![[Return to Library]](BOOKSHELF.GIF)
![[Contents]](TOC.GIF)
![[Previous Chapter]](REW.GIF)
![[Next Section]](NEXT.GIF)
![[Next Chapter]](FF.GIF)
![[Index]](INDEX.GIF)
![[Help]](HELP.GIF)
![]()
Symmetric multiprocessing (SMP) describes a computer environment that uses two or more central processing units (CPUs). In an SMP environment, software applications and the associated device drivers can operate on two or more of these CPUs. To ensure the integrity of the data manipulated by device drivers in this multiprocessor environment, you must perform additional design and implementation tasks beyond those discussed in Writing Device Drivers: Tutorial. One of these tasks involves choosing a locking method. Digital UNIX provides you with three methods to write SMP-safe device drivers: simple locks, complex locks, and funnels.
This chapter discusses the information you need to decide which items (variables, data structures, and code blocks) must be locked in the device driver and to choose the appropriate method or methods (simple locks, complex locks, and funnels).
Specifically, the chapter describes the following topics associated with designing and developing a device driver that can operate safely in an SMP environment:
The following sections discuss each of these topics. You do not need an intimate understanding of kernel threads to learn about writing device drivers in an SMP environment. Part 3 of this book discusses kernel threads and the associated interfaces that device drivers use to create and manipulate them.
![]()
Alpha CPUs provide several features to assist with hardware-level synchronization. Even though all instructions that access memory are noninterruptible, no single one performs an atomic read-modify-write operation. A kernel-mode thread of execution can raise the interrupt priority level (IPL) in order to block other kernel threads on that CPU while it performs a read-modify-write sequence or while it executes any other group of instructions. Code that runs in any access mode can execute a sequence of instructions that contains load-locked (LDx_L) and store-conditional (STx_C) instructions to perform a read-modify-write sequence that appears atomic to other kernel threads of execution.
Memory barrier instructions order a CPU's memory reads and writes from the viewpoint of other CPUs and I/O processors. The locking mechanisms (simple and complex locks) that Digital provides take care of the idiosyncracies related to read-modify-write sequences and memory barriers on Alpha CPUs. Therefore, you need not be concerned about these hardware issues when implementing SMP-safe device drivers that use simple and complex locks.
The rest of this section describes the following hardware-related issues:
![[Previous Section]](PREV.GIF)
Software synchronization refers to the coordination of events in such a way that only one event happens at a time. This kind of synchronization is a serialization or sequencing of events. Serialized events are assigned an order and processed one at a time in that order. While a serialized event is being processed, no other event in the series is allowed to disrupt it.
By imposing order on events, software synchronization allows reading and writing of several data items indivisibly, or atomically, to obtain a consistent set of data. For example, all of process A's writes to shared data must happen before or after process B's writes or reads, but not during process B's writes or reads. In this case, all of process A's writes must happen indivisibly for the operation to be correct. This includes process A's updates reading of a data item, modifying it, and writing it back (read-modify-write sequence). Other synchronization techniques ensure the completion of an asynchronous system service before the caller tries to use the results of the service.
Atomicity is a type of serialization that refers to the indivisibility of a small number of actions, such as those occurring during the execution of a single instruction or a small number of instructions. With more than one action, no single action can occur by itself. If one action occurs, then all the actions occur. Atomicity must be qualified by the viewpoint from which the actions appear indivisible: an operation that is atomic for kernel threads running on the same CPU can appear as multiple actions to a kernel thread of execution running on a different CPU.
An atomic memory reference results in one indivisible read or write of a data item in memory. No other access to any part of that data can occur during the course of the atomic reference. Atomic memory references are important for synchronizing access to a data item that is shared by multiple writers or by one writer and multiple readers. References need not be atomic to a data item that is not shared or to one that is shared but is only read.
Alignment refers to the placement of a data item in memory. For a data item to be naturally aligned, its lowest-addressed byte must reside at an address that is a multiple of the size of the data item (in bytes). For example, a naturally aligned longword has an address that is a multiple of 4. The term naturally aligned is usually shortened to ``aligned.''
