![[Return to Library]](BOOKSHELF.GIF)
![[Contents]](TOC.GIF)
![[Previous Chapter]](REW.GIF)
![[Next Section]](NEXT.GIF)
![[Next Chapter]](FF.GIF)
![[Index]](INDEX.GIF)
![[Help]](HELP.GIF)
![]()
This chapter suggests performance priorities and guidelines for use with LSM. It also provides information about monitoring LSM and gathering performance data.
![]()
Achieving optimal performance by balancing input/output (I/O) load among several disks on a system without LSM may be limited because it is difficult to anticipate future disk usage patterns, and it is not always possible to split file systems across drives. For example, if a single file system receives most of the disk accesses, placing that file system on another drive moves the bottleneck to another drive.
LSM provides flexibility in configuring storage to improve system performance. Table 15-1 describes two basic strategies available to optimize performance.
| Strategy | Result |
| Assign data to physical drives to evenly balance the I/O load among the available disk drives | Achieves a finer level of granularity in data placement because LSM provides a way for volumes to be split across multiple drives. After measuring actual data-access patterns, you can adjust file system placement decisions. Volumes can be reconfigured online after performance patterns have been established or have changed, without adversely impacting volume availability. |
| Identify the most-frequently accessed data and increase access bandwidth to that data through the use of mirroring and striping | Achieves a significant improvement in performance when there are multiple I/O streams. If you can identify the most heavily-accessed file systems and databases, then you can realize significant performance benefits by striping the high traffic data across portions of multiple disks, and thereby increasing access bandwidth to this data. Mirroring heavily-accessed data not only protects the data from loss due to disk failure, but in many cases also improves I/O performance. |
![[Previous Section]](PREV.GIF)
The use of mirroring to store multiple copies of data on a system improves the chance of data recovery in the event of a system crash or disk failure, and in some cases can be used to improve system performance. However, mirroring degrades write performance slightly. On most systems, data access patterns conform to the 80/20 concept: Twenty percent of the data is accessed 80 percent of the time, and the other 80 percent of the data is accessed 20 percent of the time.
The following sections describe some guidelines for configuring mirrored disks, improving mirrored system performance, and using block-change logging to speed up the recovery of mirrored volumes.
When properly applied, mirroring can provide continuous data availability by protecting against data loss due to physical media failure. Use the following guidelines when using mirroring:
Note
The Digital UNIX operating system implements a file system cache. Because read requests frequently can be satisfied from this cache, the read/write ratio for physical I/O's through the file system can be significantly more biased toward writing than the read/write ratio at the application level.
Mirroring can also improve system performance. Unlike striping, however, performance gained through the use of mirroring depends on the read/write ratio of the disk accesses. If the system workload is primarily write-intensive (for example, greater than 70 percent writes), then mirroring can result in somewhat reduced performance.
Because mirroring is most often used to protect against loss of data due to drive failures, it may be necessary to use mirroring for write-intensive workloads. In these instances, combine mirroring with striping to deliver both high availability and performance.
To provide optimal performance for different types of mirrored volumes,
LSM supports the read policies shown in
Table 15-2.
| Policy | Description |
| Round-robin read | Satisfies read requests to the volume in a round-robin manner from all plexes in the volume |
| Preferred read | Satisfies read requests from one specific plex (presumably the plex with the highest performance) |
For example, in the configuration shown in Figure 15-1, the read policy of the volumes labeled Hot Vol should be set to the preferred read policy from the striped mirror labeled PL1. In this way, reads going to PL1 distribute the load across a number of otherwise lightly used disk drives, as opposed to a single disk drive.
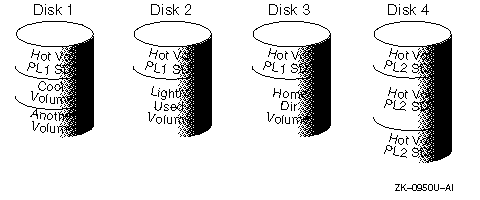
To improve performance for read-intensive workloads, up to eight plexes can be attached to the same volume, although this scenario results in a decrease of effective disk space use. Performance can also be improved by striping across half of the available disks to form one plex and across the other half to form another plex.
LSM block-change logging keeps track of the blocks that have changed as a result of writes to a mirror. Block-change logging does this by identifying the block number of changed blocks, and storing this number in a log subdisk. Block-change logging can significantly speed up recovery of mirrored volumes following a system crash.
Note
Using block-change logging can significantly decrease system performance in a write-intensive environment.
Logging subdisks are one-block long subdisks that are defined for and added to a mirror that is to become part of a volume that has block-change logging enabled. They are ignored as far as the usual mirror policies are concerned and are only used to hold the block-change log.
Follow these guidelines when using block-change logging:
Striping can improve serial access when I/O exactly fits across all subdisks in one stripe. Better throughput is achieved because parallel I/O streams can operate concurrently on separate devices.
