




setlocale() function. This function configures the locale operation of both the host C library and Xlib. The operation of Xlib is governed by the LC_CTYPE category; this is called the current locale.The XSupportsLocale() function is used to determine whether the current locale is supported by X.
The client is responsible for selecting its locale and X modifiers. Clients should provide a means for the user to override the clients' locale selection at client invocation. Most single-display X clients operate in a single locale for both X and the host-processing environment. They configure the locale by calling three functions: setlocale(), XSupportsLocale(), and XSetLocaleModifiers().
The semantics of certain categories of X internationalization capabilities can be configured by setting modifiers. Modifiers are named by implementation-dependent and locale-specific strings. The only standard use for this capability at present is selecting one of several styles of keyboard input methods.
The XSetLocaleModifiers() function is used to configure Xlib locale modifiers for the current locale.
The recommended procedure for clients initializing their locale and modifiers is to obtain locale and modifier announcers separately from one of the following prioritized sources:
XSetLocaleModifiers() function, or in the locale and modifiers configured at the time some object supplied to the function was created. For each locale-dependent function, Table 5-1 lists locale and modifier dependencies.
Table 5-1 Locale and Modifier Dependencies 
All text strings processed by internationalized Xlib functions are assumed to begin in the initial state of the encoding of the locale, if the encoding is state-dependent. All Xlib functions behave as if they do not change the current locale or X modifier setting. (This means that any function, provided within a library either by Xlib or by the application, that changes the locale or calls the XSetLocaleModifiers() function with a nonnull argument, must save and restore the current locale state on entry and exit.) Also, Xlib functions on implementations that conform to the ANSI C library do not alter the global state associated with the mblen(), mbtowc(), wctomb(), and strtok() ANSI C functions.
XtSetLanguageProc() function with one of the following functions:
XtSetLanguageProc (NULL, NULL, NULL)
XtAppInitialize() function). Therefore, the setlocale() function may be needed after the XtSetLanguageProc() function and the initializing of the toolkit (for example, if calling the catopen() function).
Resource databases are created in the current process locale. During display initialization prior to creating the per-screen resource database, the Intrinsics call to a specified application procedure to set the locale according to options found on the command line or in the per-display resource specifications.
The callout procedure provided by the application is of type XtLanguageProc, as in the following syntax:
typedef String(*XtLanguageProc)(displayID, languageID, clientdata);
Display *displayID;
String languageID;
XtPointer clientdata;
XtSetLanguageProc() function.
XtDisplayInitialize() function. The function returns a new language string that is subsequently used by the XtDisplayInitialize() function to establish the path for loading resource files. This string is cached and is the locale of the display.
Initially, no language procedure is set by the intrinsics. To set the language procedure for use by the XtDisplayInitialize() function, use the XtSetLanguageProc() function:
XtLanguageProc XtSetLanguageProc(applicationcontext, procedure, clientdata)
XtAppContext applicationcontext;
XtLanguageProc procedure;
XtPointer clientdata;
XtSetLanguageProc() function sets the language procedure that is called from the XtDisplayInitialize() function for all subsequent displays initialized in the specified application context. If the applicationcontext parameter is null, the specified language procedure is registered in all application contexts created by the calling process, including any future application contexts that may be created. If the procedure parameter is null, a default language procedure is registered. The XtSetLanguageProc() function returns the previously registered language procedure. If a language procedure has not yet been registered, the return value is unspecified; but if this return value is used in a subsequent call to the XtSetLanguageProc() function, it causes the default language procedure to be registered.The default language procedure does the following:
XtWarning() function.
XSupportsLocale() function to verify that the current locale is supported. If the locale is not supported, a warning message is issued with the XtWarning() function and the locale is set to "C".
XSetLocaleModifiers() function specifying the empty string.
XtSetLanguageProc() function prior to the XtDisplayInitialize() function, as in the following example.
Widget top;
XtSetLanguageProc(NULL, NULL, NULL);
top = XtAppInitialize( ... );
...
