to remove any subsystems
or functionality that is vital to your environment.
See Section 4.4 for information about modifying kernel subsystem attributes.
You can reduce
the amount of
dynamically wired memory by reducing the
value of the
vm
subsystem attribute
vm-syswiredpercent.
The default value is 80 percent.
You can also reduce dynamically wired memory by allocating
more kernel resources to processes
(for example, by increasing the value of the
proc
subsystem attribute
maxusers).
See
Section 5.1
for information.
See Section 4.4 for information about modifying kernel subsystem attributes.
The UBC and processes compete for the memory that is not wired by the kernel. You may be able to improve process performance by reducing the percentage of virtual memory that is available for the UBC. This will increase the amount of memory available to processes, which may reduce the paging and swapping rate.
Reducing the memory allocated to the UBC may adversely affect I/O performance because the UBC will hold less file system data, which results in more disk I/O operations. Therefore, do not significantly decrease the maximum size of the UBC.
The
maximum amount of virtual memory that can be allocated to the UBC
is specified by the
vm
subsystem attribute
ubc-maxpercent.
The default is 100 percent.
The minimum amount of memory that can be allocated to the UBC is specified
by the
vm
subsystem attribute
ubc-minpercent.
The default is 10
percent.
These default values are appropriate for most configurations,
including Internet servers.
Use the
vmstat
command
to determine whether the system
is paging excessively.
Use the
dbx print
command to
periodically examine the
vm_perfsum
data structure,
especially the
vpf_pgiowrites
and
vpf_ubcalloc
fields.
The page-out rate may shrink if pageouts greatly exceed
UBC allocations.
If the page out
rate is high and you are not using the file system heavily, decreasing
the value of the
ubc-maxpercent
attribute may reduce
the rate of paging and swapping.
Start with the default value
of 100 percent and decrease the value in increments of 10.
If the values of the
ubc-maxpercent
and
ubc-minpercent
attributes are close together, you may
seriously degrade I/O performance or cause the system to page excessively.
You also may be able to prevent
paging by increasing the percentage of memory that the UBC borrows from the
virtual memory subsystem.
To do this, decrease the value of the
ubc-borrowpercent
attribute so that less memory remains in the
UBC when page reclamation begins.
Although this can reduce the UBC
effectiveness, it may improve the system response time when memory is low.
The value of the
ubc-borrowpercent
attribute can range
from 0 to 100.
The default value is 20 percent.
See Section 4.4 for information about modifying kernel subsystem attributes.
To free memory resources, you may want to decrease the
amount of memory allocated to the AdvFS buffer cache.
Decreasing the cache
size also decreases the overhead associated with managing the cache.
The
advfs
subsystem attribute
AdvfsCacheMaxPercent
determines the maximum amount of memory that can be
used for the AdvFS buffer cache.
The default is 7 percent of physical memory.
The minimum is 1 percent, and the maximum is 30 percent.
If you are not using AdvFS or if you do not reuse many files, decrease the cache size to 1 percent. If you are using AdvFS, but you have a VLM system, you may also want to decrease the cache size.
However, decreasing the size of the AdvFS buffer cache may adversely affect AdvFS I/O performance if you access and then reuse many files.
See Section 4.4 for information about modifying kernel subsystem attributes.
The metadata buffer cache contains recently accessed UFS and CDFS metadata. If you have a high cache hit rate, you may want to decrease the size of the metadata buffer cache. This will increase the amount of memory that is available to the virtual memory subsystem. However, decreasing the size of the cache may degrade UFS performance.
The
vfs
subsystem attribute
bufcache
specifies
the percentage of physical memory that the kernel wires for the metadata buffer
cache.
The default size of the metadata buffer cache is 3 percent of physical
memory.
You can decrease the value of the
bufcache
attribute
to a minimum of 1 percent.
For VLM systems and
systems that use only AdvFS, set the value of the
bufcache
attribute to 1 percent.
See Section 4.4 for information about modifying kernel subsystem attributes.