An Alpha CPU allows atomic access only to an aligned longword or an aligned quadword. Reading or writing an aligned longword or quadword of memory is atomic with respect to any other kernel thread of execution on the same CPU or on other CPUs.
The phrase granularity of data access refers to the size of neighboring units of memory that can be written independently and atomically by multiple CPUs. Regardless of the order in which the two units are written, the results must be identical.
Alpha systems have longword and quadword granularity. That is, only adjacent aligned longwords or quadwords can be written independently. Because Alpha systems support only instructions that load or store longword-sized and quadword-sized memory data, the manipulation of byte-sized and word-sized data on Alpha systems requires that the entire longword or quadword that contains the byte- or word-sized item be manipulated. Thus, simply because of its proximity to an explicitly shared data item, neighboring data might become shared unintentionally. Manipulation of byte-sized and word-sized data on Alpha systems requires multiple instructions that:
Because this sequence is interruptible, operations on byte and word data are not atomic on Alpha systems. Also, this change in the granularity of memory access can affect the determination of which data is actually shared when a byte or word is accessed.
The absence of byte and word granularity on Alpha systems has important implications for access to shared data. In effect, any memory write of a data item other than an aligned longword or quadword must be done as a multiple-instruction read-modify-write sequence. Also, because the amount of data read and written is an entire longword or quadword, you must ensure that all accesses to fields within the longword or quadword are synchronized with each other.
In a single processor environment, device drivers need not protect the integrity of a resource from activities resulting from the actions of another CPU. However, in an SMP environment, the device driver must protect the resource from multiple CPU access to prevent corruption. A resource, from the device driver's standpoint, is data that more than one kernel thread can manipulate. You can store the resource in variables (global) and data structure members. The top half of Figure 2-1 shows a typical problem that could occur in an SMP environment. The figure shows that the resource called i is a global variable whose initial value is 1.
Furthermore, the figure shows that the kernel threads emanating from CPU1 and CPU2 increment resource i. A kernel thread is a single sequential flow of control within a device driver or other systems-based program. The device driver or other systems-based program makes use of the kernel interfaces (instead of a threads library package such as DECthreads) to start, terminate, delete, and perform other kernel threads-related operations. These kernel threads cannot increment this resource simultaneously. Without some way to lock the global variable when one kernel thread is incrementing it, the integrity of the data stored in this resource is compromised in the SMP environment.
To protect the integrity of the data, you must enforce order on the accesses of the data by multiple CPUs. One way to establish the order of CPU access to the resource is to establish a lock. As the bottom half of the figure shows, the kernel thread emanating from CPU1 locks access to resource i, thus preventing access by kernel threads emanating from CPU2. This guarantees the integrity of the value stored in this resource.
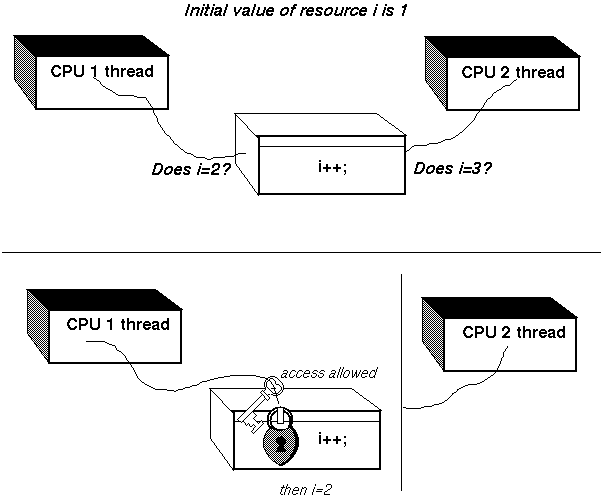
The vertical line in the bottom half of the figure represents a barrier that prevents the kernel thread emanating from CPU2 from accessing resource i until the kernel thread emanating from CPU1 unlocks it. For simple locks, this barrier indicates that the lock is exclusive. That is, no other kernel thread can gain access to the lock until the kernel thread currently controlling it has released (unlocked) it.