XtDisplayInitialize() function first determines the language string to be used for the specified display and loads the application's resource database for this display-host-application combination from the following sources in order of precedence:
XtDisplayInitialize() function creates a unique resource database for each display parameter specified. When a database is created, a language string is determined for the display parameter in a manner equivalent to the following sequence of actions.
The XtDisplayInitialize() function initially creates two temporary databases. The first database is constructed by parsing the command line. The second database is constructed from the string returned by the XResourceManagerString() function or, if the XResourceManagerString() function returns a null value, the contents of a resource file in the user's home directory. The name for this user-preference resource file is $HOME/.Xdefaults.
The database constructed from the command line is then queried for the resource name.xnlLanguage, class class.XnlLanguage, where name and class are the specified application name and application class. If this database query is unsuccessful, the server resource database is queried; if this query is also unsuccessful, the language is determined from the environment. This is done by retrieving the value of the LANG environment variable. If no language string is found, the empty string is used.
The application-specific class resource file name is constructed from the class name of the application. It points to a localized resource file that is usually installed by the site manager when the application is installed. The file is found by calling the XtResolvePathname() function with the parameters (displayID, applicationdefaults, NULL, NULL, NULL, NULL, 0, NULL). This file should be provided by the developer of the application because it may be required for the application to function properly. A simple application that needs a minimal set of resources in the absence of its class resource file can declare fallback resource specifications with the XtAppSetFallbackResources() function.
The application-specific user resource file name points to a user-specific resource file and is constructed from the class name of the application. This file is owned by the application and typically stores user customizations. Its name is found by calling the XtResolvePathname() function with the parameters (displayID, NULL, NULL, NULL, path, NULL, 0, NULL), where path is defined in an operating-system-specific manner. The path variable is defined to be the value of the XUSERFILESEARCHPATH environment variable if this is defined. Otherwise, the default is vendor-defined.
If the resulting resource file exists, it is merged into the resource database. This file can be provided with the application or created by the user.
The temporary database created from the server resource property or user resource file during language determination is then merged into the resource database. The server resource file is created entirely by the user and contains both display-independent and display-specific user preferences.
If one exists, a user's environment resource file is then loaded and merged into the resource database. This file name is user- and host-specific. The user's environment resource file name is constructed from the value of the user's XENVIRONMENT environment variable for the full path of the file. If this environment variable does not exist, the XtDisplayInitialize() function searches the user's home directory for the .Xdefaults-host file, where host is the name of the machine on which the application is running. If the resulting resource file exists, it is merged into the resource database. The environment resource file is expected to contain process-specific resource specifications that are to supplement those user-preference specifications in the server resource file.
The two methods of internationalized drawing within the system environment allow clients to choose one of the static output widgets (for example, XmLabel) or to choose the DrawingArea widget to draw with any other primitive function.
Static output widgets require that text be converted to XmString.
The following information explains the mechanism for managing fonts using the Xlib routines and functions.
XFontSet is an opaque type.
XCreateFontSet() function is used to create an international text drawing font set.
XFontsOfFontSet() function is used to obtain a list of XFontStruct structures and full font names given an XFontSet.
XFontSet, use the XBaseFontNameListOfFontSet() function.
XFontSet, use the XLocaleOfFontSet() function.
XLocaleOfFontSet() function returns the name of the locale bound to the specified XFontSet as a null-terminated string.
XFreeFontSet() function frees the specified font set. The associated base font name list, font name list, XFontStruct list, and XFontSetExtents, if any, are freed.
The drawing functions are allowed to implement implicit text direction control, reversing the order in which characters are rendered along the primary draw direction in response to locale-specific lexical analysis of the string.
Regardless of the character rendering order, the origins of all characters are on the primary draw direction side of the drawing origin. The screen location of a particular character image may be determined with the XmbTextPerCharExtents() or XwcTextPerCharExtents() functions.