The namei cache is used by all file systems to map
file pathnames to inodes.
Monitor the cache by using the
dbx print
command to examine the
nchstats
data structure.
To free memory resources,
decrease the number of elements in the namei cache by decreasing the value
of the
vfs
subsystem attribute
name-cache-size.
The default value is 2*nvnode*11/10.
The maximum value is 2*max-vnodes*11/10.
Make sure that decreasing the size of the namei cache does not degrade file system performance.
See Section 4.4 for information about modifying kernel subsystem attributes.
If you are running a large database application, you may receive the following console message:
malloc_wait:X : no space in map.
If you receive this message, you may want to increase the size of the
kernel
malloc
map by increasing the percentage of physical
memory reserved for kernel memory allocations that are less than or equal
to the page size (8 KB).
To do this, increase the value of the
generic
subsystem attribute
kmemreserve-percent.
The default value of the
kmemreserve-percent
attribute
is 0, which means that the percentage of reserved physical memory will
be 0.4 percent of available memory or 256, whichever is the smallest value.
Increase the value of the
kmemreserve-percent
attribute
by increments of 25 until the message no longer appears.
In
addition, you may want to increase the value of the
kmemreserve-percent
attribute if the output
of the
vmstat
command shows dropped packets under the
fail_nowait
heading.
This may
occur under a heavy network load.
See Section 4.4 for information about modifying kernel subsystem attributes.
You may be able to improve performance by modifying paging and swapping operations. VLM systems should avoid paging and swapping.
Table 6-3 describes the recommendations for controlling paging and swapping and lists the performance benefits and any tradeoffs.
| Action | Performance Benefit | Tradeoff |
| Increase the rate of swapping (Section 6.5.1) | Increases process throughput | Decreases interactive response performance |
| Decrease the rate of swapping (Section 6.5.1) | Improves process interactive response performance | Decreases process throughput |
| Increase the rate of dirty page prewriting (Section 6.5.2) | Prevents drastic performance degradation when memory is exhausted | Decreases peak workload performance |
| Decrease the rate of dirty page prewriting (Section 6.5.2) | Improves peak workload performance | May cause drastic performance degradation when memory is exhausted |
| Increase the size of the page-in and page-out clusters (Section 6.5.3) | Improves peak workload performance | Decreases total system workload performance |
| Decrease the size of the page-in and page-out clusters (Section 6.5.3) | Improves total system workload performance | Decreases peak workload performance |
| Increase the swap device I/O queue depth for pageins and swapouts (Section 6.5.4) | Increases overall system throughput | Consumes memory |
| Decrease the swap device I/O queue depth for pageins and swapouts (Section 6.5.4) | Improves the interactive response time and frees memory | Decreases system throughput |
| Increase the swap device I/O queue depth for pageouts (Section 6.5.5) | Frees memory and increases throughput | Decreases interactive response performance |
| Decrease the swap device I/O queue depth for pageouts (Section 6.5.5) | Improves interactive response time | Consumes memory |
| Increase the paging threshold (Section 6.5.6) | Maintains performance when free memory is exhausted | May waste memory |
| Enable aggressive swapping (Section 6.5.7) | Improves system throughput | Degrades interactive response performance |
The following sections describe the recommendations for controlling paging and swapping in detail.
Swapping has a drastic impact on system performance. You can modify kernel subsystem attributes to control when swapping begins and ends. VLM systems and systems running large programs should avoid swapping.
Increasing the rate of swapping (swapping earlier during page reclamation), moves long-sleeping threads out of memory, frees memory, and increases throughput. As more processes are swapped out, fewer processes are actually executing and more work is done. However, when an outswapped process is needed, it will have a long latency, so increasing the rate of swapping will degrade interactive response time.
To
increase the rate of swapping, increase the value of the
vm
subsystem attribute
vm-page-free-optimal
(the default is 74 pages).
Increase the value only by 2 pages at a time.