The following sections describe how to use striping as a way of slicing data and storing it across multiple devices to improve access bandwidth for a mirror.
Follow these guidelines when using striping:
The volassist command automatically adopts many of these rules when it allocates space for striped plexes in a volume.
Striping can provide increased access bandwidth for a plex. Striped plexes exhibit improved access performance for both read and write operations. Where possible, disks attached to different controllers should be used to further increase parallelism.
One disadvantage of striping is that some configuration changes are harder to perform on striped plexes than on concatenated plexes. For example, it is not possible to move an individual subdisk of a striped plex, or to extend the size of a striped plex, except by creating a completely new plex and removing the old striped plex. This can be done with the volassist move command or the volplex mv command.
While these operations can be performed on concatenated plexes without copying through a plex, striping offers the advantage that load balancing can be achieved in a much simpler manner.
Figure 15-2 is an example of a single file system that has been identified as a data-access bottleneck. This file system was striped across four disks, leaving the remainder of those four disks free for use by less-heavily used file systems.
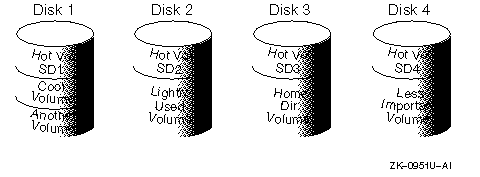
Simple performance experiments can be run to determine the appropriate configuration for a striped plex. The configuration changes can be done while the data is online. For example, the stripe width or nstripe of a striped plex can be modified to determine the optimal values. Similarly, data can be moved from a "hot" disk to a "cold" disk.
The following example gives the steps required to change the stripe width of a plex P1 from 64 kilobytes (the default) to 32 kilobytes.
#
volmake sd sd3 rz10,0,102400
#
volmake sd sd4 rz11,0,102400
#
volmake plex pl2 layout=stripe stwidth=32 sd=sd3,sd4
#
volplex mv pl1 pl2
This command will take some time to complete.
When adding LSM volumes to AdvFS domains, Digital recommends the addition of multiple simple volumes rather than a single, large, striped or concatenated volume. This type of configuration enables AdvFS to take advantage of multiple storage containers in an AdvFS domain by sorting and balancing the I/O across all the storage containers in the domain.
The following sections suggest ways to prioritize your performance requirements, and how to obtain and use performance data and recorded statistics to help you gain the performance benefits provided by LSM.
Table 15-3 describes the two sets of performance priorities for a system administrator.
| Priority | Description |
| Physical (hardware) | Addresses the balance of the I/O on each drive and the concentration of the I/O within a drive to minimize seek time. Based on monitored results, it may be necessary to move subdisks around to balance the disks. |
| Logical (software) | Involves software operations and how they are managed. Based on monitoring, certain volumes may be mirrored (multiple plexes) or striped to improve their performance. Overall throughput may be sacrificed to improve the performance of critical volumes. Only you can decide what is important on a system and what tradeoffs make sense. |
LSM records the following three I/O statistics:
LSM records these statistics for logical I/Os for each volume. The statistics are recorded for the following types of operations: reads, writes, atomic copies, verified reads, verified writes, mirror reads, and mirror writes.
For example, one write to a two-mirror volume will result in the following statistics being updated:
Similarly, one read that spans two subdisks results in the following statistics being updated: -- one read for each subdisk, one for the mirror, and one for the volume.
LSM also maintains other statistical data. For example, read and write failures that appear for each mirror, and corrected read and write failures for each volume accompany the read and write failures that are recorded.
LSM provides two types of performance information -- I/O statistics and I/O traces:
Each type of performance information can help in performance monitoring. The following sections briefly discuss these utilities.
The volstat utility provides access to information for activity on volumes, plexes, subdisks, and disks under LSM control. The volstat utility reports statistics that reflect the activity levels of LSM objects since boot time. Statistics for a specific LSM object or all objects can be displayed at one time. A disk group can also be specified, in which case statistics for objects in that disk group only are displayed; if you do not specify a particular disk group on the volstat command line, statistics for the default disk group (rootdg) are displayed.
The amount of information displayed depends on what options are specified to volstat. For detailed information on available options, refer to the volstat(8) reference page.
The volstat utility is also capable of resetting the statistics information to zero. This can be done for all objects or for only those objects that are specified. Resetting just prior to a particular operation makes it possible to measure the impact of that particular operation afterwards.
The following example shows typical output from a volstat display:
OPERATIONS BLOCKS AVG TIME(ms)
TYP NAME READ WRITE READ WRITE READ WRITE
vol blop 0 0 0 0 0.0 0.0
vol foobarvol 0 0 0 0 0.0 0.0
vol rootvol 73017 181735 718528 1114227 26.8 27.9
vol swapvol 13197 20252 105569 162009 25.8 397.0
vol testvol 0 0 0 0 0.0 0.0
The voltrace command is used to trace operations on volumes. Through the voltrace utility, you can set I/O tracing masks against a group of volumes or to the system as a whole. You can then use the voltrace utility to display ongoing I/O operations relative to the masks.