For complex write locks, this barrier represents a wait hash queue that collects all of the kernel threads waiting to gain write access to a resource. With complex read locks, all kernel threads can access the same resource read-only at the same time.
For funnels, this barrier indicates that processing of the device driver subsystem is forced onto a single CPU.
Digital UNIX provides three ways to lock specific resources (global variables and data structures) referenced in code blocks in the device driver: simple locks, complex locks, and funnels. Simple and complex locks allow device drivers to:
A funnel allows device drivers to force execution onto a single CPU. In this case, the locking is achieved by simulating a single-processor environment.
The following sections briefly describe simple locks, complex locks, and funnels.
A simple lock is a general-purpose mechanism for protecting resources in an SMP environment. Figure 2-2 shows that simple locks are spin locks. That is, the kernel interfaces used to implement the simple lock do not return until the lock has been obtained.
As the figure shows, the CPU1 kernel thread obtains a simple lock on resource i. Once the CPU1 kernel thread obtains the simple lock, it has exclusive access over the resource to perform read and write operations on the resource. The figure also shows that the CPU2 kernel thread spins while waiting for the CPU1 kernel thread to unlock (free) the simple lock.
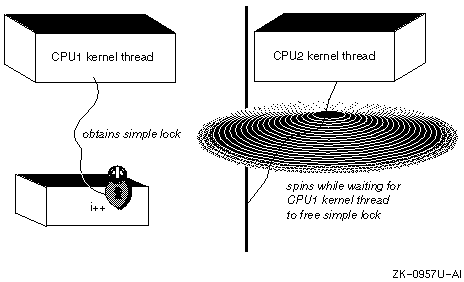
There are tradeoffs in performance and realtime preemption latency associated with simple locks that you should understand before you use them. However, there are times when device drivers must use simple locks. For example, device drivers must use simple locks (together with the spl interfaces) to synchronize with interrupt service interfaces. Section 2.4 provides guidelines to help you choose between simple locks, complex locks, or funnels.
Table 2-1 lists the kernel interfaces and data structure associated with simple locks. Chapter 3 discusses how to use these interfaces and data structure to implement simple locks in a device driver.
| Kernel Interfaces/Structure | Description |
| decl_simple_lock_data | Declares a simple lock structure. |
| simple_lock | Asserts a simple lock. |
| simple_lock_init | Initializes a simple lock structure. |
| simple_lock_terminate | Terminates, using a simple lock. |
| simple_lock_try | Tries to assert a simple lock. |
| simple_unlock | Releases a simple lock. |
| slock | Contains simple lock-specific information. |
A complex lock is a mechanism for protecting resources in an SMP environment. A complex lock achieves the same results as a simple lock. However, device drivers should use complex locks (not simple locks) if there are blocking conditions.
The kernel interfaces that implement complex locks synchronize access to kernel data between multiple kernel threads. The following describes characteristics associated with complex locks:
Figure 2-3 shows that complex locks are not spin locks, but blocking (sleeping) locks. That is, the kernel interfaces used to implement the complex lock block (sleep) until the lock is released. Thus, unlike simple locks, you should not use complex locks to synchronize with interrupt service interfaces. Because of the blocking characteristic of complex locks, they are active on both single and multiple CPUs to serialize access to data between kernel threads.
As the figure shows, the CPU1 kernel thread asserts a complex lock with write access on resource i. The CPU2 kernel thread also asserts a complex lock with write access on resource i. Because the CPU1 kernel thread asserts the write complex lock on resource i first, the CPU2 kernel thread blocks, waiting until the CPU1 kernel thread unlocks (frees) the complex write lock.
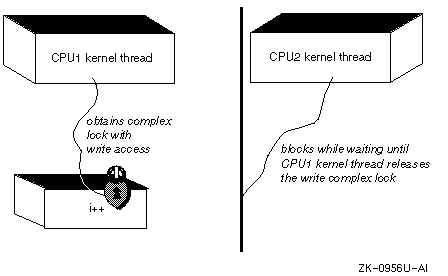
Like simple locks, complex locks present tradeoffs in performance and realtime preemption latency that you should understand before you use them. However, there are times when device drivers must use complex locks. For example, device drivers must use complex locks when there are blocking conditions in the code block. On the other hand, you must not take a complex lock while holding a simple lock or when using the timeout interface. Section 2.4 provides guidelines to help you choose between simple locks, complex locks, or funnels.