Do not specify a value
that is more than the value of the
vm
subsystem attribute
vm-page-free-target.
If you decrease the rate of swapping (swap later during
page reclamation), you will improve interactive response time, but
at the cost of throughput.
To decrease the rate of swapping, decrease the
value of the
vm-page-free-optimal
attribute by 2 pages at a time.
Do not specify a value that is less than the value of the
vm
subsystem attribute
vm-page-free-min
(the default is 20).
See Section 4.4 for information about modifying kernel subsystem attributes.
The virtual memory subsystem attempts to prevent a memory shortage by prewriting modified pages to swap space. When the virtual memory subsystem anticipates that the pages on the free list will soon be depleted, it prewrites to swap space the oldest modified (dirty) pages on the inactive list. To reclaim a page that has been prewritten, the virtual memory subsystem only needs to validate the page.
Increasing the rate of dirty page prewriting will reduce peak workload performance, but it will prevent a drastic performance degradation when memory is exhausted. Decreasing the rate will improve peak workload performance, but it will cause a drastic performance degradation when memory is exhausted.
You can control the rate of dirty page prewriting by modifying the
values of the
vm
subsystem attributes
vm-page-prewrite-target
and
vm-ubcdirtypercent.
The
vm-page-prewrite-target
attribute
specifies the number of virtual memory pages that the subsystem will prewrite
and keep clean.
The default value is 256 pages.
To increase the rate of virtual memory dirty page prewriting, increase the
value of the
vm-page-prewrite-target
attribute from
the default value (256) by increments of 64 pages.
The
vm-ubcdirtypercent
attribute specifies the percentage
of UBC LRU pages that can be modified before the virtual memory subsystem
prewrites the dirty UBC LRU pages.
The default value is
10 percent of the total UBC LRU pages (that is, 10 percent of the UBC LRU
pages must be dirty before the UBC LRU pages are prewritten).
To increase the rate of UBC LRU dirty page prewriting, decrease the value
of
the
vm-ubcdirtypercent
attribute by increments of 1 percent.
In
addition, you may want to minimize the impact of I/O spikes caused by the
sync
function when prewriting UBC LRU dirty pages.
The value of the
vm
subsystem attribute
ubc-maxdirtywrites
specifies the
maximum number of disk writes that the kernel can perform each second.
The default value of the
ubc-maxdirtywrites
attribute
is five I/O operations per second.
To minimize the impact of
sync
(steady state flushes)
when prewriting dirty UBC LRU pages, increase the value
of the
ubc-maxdirtywrites
attribute.
See Section 4.4 for information about modifying kernel subsystem attributes.
The virtual memory subsystem reads in and writes out additional pages in an attempt to anticipate pages that it will need.
The
vm
subsystem attribute
vm-max-rdpgio-kluster
specifies the
maximum size of an anonymous page-in cluster.
The default value is 16 KB
(2 pages).
If you increase the value of this attribute, the system will spend
less time page faulting because more pages will be in memory.
This will increase
the peak workload performance, but will consume more memory and decrease
the total system workload performance.
Decreasing the value of the
vm-max-rdpgio-kluster
attribute will conserve memory and increase the total system workload performance,
but will increase paging and decrease the peak workload performance.
The
vm
subsystem attribute
vm-max-wrpgio-kluster
specifies the maximum size of an
anonymous page-out cluster.
The default value is 32 KB (4 pages).
Increasing
the value of this attribute improves the peak workload performance and conserves
memory, but causes more pageins and decreases the total system workload performance.
Decreasing the value of the
vm-max-wrpgio-kluster
attribute improves the total system workload performance and decreases the
number of pageins, but decreases the peak workload performance and consumes
more memory.
See Section 4.4 for information about modifying kernel subsystem attributes.
Synchronous swap buffers
are used for page-in page faults and
for swapouts.
The
vm
subsystem attribute
vm-syncswapbuffers
specifies
the maximum swap device I/O queue depth for pageins and swapouts.
The value should be equal to the approximate number of simultaneously
running processes that the system can easily handle.