The drawing functions are allowed to implement context-dependent rendering, where the glyphs drawn for a string are not simply a combination of the glyphs that represent each individual character. A string of two characters drawn with the XmbDrawString() function may render differently than if the two characters were drawn with separate calls to the XmbDrawString() function. If the client adds or inserts a character in a previously drawn string, the client may need to redraw some adjacent characters to obtain proper rendering.
The drawing functions do not interpret newline characters, tabs, or other control characters. The behavior when nonprinting characters are drawn (other than spaces) is implementation-dependent. It is the client's responsibility to interpret control characters in a text stream.
To find out about context-dependent rendering, use the XContextDependentDrawing() function. The XExtentsOfFontSet() function obtains the maximum extents structure given an XFontSet. The XmbTextEscapement() and XwcTextEscapement() functions obtain the escapement in pixels of the specified text as a value. The XmbTextExtents() and XwcTextExtents() functions obtain the overall bounding box of the string's image and a logical bounding box (overall_ink_return and overall_logical_return arguments respectively). The XmbTextPerCharExtents() and XwcTextPerCharExtents() functions return the text dimensions of each character of the specified text, using the fonts loaded for the specified font set.
XDrawText(), XDrawString(), and XDrawImageString() functions except that they work with font sets instead of single fonts, and they interpret the text based on the locale of the font set instead of treating the bytes of the string as direct font indexes. If a BadFont error is generated, characters prior to the offending character may have been drawn. The text is drawn using the fonts loaded for the specified font set; the font in the graphics context (GC) is ignored and may be modified by the functions. No validation that all fonts conform to some width rule is performed.
Use the XmbDrawText() or XwcDrawText() function to draw text using multiple font sets in a given drawable. To draw text using a single font set in a given drawable, use the XmbDrawString() or XwcDrawString() function. To draw image text using a single font set in a given drawable, use the XmbDrawImageString() or XwcDrawImageString() function.
Text[Field] widgets or you are using the XmIm APIs for text input, this section provides background information. However, it will not impact your application design or coding practice. If you are not interested in how character input is achieved from the keyboard with low-level Xlib calls, you can proceed to "Interclient Communications Conventions for Localized Text" .A large number of languages in the world use alphabets consisting of a small set of symbols (letters) to form words. To enter text into a computer in an alphabetic language, a user usually has a keyboard on which there are key symbols corresponding to the alphabet. Sometimes, a few characters of an alphabetic language are missing on the keyboard. Many computer users who speak a Latin-alphabet-based language only have an English-based keyboard. They need to press a combination of keystrokes to enter a character that does not exist directly on the keyboard. A number of algorithms have been developed for entering such characters, known as European input methods, the compose input method, or the dead-keys input method.
Japanese is an example of a language with a phonetic symbol set, where each symbol represents a specific sound. There are two phonetic symbol sets in Japanese: Katakana and Hiragana. In general, Katakana is used for words that are of foreign origin, and Hiragana for writing native Japanese words. Collectively, the two systems are called Kana. Hiragana consists of 83 characters; Katakana, 86 characters.
Korean also has a phonetic symbol set, called Hangul. Each of the 24 basic phonetic symbols (14 consonants and 10 vowels) represent a specific sound. A syllable is composed of two or three parts: the initial consonants, the vowels, and the optional last consonants. With Hangul, syllables can be treated as the basic units on which text processing is done. For example, a delete operation may work on a phonetic symbol or a syllable. Korean code sets include several thousands of these syllables. A user types the phonetic symbols that make up the syllables of the words to be entered. The display may change as each phonetic symbol is entered. For example, when the second phonetic symbol of a syllable is entered, the first phonetic symbol may change its shape and size. Likewise, when the third phonetic symbol is entered, the first two phonetic symbols may change their shape and size.
Not all languages rely solely on alphabetic or phonetic systems. Some languages, including Japanese and Korean, employ an ideographic writing system. In an ideographic system, rather than taking a small set of symbols and combining them in different ways to create words, each word consists of one unique symbol (or, occasionally, several symbols). The number of symbols may be very large: approximately 50,000 have been identified in Hanzi, the Chinese ideographic system.