The trace records for each physical I/O show a volume and buffer-pointer combination that enables you to track each operation even though the traces may be interspersed with other operations. Like the I/O statistics for a volume, the I/O trace statistics include records for each physical I/O done, and a logical record that summarizes all physical records. For additional information, refer to the voltrace(8) reference page.
Once performance data has been gathered, you can use the data to determine an optimum system configuration that makes the most efficient use of system resources. The following sections provide an overview of how you can use I/O statistics and I/O tracing.
Examination of the I/O statistics may suggest reconfiguration. There are two primary statistics to look at: volume I/O activity and disk I/O activity. The following steps describes how to record and examine I/O statistics:
#
volstat -r
When monitoring a system that is used for multiple purposes, try not to exercise any application more than it would be exercised under typical circumstances. When monitoring a time-sharing system with many users, try to let the I/O statistics accumulate during typical usage for several hours during the day.
OPERATIONS BLOCKS AVG TIME(ms)
TYP NAME READ WRITE READ WRITE READ WRITE
vol archive 865 807 5722 3809 32.5 24.0
vol home 2980 5287 6504 10550 37.7 221.1
vol local 49477 49230 507892 204975 28.5 33.5
vol src 79174 23603 425472 139302 22.4 30.9
vol swapvol 22751 32364 182001 258905 25.3 323.2
OPERATIONS BLOCKS AVG TIME(ms)
TYP NAME READ WRITE READ WRITE READ WRITE
dm disk01 40473 174045 455898 951379 29.5 35.4
dm disk02 32668 16873 470337 351351 35.2 102.9
dm disk03 55249 60043 780779 731979 35.3 61.2
dm disk04 11909 13745 114508 128605 25.0 30.7
V NAME USETYPE KSTATE STATE LENGTH READPOL... PL NAME VOLUME KSTATE STATE LENGTH LAYOUT... SD NAME PLEX PLOFFS DISKOFFS LENGTH DISK-MEDIA...
v archive fsgen ENABLED ACTIVE 204800 SELECT - pl archive-01 archive ENABLED ACTIVE 204800 CONCAT - RW sd disk03-03 archive-01 0 409600 204800 disk03 rz2
Looking at the associated subdisks indicates that the archive volume is on disk disk03. To move the volume off disk03 and onto disk01, use one of the following commands.
K-shell users, enter:
#
volassist move archive !disk03 disk01
C-shell users, enter:
#
volassist move archive \!disk03 disk01
These commands indicate that the volume should be reorganized so that no part is on disk03, and that any parts to be moved should be moved to disk01.
Note
The easiest way to move pieces of volumes between disks is to use the Logical Storage Manager Visual Administrator (dxlsm). If dxlsm is available on the system, you may prefer to use it instead of the command-line utilities.
To convert to striping, create a striped mirror of the volume and then remove the old mirror. For example, to stripe the volume archive across disks disk02 and disk04, enter the following commands:
#
volassist mirror archive layout=stripe disk02 disk04
#
volplex -o rm dis archive-01
| If... | Then... |
| Some disks appear to be used excessively (or have particularly long read or write times) | Reconfigure some volumes. |
| There are two relatively busy volumes on a disk | Consider moving the volumes closer together to reduce seek times on the disk. |
| There are too many relatively busy volumes on one disk | Try to move the volumes to a disk that is less busy. |
Note
File systems and databases typically shift their use of allocated space over time, so this position-specific information on a volume often is not useful. For databases, it may be possible to identify the space used by a particularly busy index or table. If these can be identified, they are reasonable candidates for moving to disks that are not busy.
| If... | Then... |
| The read-to-write ratio is high | Mirroring could increase performance as well as reliability. The ratio of reads to writes where mirroring can improve performance depends greatly on the disks, the disk controller, whether multiple controllers can be used, and the speed of the system bus. |
| A particularly busy volume has a ratio of reads to writes as high as 5:1 | It is likely that mirroring can dramatically improve performance of that volume. |
Note
By using LSM mirroring, you can substantially reduce the risk that a single disk failure will result in the failure of a large number of volumes. This is because striping a volume increases the chance that a disk failure will result in failure of that volume. For example, if five volumes are striped across the same five disks, then failure of any one of the five disks will require that all five volumes be restored from a backup. If each volume were on a separate disk, only one volume would have to be restored.
![]()
Whereas I/O statistics provide the data for basic performance analysis, I/O traces provide for more detailed analysis. With an I/O trace, the focus of the analysis is narrowed to obtain an event trace for a specific workload. For example, you can identify exactly where a hot spot is, how big it is, and which application is causing it.
By using data from I/O traces, you can simulate real workloads on disks and trace the results. By using these statistics, you can anticipate system limitations and plan for additional resources.