The default is 128.
Increasing the swap device I/O queue depth increases overall system throughput, but it consumes memory.
Decreasing the swap device I/O queue depth decreases memory demands and improves interactive response time, but it decreases overall system throughput.
See Section 4.4 for information about modifying kernel subsystem attributes.
Asynchronous
swap buffers are used for asynchronous pageouts and for
prewriting modified pages.
The
vm
subsystem
attribute
vm-asyncswapbuffers
controls the
maximum depth of the swap device I/O queue for pageouts.
The value of the
vm-asyncswapbuffers
attribute
should be the approximate number of I/O transfers
that a swap device can handle at one time.
The default value is 4.
Increasing the queue depth will free memory and increase the overall system throughput.
Decreasing the queue depth will use more memory, but it will improve the interactive response time.
If you are using LSM, you may want to increase the page-out rate.
Be careful if you increase the value of the
vm-asyncswapbuffers
attribute, because this will cause page-in requests to lag
asynchronous page-out requests.
See Section 4.4 for information about modifying kernel subsystem attributes.
The
vm
subsystem attribute
vm-page-free-target
specifies the minimum
number of pages on the free list before paging starts.
The default
value is 128 pages.
If you have sufficient memory resources, you may want to increase the
value of the
vm-page-free-target
attribute.
Increasing the paging threshold will increase
paging activity, but it may improve performance when free memory is exhausted.
However, an excessively high value can waste memory.
If you want to
increase the value of the
vm-page-free-target
attribute, start at the default value and then double the value.
If you have up to
1 GB of memory, you may want to use a value of 256.
If you have up to
4 GB of memory, you may want to use a value of 768.
Do not specify a value that is more than 1024 pages or 8 MB.
Do not decrease the value of the
vm-page-free-target
attribute unless you have a lot of memory, or unless you experience a serious
performance degradation when free memory is exhausted.
See Section 4.4 for information about modifying kernel subsystem attributes.
You
can enable the
vm
subsystem attribute
vm-aggressive-swap
(set the value
to 1) to allow the virtual memory subsystem to aggressively swap out processes
when memory is needed.
This improves system throughput, but it degrades the
interactive response performance.
By default, the
vm-aggressive-swap
attribute is disabled (set
to 0), which results in less aggressive swapping.
In this case,
processes are swapped in at a faster rate than if aggressive swapping is
enabled.
See Section 4.4 for information about modifying kernel subsystem attributes.
Granularity hints allow you to reserve a portion of dynamically wired physical memory at boot time for shared memory. This functionality allows the translation lookaside buffer to map more than a single page and enables shared page table entry functionality, which will cause fewer buffer misses.
On typical database servers, using granularity hints provides a 2 to 4 percent run-time performance gain that reduces the shared memory detach time. In most cases, use the Segmented Shared Memory (SSM) functionality (the default) instead of the granularity hints functionality.
To
enable granularity hints, you must specify a value for the
vm
subsystem attribute
gh-chunks.
In addition, to
make granularity
hints more effective, modify applications to ensure that both the shared
memory segment starting address and size are
aligned on an 8-MB boundary.
Section 6.6.1 and Section 6.6.2 describe how to enable granularity hints.
To use granularity hints, you must specify the number of 4-MB chunks of physical memory to reserve for shared memory at boot time. This memory cannot be used for any other purpose and cannot be returned to the system or reclaimed.
To reserve memory for shared memory, specify a nonzero value for the
gh-chunks
attribute.
For example, if you want to reserve
4 GB of memory, specify 1024 for the value of
gh-chunks
(1024 * 4 MB = 4 GB).
If you specify a value of 512, you will reserve
2 GB of memory.
The value you specify for the
gh-chunks
attribute
depends on your database application.
Do not reserve an excessive
amount of memory, because this decreases the memory available
to processes and the UBC.
Note
If you enable granularity hints, disable the use of segmented shared memory by setting the value of the
ipcsubsystem attributessm-thresholdattribute to zero.