Table 2-2 lists the kernel interfaces and data structure associated with complex locks.
Chapter 4 discusses how to use these interfaces and data structure to implement complex locks in a device driver.
| Kernel Interfaces/Structure | Description |
| lock | Contains complex lock-specific information. |
| lock_done | Releases a complex lock. |
| lock_init | Initializes a complex lock. |
| lock_read | Asserts a complex lock with read-only access. |
| lock_terminate | Terminates, using a complex lock. |
| lock_try_read | Tries to assert a complex lock with read-only access. |
| lock_try_write | Tries to assert a complex lock with write access. |
| lock_write | Asserts a complex lock with write access. |
A funnel is a mechanism for protecting resources in an SMP environment. A funnel achieves the same results as simple and complex locks, not by locking resources and code blocks but by forcing execution of a subsystem (for example, a device driver) onto a single CPU. You funnel a device driver onto a single CPU by setting the d_funnel member of the associated dsent structure to the value DEV_FUNNEL. This value causes the kernel to make the appropriate calls to unix_master and unix_release to force execution of the driver onto the master CPU. Device drivers should not directly call the unix_master and unix_release interfaces. One exception to this recommendation is when you want a device driver's kernel threads to run only on the master CPU. This situation occurs when your driver creates and starts its own kernel threads and you set the d_funnel member of the associated dsent structure to the value DEV_FUNNEL. In this case, each kernel thread must call unix_master once to ensure that the kernel thread runs only on the master CPU. Remember to make a corresponding call to unix_release.
Figure 2-4 shows this feature of funnels. As the figure shows, the CPU1 kernel thread emanating from some device driver causes the kernel to call the unix_master interface, which forces execution onto the master CPU (also called the boot CPU). This action assumes that the device driver initialized the d_funnel member of the dsent or dsent table to DEV_FUNNEL.
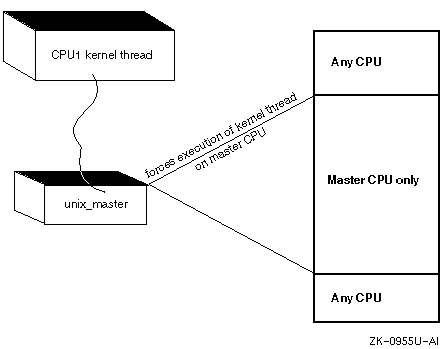
Using funnels is not optimal for performance on CPUs running in an SMP environment. However, you can use funnels as an alternative to simple and complex locks to write SMP-safe third-party device drivers. Like simple and complex locks, funnels present tradeoffs in performance and realtime preemption latency that you should understand before you use them. Section 2.4 provides guidelines to help you choose between simple locks, complex locks, or funnels.
You can make your device drivers SMP safe by implementing a locking method (simple or complex) or by using a funnel. Use a funnel if it is acceptable to force execution of the device driver onto a single CPU and optimal performance is not a consideration. Otherwise, choose one of the locking methods.
This section provides guidelines to help you choose
the appropriate locking method (simple or complex).
In choosing a locking method, consider the following SMP-related
characteristics:
The following sections discuss each of these characteristics. See Section 2.4.6 for a summary comparison table of the locking methods that you can use to determine which items to lock in your device drivers.
To choose the appropriate lock method, you must understand the entity that has access to a particular resource. Possible entities that can access a resource are kernel threads, interrupt service interfaces, and exceptions. If you need a lock for resources accessed by multiple kernel threads, use simple or complex locks. Use a combination of spl interfaces and simple locks to lock resources that kernel threads and interrupt service interfaces access.
For exceptions, use complex locks if the exception involves blocking conditions. If the exception does not involve blocking conditions, you can use simple locks.