There are two major aspects of ideographic systems for their computer usage. First, the standard computer character sets in Japan, China, and Korea include roughly 8,000 characters, while sets in Taiwan have between 15,000 and 30,000 characters, which make it necessary to use more than one byte to represent a character. Second, it is obviously impractical to have a keyboard that includes all of a given language's ideographic symbols. Therefore a mechanism is required for entering characters so that a keyboard with a reasonable number of keys can be used. Those input methods are usually based on phonetics, but there are also methods based on the graphical properties of characters.
In Japan, both Kana and Kanji are used. In Korea, Hangul and sometimes Hanja are used. Now, consider entering ideographs in Japan, Korea, China, and Taiwan.
In Japan, either Kana or English characters are entered and a region is selected (sometimes automatically) for conversion to Kanji. Several Kanji characters can have the same phonetic representation. If that is the case, with the string entered, a menu of characters is presented and the user must choose the appropriate option. If no choice is necessary or a preference has been established, the input method does the substitution directly. When Latin characters are converted to Kana or Kanji, it is called a Romaji conversion.
In Korea, it is usually acceptable to keep Korean text in Hangul form, but some people may choose to write Hanja-originated words in Hanja rather than in Hangul. To change Hangul to Hanja, a region is selected for conversion and the user follows the same basic method as described for Japanese.
Probably because there are well-accepted phonetic writing systems for Japanese and Korean, computer input methods in these countries for entering ideographs are fairly standard. Keyboard keys have both English characters and phonetic symbols engraved on them, and the user can switch between the two sets.
The situation is different for Chinese. While there is a phonetic system called Pinyin promoted by authorities, there is no consensus for entering Chinese text. Some vendors use a phonetic decomposition (Pinyin or another), others use ideographic decomposition of Chinese words, with various implementations and keyboard layouts. There are about 16 known methods, none of which is a clear standard.
Also, there are actually two ideographic sets used: Traditional Chinese (the original written Chinese) and Simplified Chinese. Several years ago, the People's Republic of China launched a campaign to simplify some ideographic characters and eliminate redundancies altogether. Under the plan, characters would be streamlined every five years. Characters have been revised several times now, resulting in the smaller, simpler set that makes up Simplified Chinese.
Input methods may require one or more areas in which to show the feedback of the actual keystrokes, to show ambiguities to the user, to list dictionaries, and so on. The following are the input method areas of concern.
Using an input server implies communications overhead, but applications can be migrated without relinking. Input methods can be implemented either as a token communicating to an input server or as a local library.
The abstraction used by a client to communicate with an input method is an opaque data structure represented by the XIM data type. This data structure is returned by the XOpenIM() function, which opens an input method on a given display. Subsequent operations on this data structure encapsulate all communication between client and input method. There is no need for an X client to use any networking library or natural language package to use an input method.
A single input server can be used for one or more languages, supporting one or more encoding schemes. But the strings returned from an input method are always encoded in the (single) locale associated with the XIM object.