You can determine if you have reserved the appropriate amount of memory.
For example, you can initially specify 512 for the value of the
gh-chunks
attribute.
Then, invoke the
following sequence of
dbx
commands while running the
application that allocates shared memory:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)px &gh_free_counts0xfffffc0000681748(dbx)0xfffffc0000681748/4Xfffffc0000681748: 0000000000000402 0000000000000004 fffffc0000681758: 0000000000000000 0000000000000002 (dbx)
The previous output shows the following:
The first number (402) specifies the number of 512-page chunks (4 MB).
The second number (4) specifies the number of 64-page chunks.
The third number (0) specifies the number of 8-page chunks.
The fourth number (2) specifies the number of 1-page chunks.
To save memory, you can reduce the value of the
gh-chunks
attribute until only one or two 512-page chunks are free while the application
that uses shared memory is running.
The following
vm
subsystem
attributes also affect granularity hints:
Specifies the shared memory segment size above which memory is allocated
from the memory reserved by the
gh-chunks
attribute.
The
default is 8 MB.
When set to 1 (the default), the
shmget
function
returns a failure if the requested segment size is larger than the value
specified by the
gh-min-seg-size
attribute, and if there
is insufficient memory in the
gh-chunks
area to satisfy
the request.
If the value of the
gh-fail-if-no-mem
attribute is
0, the entire request will be satisfied from the pageable memory area if the
request is larger than the amount of memory reserved by the
gh-chunks
attribute.
In addition, messages will display on the system console indicating unaligned size and attach address requests. The unaligned attach messages are limited to one per shared memory segment.
See Section 4.4 for information about modifying kernel subsystem attributes.
You can make granularity hints more effective by making both the shared memory segment starting address and size aligned on an 8-MB boundary.
To share Level 3 page table entries, the shared memory segment attach
address (specified by the
shmat
function) and the shared
memory segment size (specified by the
shmget
function)
must be aligned on an 8-MB boundary.
This means that the lowest 23 bits
of both the address and the size must be zero.
The attach address and the shared memory segment size is specified
by the application.
In addition, System V shared memory semantics allow a
maximum shared memory segment size of 2 GB minus 1 byte.
Applications that
need shared memory segments larger than 2 GB can construct these regions by
using multiple segments.
In this case, the total shared memory size specified
by the user to the application must be 8-MB aligned.
In addition, the value
of the
shm-max
attribute, which specifies the maximum size
of a System V shared memory segment, must be 8-MB aligned.
If the total shared memory size specified to the application is greater
than 2 GB, you can specify a value of 2139095040 (or 0x7f800000) for the
value of the
shm-max
attribute.
This is the maximum value
(2 GB minus 8 MB) that you can specify for the
shm-max
attribute and still share page table entries.
Use the following
dbx
command sequence to determine
if page table entries are being shared:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)p *(vm_granhint_stats *)&gh_stats_storestruct { total_mappers = 21 shared_mappers = 21 unshared_mappers = 0 total_unmappers = 21 shared_unmappers = 21 unshared_unmappers = 0 unaligned_mappers = 0 access_violations = 0 unaligned_size_requests = 0 unaligned_attachers = 0 wired_bypass = 0 wired_returns = 0 } (dbx)
For the best performance, the
shared_mappers
kernel variable should be equal to the number of shared memory segments,
and the
unshared_mappers,
unaligned_attachers, and
unaligned_size_requests
variables should
be zero.
Because of how shared memory is divided into shared memory
segments, there may be some unshared segments.
This occurs when the
starting address or the size is aligned on an 8-MB boundary.
This condition may be unavoidable in some cases.
In many cases, the
value of
total_unmappers
will be greater than
the value of
total_mappers.
Shared memory locking changes a lock that was a single lock into a hashed
array of locks.
The size of the hashed array of locks can be modified by
modifying the value of the
vm
subsystem attribute
vm-page-lock-count.
The default value is zero.