You must determine if it is necessary to prevent access to the resource while a kernel thread blocks (sleeps). One example is waiting for disk I/O to a buffer. If you need a lock to prevent access to the resource while a kernel thread blocks (sleeps) and there are no blocking conditions, use simple or complex locks. Otherwise, if there are blocking conditions, use complex locks.
You must estimate the length of time the lock is held to determine the appropriate lock method. In general, use simple locks when the entity accesses are bounded and small. One example of a bounded and small access is some entity accessing a system time variable. Use complex locks when the entity accesses could take a long time or a variable amount of time. One example of a variable amount of time is some entity scanning linked lists.
You must account for execution speed in choosing the appropriate lock method. The following factors influence execution speed:
Complex locks are slightly more than twice as expensive (in terms of execution speed) as simple locks. The reason for this is that complex locks use the simple lock interfaces to implement the lock. Thus, it takes two lock and unlock pairs to protect a resource or code block with a complex lock as opposed to one pair for the simple lock.
Complex locks use more memory space than simple locks. The reason for this is the complex lock structure, lock, contains a pointer to a simple lock structure in addition to other data to implement the complex lock.
Busy wait time is the amount of CPU time expended on waiting for a simple lock to become free. If the driver initiates a simple lock on a resource and the code block is long (or there are numerous interrupts), a lot of CPU time could be wasted waiting for the simple lock to become free. If this is the case, use complex locks to allow the current kernel thread to block (sleep) on the busy resource. This action allows the CPU to execute a different kernel thread.
Realtime preemption cannot occur when a simple lock is held. Use of complex locks (which can block) improves the performance associated with realtime preemption.
In general, use complex locks for resources contained in long code blocks. Also, use complex locks in cases where the resource must be prevented from changing when a kernel thread blocks (sleeps).
Use simple locks for resources contained in short, nonblocking code blocks or when synchronizing with interrupt service interfaces.
Table 2-3 summarizes the SMP-related characteristics for choosing the appropriate lock method to make your device driver SMP safe. The first column of the table presents an SMP-related characteristic and the second and third columns present the lock methods. The following list describes the possible entities that can appear in the second and third columns:
Indicates that the lock method is suitable for the characteristic
Indicates that the lock method is not suitable for the characteristic
Indicates that this lock method is most suitable for the characteristic
Indicates that this lock method is not the most suitable for the characteristic
(The numbers under Characteristic appear for easy reference in later descriptions.)
| Characteristic | Simple Lock | Complex Lock |
| 1. Kernel threads will access this resource. | Yes | Yes |
| 2. Interrupt service interfaces will access this resource. | Yes | No |
| 3. Exceptions will access this resource. | Yes | Yes |
| 4. Need to prevent access to this resource while a kernel thread blocks and there are no blocking conditions. | Yes | Yes |
| 5. Need to prevent access to this resource while a kernel thread blocks and there are blocking conditions. | No | Yes |
| 6. Need to protect resource between kernel threads and interrupt service interfaces. | Yes | No |
| 7. Need to have maximum execution speed for this device driver. | Yes | No |
| 8. The driver references and updates this resource in long code blocks (implying that the length of time the lock is held on this resource is not bounded and long). | Worse | Better |
| 9. The driver references and updates this resource in short nonblocking code blocks (implying that the length of time the lock is held on this resource is bounded and short). | Better | Worse |
| 10. Need to minimize memory usage by the lock-specific data structures. | Yes | No |
| 11. Need to synchronize with interrupt service interfaces. | Yes | No |
| 12. The driver can afford busy wait time. | Yes | No |
| 13. The driver implements realtime preemption. | Worse | Better |
Use the following steps to analyze your device driver to determine which items to lock and which locking method to choose:
Section 2.4 presents the SMP-related characteristics you must consider when choosing a locking method. You need to analyze each section of the driver (for example, the open and close device section, the read and write device section, and so forth) and apply those SMP-related characteristics to the following resource categories:
The following sections discuss each of these categories. See Section 2.5.5 for an example that walks you through the steps for analyzing a device driver to determine which resources to lock.