Figure 5-1 Input method and input contexts
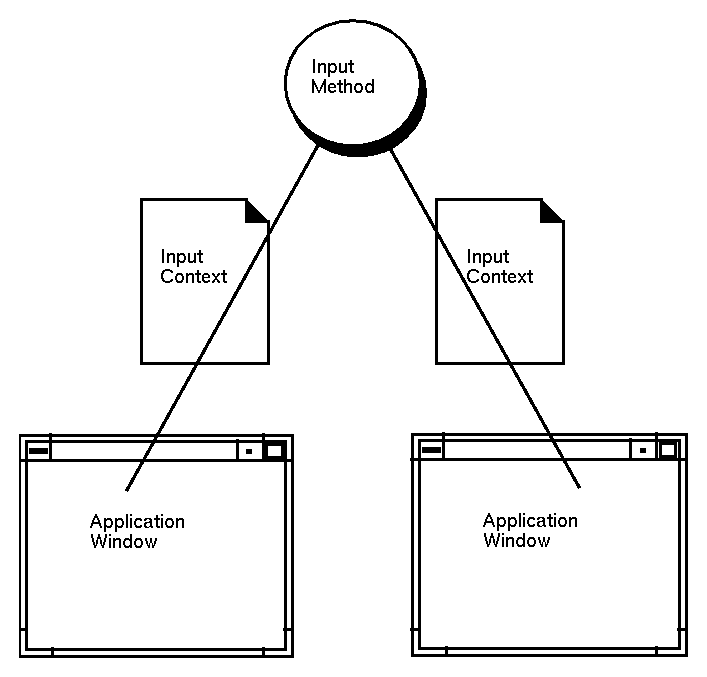
An input context is the abstraction retaining the state, properties, and semantics of communication between a client and an input method. An input context is a combination of an input method, a locale specifying the encoding of the character strings to be returned, a client window, internal state information, and various layout or appearance characteristics. The input context concept somewhat matches for input the graphics context abstraction defined for graphics output.
One input context belongs to exactly one input method. Different input contexts can be associated with the same input method, possibly with the same client window. An XIC is created with the XCreateIC() function, providing an XIM argument, affiliating the input context to the input method for its lifetime. When an input method is closed with the XCloseIM() function, no affiliated input contexts should be used again (and should preferably be deleted before closing the input method).
Considering the example of a client window with multiple text entry areas, the application programmer can choose to implement the following:
XmbLookupString() function or XwcLookupString() function with an input context created from that input method. Both a locale and display are bound to an input method when they are opened, and an input context inherits this locale and display. Any strings returned by the XmbLookupString() or XwcLookupString() function are encoded in that locale. XmbLookupString() or XwcLookupString() function is used, there is an associated input context.
When the application focus moves to a text-entry area, the application must set the input context focus to the input context associated with that area. The input context focus is set by calling the XSetICFocus() function with the appropriate input context.
Also, when the application focus moves out of a text-entry area, the application should unset the focus for the associated input context by calling the XUnsetICFocus() function. As an optimization, if the XSetICFocus() function is called successively on two different input contexts, setting the focus on the second automatically unsets the focus on the first.
If a single input context is used to do input for multiple text-entry areas, it is also necessary to set the focus window of the input context whenever the focus window changes.
The fundamental concept on which geometry management for input method windows is based is the proper division of responsibilities between the client (or toolkit) and the input method. The division of responsibilities is the following:
Before a client provides geometry management for an input method, it must determine if geometry management is needed. The input method indicates the need for geometry management by setting the XIMPreeditArea() or XIMStatusArea() function in its XIMStyles value returned by the XGetIMValues() function. When a client decides to provide geometry management for an input method, it indicates that decision by setting the XNInputStyle value in the XIC.
After a client has established with the input method that it will do geometry management, the client must negotiate the geometry with the input method. The geometry is negotiated by the following steps:
XNAreaNeeded value for that area. If the client has no constraints for the input method, it either does not suggest an area or sets the width and height to 0 (zero). Otherwise, it sets one of the values.
XNAreaNeeded value. The input method returns its suggested size in this value. The input method should pay attention to any constraints suggested by the client.
XNArea value to inform the input method of the geometry of the input method's window. The client should try to honor the geometry requested by the input method. The input method must accept this geometry.
XNFontSet and XNLineSpacing values may change the geometry desired by the input method. It is the responsibility of the client to renegotiate the geometry of the input method window when it is needed. In addition, a geometry management callback is provided by which an input method can initiate a geometry change.
XmbLookupString() or XwcLookupString() function call this filter at some point in the event processing mechanism to make sure that events needed by an input method can be filtered by that input method. If there is no filter, a client can receive and discard events that are necessary for the proper functioning of an input method. The following provides a few examples of such events:
When a keystroke is entered, the client calls the XmbLookupString() or XwcLookupString() function. At this point, in the OnTheSpot case, the echo of the keystroke in the preedit has not yet been done. Before returning to the client logic that handles the input characters, the lookup function must call the echoing logic for inserting the new keystroke. If the keystrokes entered so far make up a character, the keystrokes entered need to be deleted, and the composed character is returned. The result is that, while being called by client code, input method logic has to call back to the client before it returns. The client code, that is, a callback routine, is called from the input method logic.