Analyze each section of your device driver to determine if the access to a resource is read only. In this case, resource refers to driver and system data stored in global variables or data structure members. You do not need to lock resources that are read only because there is no way to corrupt the data in a read-only operation.
Analyze each section of your device driver to determine accesses to a device's control status register (CSR) addresses. Many device drivers based on the UNIX operating system use the direct method; that is, they access a device's CSR addresses directly through a device register structure. This method involves declaring a device register structure that describes the device's characteristics, which include a device's control status register. After declaring the device register structure, the driver accesses the device's CSR addresses through the member that maps to it.
There are some CPU architectures that do not allow you to access the device CSR addresses directly. Device drivers that need to operate on these types of CPUs should use the indirect method. In fact, device drivers operating on Alpha systems must use the indirect method. Thus, the discussion of locking a device's CSR addresses focuses on the indirect method.
The indirect method involves defining device register offset definitions (instead of a device register structure) that describe the device's characteristics, which include a device's control status register. The method also includes the use of the following categories of kernel interfaces:
Reads data from a device register
Writes data to a device register
Copies data from bus address space to system memory
Copies data from bus address space to bus address space
Copies data from system memory to bus address space
Using these interfaces makes your driver more portable across different bus architectures, different CPU architectures, and different CPU types within the same architecture. See Writing Device Drivers: Tutorial for examples of how to use these interfaces.
The following example shows the device register offset definitions that some /dev/xx driver defines for some XX device:
.
.
.
#define XX_ADDER 0x0 /* 32-bit read/write DMA address register */ #define XX_DATA 0x4 /* 32-bit read/write data register */ #define XX_CSR 0x8 /* 16-bit read/write CSR/LED register */ #define XX_TEST 0xc /* Go bit register. Write sets. Read clears */
.
.
.
Analyze the declarations and definitions sections of your device driver to identify the following global resources:
Driver-specific variables can store a variety of information including the following: flag values that control execution of code blocks and status information. The following example shows the declaration and initialization of some typical driver-specific global variables. Use this example to help you locate similar driver-specific global variables in your device drivers.
.
.
.
int num_xx = 0;
.
.
.
int xx_is_dynamic = 0;
.
.
.
Driver-specific data structures contain members that can store such information as whether the device is attached, whether the device is opened, the read/write mode, and so forth. The following example shows the declaration and initialization of some typical driver-specific data structures. Use this example to help you locate similar driver-specific data structures in your device drivers.
.
.
.
struct driver xxdriver = {
.
.
.
};
.
.
.
cfg_subsys_attr_t xx_attributes[] = {
.
.
.
};
.
.
.
};
.
.
.
struct xx_softc {
.
.
.
} xx_softc[NXX];
.
.
.
struct cdevsw xx_cdevsw_entry = {
.
.
.
};
After you identify the driver-specific global variables and driver-specific data structures, locate the code blocks in which the driver references them. Use Table 2-3 to determine which locking method is appropriate. Also, determine the granularity of the lock.
Analyze the declarations and definitions sections of your device driver to identify the following global resources:
System-specific variables include the global variables hz, cpu, and lbolt. The following example shows the declaration of one system-specific global variable:
.
.
.
extern int hz;
.
.
.
System-specific data structures include controller, buf, and ihandler_t. The following example shows the declaration of some system-specific data structures:
.
.
.
struct controller *info[NXX];
.
.
.
struct buf cbbuf[NCB];
.
.
.
After you identify the system-specific global variables and system-specific data structures, locate the code blocks in which the driver references them. Use Table 2-3 to determine which locking method is appropriate. Also, determine the granularity of the lock.
Note
To lock buf structure resources, use the BUF_LOCK and BUF_UNLOCK interfaces instead of the simple and complex lock interfaces. See Writing Device Drivers: Reference for descriptions of these interfaces.
![]()
Use the following steps to determine which resources to lock in your device drivers:
The following example walks you through an analysis of which resources to lock for the /dev/xx driver.
Table 2-4 summarizes the resources that you might lock in your driver according to the following categories:
| Category | Associated Resources |
| N/A | Device control status register (CSR) addresses. |
| Device driver-specific global variables. |
Variables that store flag values to control execution of code blocks.