There are a number of cases where the input method logic has to call back the client. Each of those cases is associated with a well-defined callback action. It is possible for the client to specify, for each input context, which callback is to be called for each action.
There are also callbacks provided for feedback of status information and a callback to initiate a geometry request for an input method.
A keysym is the encoding of a symbol on a keycap. The goal of the server's keysym mapping is to reflect the actual key caps on the physical keyboards. The user can redefine the keyboard by running the xmodmap command with the new mapping desired.
X Version 11 Release 4 (X11R4) allows for definition of a bilingual keyboard at the server. The following describes this capability.
A list of keysyms is associated with each key code. The following list discusses the set of symbols on the corresponding key:
K, the list is treated as if it were the list K NoSymbol K NoSymbol.
K1 K2, the list is treated as if it were the list K1 K2 K1 K2.
K1 K2 K3, the list is treated as if it were the list K1 K2 K3 NoSymbol.
The first four elements of the list are split into two groups of keysyms. Group 1 contains the first and second keysyms; Group 2 contains the third and fourth keysyms. Within each group, if the second element of the group is NoSymbol, the group is treated as if the second element were the same as the first element, except when the first element is an alphabetic keysym K for which both lowercase and uppercase forms are defined. In that case, the group is treated as if the first element is the lowercase form of K and the second element is the uppercase form of K.
The standard rules for obtaining a keysym from an event make use of the Group 1 and Group 2 keysyms only; no interpretation of other keysyms in the list is given here. The modifier state determines which group to use. Switching between groups is controlled by the keysym named MODE SWITCH by attaching that keysym to some key code and attaching that key code to any one of the modifiers Mod1 through Mod5. This modifier is called the group modifier. For any key code, Group 1 is used when the group modifier is off, and Group 2 is used when the group modifier is on.
Within a group, the keysym to use is also determined by the modifier state. The first keysym is used when the Shift and Lock modifiers are off. The second keysym is used when the Shift modifier is on, when the Lock modifier is on, and when the second keysym is uppercase alphabetic, or when the Lock modifier is on and is interpreted as ShiftLock. Otherwise, when the Lock modifier is on and is interpreted as CapsLock, the state of the Shift modifier is applied first to select a keysym; if that keysym is lowercase alphabetic, the corresponding uppercase keysym is used instead.
No spatial geometry of the symbols on the key is defined by their order in the keysym list, although a geometry might be defined on a vendor-specific basis. The server does not use the mapping between key codes and keysyms. Rather, it stores it merely for reading and writing by clients.
The KeyMask modifier named Lock is intended to be mapped to either a CapsLock or a ShiftLock key, but which one it is mapped to is left as an application-specific decision, user-specific decision, or both. However, it is suggested that users determine mapping according to the associated keysyms of the corresponding key code.
XmText widget, XmTextField widget, and the dtterm command adhere to these guidelines.
The toolkit is enhanced for internationalized ICCC compliance. The selection mechanism of XmText, XmTextField, and dtterm is enhanced to ensure proper matching of data and data encoding in any selection transaction. This includes standard cut-and-paste operations.
For developers who use the toolkit to write their applications, the toolkit enables the application to be ICCC-compliant. However, for developers who may use another non-ICCC-compliant toolkit to develop applications that communicate with toolkit-based applications, the following may be helpful.
COMPOUND_TEXT
XA_STRING
XA_TEXT is requested, the owner returns its text as is with the encoding type of the property set to the code set of the current locale (no data conversion). An atom is created, representing the name of the code set of the locale.
When COMPOUND_TEXT is requested, the owner converts its localized text to compound text and passes it with the property type of COMPOUND_TEXT.
When XA_STRING is requested, the owner attempts to convert the localized text to XA_STRING. If the text string contains characters that cannot be converted to XA_STRING, the operation is unsuccessful.
XA_STRING is defined to be ISO8859-1.
XA_TARGET when text data is to be communicated with the selection owner.The requester then searches for one of the following atoms in priority order:
XA_TEXT atom is used only if none of the other atoms is found. Because the owner returns a property with a type representing its encoding, the requester attempts to convert to the code set of its locale.
If the type COMPOUND_TEXT or XA_STRING is requested, the requester attempts to convert the text property to the code set of its current locale by using the XmbTextPropertyToTextList() or XwcTextPropertyToTextList() functions. These are used when the owner client and requester client are running under different code sets.
When converting from COMPOUND_TEXT or XA_STRING, not all text data is guaranteed to be converted; only those characters that are in common between the owner and the requester will be converted.
XmClipboard is also enhanced to be ICCC-compliant in conjunction with the XmText and XmTextField widgets. When text is being put on the clipboard by way of the XmText and XmTextField widgets, the following ICCC protocol is implemented:
When text is being retrieved from the clipboard by way of the XmText and XmTextField widgets, the text from the clipboard is converted to encoding of the current locale from either COMPOUND_TEXT or XA_STRING. All text on the clipboard is assumed to be in either the compound text format or the string format.
XtNtitleEncoding and XtNiconNameEncoding resources for the VendorShell class is set to None. This is done only when using the libXm.a library. The libXt.a library still retains XA_STRING as the default for the resources.
This is done so that, as a default case, the XmNtitle and XmNiconName resources are converted to a standard ICCC interchange, such as compound text, based on the assumption the text (title and icon name) is localized text.
It is recommended that the user not set the XtNtitleEncoding and XtNiconNameEncoding resources. Instead, ensure that the XtNtitle and XtNiconName resources are strings encoded in the encoding of the currently active locale of the running client. If the None value is used, the toolkit converts the localized text to the standard ICCC style. (The encoding communicated is COMPOUND_TEXT or XA_STRING.) If the XtNtitleEncoding and XtNiconNameEncoding resources are set, the XtNtitle and XtNiconName resources are not converted in any way and are communicated to the Window Manager with the encoding specified.
Assuming the Window Manager being communicated with is ICCC-compliant, that Window Manager is able to use the encoding type of COMPOUND_TEXT or XA_STRING, or both.
When setting the XmNdialogTitle resource of the XmBulletinBoard widget class, remember that there is a restriction on the charset segment. For charsets that are not X Consortium-standard compound text encodings or XmFONTLIST_DEFAULT_TAG-associated, the text segment is treated as localized text. Localized text is converted to either compound text or ISO8859-1 before being communicated to the Window Manager.
The Window Manager is enhanced so that it always converts the client title and icon name passed from clients to the encoding of its current locale, and an XmString is created using the XmFONTLIST_DEFAULT_TAG identifier. Thus, the client title and icon name are always drawn with the default font list entry of the Window Manager font list.
In general, for any error or warning messages to be displayed to the user through a system environment toolkit widget or gadget, the messages need to be externalized through message catalogs.
For dialog messages to be displayed through a toolkit component, the messages need to be externalized through localized resource files. This is done in the same way as localizing resources, such as the XmLabel and XmPushbutton classes' XmNlabelString resource or window titles.
For example, if a warning message is to be displayed through an XmMessageBox widget class, the XmNmessageString resource cannot be hardcoded within the application source code. Instead, the value of this resource needs to be retrieved from a message catalog. For an internationalized application expected to run in different locales, a distinct localized catalog must exist for each of the locales to be supported. In this way, the application need not be rebuilt.
The localized resource files can be put in the /opt/dt/app-defaults/%L subdirectories or they can be pointed to by the XENVIRONMENT environment variable. The %L variable indicates the locale used at run time.
The preceding two choices are left as design decisions for the application developer.