Variables that store status information. |
| Device driver-specific global data structures. | dsent, cfg_subsys_attr_t, driver, and the driver's softc structure. |
| System-specific global variables | cpu, hz, lbolt, and page_size. |
| System-specific global data structures | controller and buf. |
One resource that the /dev/xx driver must lock is the device CSR addresses. This driver also needs to lock the hz global variable. The example analysis focuses on the following device register offset definitions for the /dev/xx driver:
.
.
.
#define XX_ADDER 0x0 /* 32-bit read/write DMA address register */ #define XX_DATA 0x4 /* 32-bit read/write data register */ #define XX_CSR 0x8 /* 16-bit read/write CSR/LED register */ #define XX_TEST 0xc /* Go bit register. Write sets. Read clears */
.
.
.
Identify all of the code blocks that manipulate the resource. If the code block accesses the resource read-only, you may not need to lock the resources that it references. However, if the code block writes to the resource, you need to lock the resource by calling the simple or complex lock interfaces.
The /dev/xx driver accesses the device register offset definition resources in the Open and Close Device Section and the Read and Write Device Section.
Table 2-5
shows how to analyze the locking
method that is most suitable for the device register offset definitions
for some
/dev/xx
driver.
(The numbers under Characteristic appear for easy reference in later
descriptions.)
| Characteristic | Applies to This Driver | Simple Lock | Complex Lock |
| 1. Kernel threads will access this resource. | Yes | Yes | Yes |
| 2. Interrupt service interfaces will access this resource. | No | N/A | N/A |
| 3. Exceptions will access this resource. | No | N/A | N/A |
| 4. Need to prevent access to this resource while a kernel thread blocks and there are no blocking conditions. | Yes | Yes | Yes |
| 5. Need to prevent access to this resource while a kernel thread blocks and there are blocking conditions. | No | N/A | N/A |
| 6. Need to protect resource between kernel threads and interrupt service interfaces. | Yes | Yes | No |
| 7. Need to have maximum execution speed for this device driver. | Yes | Yes | No |
| 8. The driver references and updates this resource in long code blocks (implying that the length of time the lock is held on this resource is not bounded and long). | No | N/A | N/A |
| 9. The driver references and updates this resource in short nonblocking code blocks (implying that the length of time the lock is held on this resource is bounded and short). | Yes | Better | Worse |
| 10. Need to minimize memory usage by the lock-specific data structures. | Yes | Yes | No |
| 11. Need to synchronize with interrupt service interfaces. | No | N/A | N/A |
| 12. The driver can afford busy wait time. | Yes | Yes | No |
| 13. The driver implements realtime preemption. | No | N/A | N/A |
The locking analysis table for the device register offset definitions shows the following:
Based on the previous analysis, the /dev/xx driver uses the simple lock method.
After choosing the appropriate locking method for the resource, determine the granularity of the lock. For example, in the case of the device register offset resource you can determine the granularity by answering the following questions:
Table 2-5 shows that the need to minimize memory usage is important to the /dev/xx driver; therefore, creating one simple lock for all of the device register offset definitions would save the most memory. The following code fragment shows how to declare a simple lock for all of the device register offset definitions:
.
.
.
#include <kern/lock.h>
.
.
.
decl_simple_lock_data( , slk_xxdevoffset);
.
.
.
If the preservation of memory were not important to the /dev/xx driver, declaring a simple lock for each device register offset definition might be more appropriate. The following code fragment shows how to declare a simple lock structure for each of the example device register offset definitions:
.
.
.
#include <kern/lock.h>
.
.
.
decl_simple_lock_data( , slk_xxaddr); decl_simple_lock_data( , slk_xxdata); decl_simple_lock_data( , slk_xxcsr); decl_simple_lock_data( , slk_xxtest);
.
.
.
After declaring a simple lock structure for an associated resource, you must initialize it (only once) by calling simple_lock_init. You then use the simple lock-related interfaces in code blocks that access the resource. Chapter 3 discusses the simple lock-related interfaces.