![[Return to Library]](BOOKSHELF.GIF)
![[Contents]](TOC.GIF)
![[Previous Chapter]](REW.GIF)
![[Next Section]](NEXT.GIF)
![[Next Chapter]](FF.GIF)
![[Index]](INDEX.GIF)
![[Help]](HELP.GIF)
![]()
If a program needs to receive and process input, there must be a means of analyzing the input before it is processed. You can analyze input with one or more routines within the program, or with a separate program designed to filter the input before passing it to the main program. The complexity of the input interface depends on the complexity of the input; complicated input can require significant code to parse it (break it into pieces that are meaningful to the program). This chapter describes the following two tools that help develop input interfaces:
To avoid confusion between the lex and yacc programs and the programs they generate, lex and yacc are referred to throughout this chapter as tools.
![]()
The lexical analyzer that lex generates is a deterministic finite-state automaton. This design provides for a limited number of states that the lexical analyzer can exist in, along with the rules that determine what state the lexical analyzer moves to upon reading and interpreting the next input character.
The compiled lexical analyzer performs the following functions:
Figure 4-1
illustrates a simple lexical analyzer that has three states:
start,
good,
and
bad.
The program reads an input stream of characters. It begins in the
start
condition. When it receives the first character, the program compares
the character with the rule. If the character is alphabetic (according
to the rule), the program changes to the
good
state; if it is not alphabetic, the program changes to the
bad
state. The program stays in the
good
state until it finds a character that does not match its conditions,
and then it moves to the
bad
state, which terminates the program.

The automaton allows the generated lexical analyzer to look ahead more than one or two characters in an input stream. For example, suppose the lex specification file defines a rule that looks for the string "ab" and another rule that looks for the string "abcdefg". If the lexical analyzer gets an input string of "abcdefh", it reads enough characters to attempt a match on "abcdefg". When the "h" disqualifies a match on "abcdefg", the analyzer returns to the rule that looks for "ab". The first two characters of the input match "ab", so the analyzer performs any action specified in that rule and then begins trying to find another match using the remaining input, "cdefh".
![[Previous Section]](PREV.GIF)
The lex tool helps write a C language lexical analyzer program that can receive character stream input and translate that input into program actions. To use lex, you must write a specification file that contains the following parts:
The actual format and logic allowed in the specification file are discussed in Section 4.3.
The
lex
tool uses the information in the specification file to generate the
lexical analyzer. The tool names the created analyzer program
yy.lex.c.
The
yy.lex.c
program contains a set of standard functions together with the analysis
code that is generated from the specification file. The analysis code
is contained in the
yylex
function. Lexical analyzers created by
lex
recognize simple grammar structures and regular expressions. You can
compile a simple
lex
analyzer program with the following command:
%
cc -ll yy.lex.c
The -ll option tells the compiler to use the lex function library. This command yields an executable lexical analyzer. If your program uses complex grammar rules, or if it uses no grammar rules, you should create a parser (by combining the lex and yacc tools) to ensure proper handling of the input. (See Section 4.6.)
The yy.lex.c output file can be moved to any other system having a C compiler that supports the lex library functions.
The format of the lex specification file is as follows:
[
{
definitions
}
]
%%
[
{
rules
}
]
[
%%
{
user subroutines
}
]
Except for the first pair of percent signs (%%), which mark the beginning of the rules, all parts of the specification file are optional. The minimum lex specification file contains no definitions, no rules, and no user subroutines. Without a specified action for a pattern match, the lexical analyzer copies the input pattern to the output without changing it. Therefore, this minimum specification file produces a lexical analyzer that copies all input to the output unchanged.
You can define string macros before the first pair of percent signs in the lex specification file. The lex tool expands these macros when it generates the lexical analyzer. Any line in this section that begins in column 1 and that does not lie between %{ and %\} delimiters defines a lex substitution string. Substitution string definitions have the following general format:
name translation
The name and translation elements are separated by a least one blank or tab, and name begins with a letter. When lex finds the string name enclosed in braces ({}) in the rules part of the specification file, it changes name to the string defined in translation and deletes the braces.
For example, to define the names
D
and
E,
place the following definitions before the first
%%
delimiter in the specification file:
D [0-9]
E [DEde][-+]{D}+
These definitions can be used in the rules section to make
identification of integers and real numbers more compact:
{D}+ printf("integer");
{D}+"."{D}*({E})?|
{D}*"."{D}+({E})?|
{D}+{E} printf("real");
You can also include the following items in the definitions section:
The rules section of the specification file contains control decisions that define the lexical analyzer that lex generates. The rules are in the form of a two-column table. The left column of the table contains regular expressions; the right column of the table contains actions, one for each expression. Actions are C language program fragments that can be as simple as a semicolon (the null statement) or as complex as needed. The lexical analyzer that lex creates contains both the expressions and the actions; when it finds a match for one of the expressions, it executes the corresponding action.
For example, to create a lexical analyzer to look for the string
"integer" and print a message when the string is found, define the
following rule:
integer printf ("found keyword integer");
This example uses the C language library function
printf
to print a message string. The first blank or tab character in the
rule indicates the end of the regular expression. When you use only
one statement in an action, put the statement on the same line and to
the right of the expression
(integer
in this example). When you use more than one statement, or if the
statement takes more than one line, enclose the action in braces, as in
a C language program. For example:
integer {
printf ("found keyword integer");
hits++;
}
A lexical analyzer that changes some words in a file from British
spellings to the American spellings would have a specification file
that contains rules such as the following:
colour printf("color");
mechanise printf("mechanize");
petrol printf("gas");
This specification file is not complete, however, because it changes
the word "petroleum" to "gaseum".
With a few specialized additions, lex recognizes the standard set of extended regular expressions described in Chapter 1. Table 4-1 lists the expression operators that are special to lex.
| Operator | Name | Description |
| {name} | Braces | When braces enclose a name, the name represents a string defined earlier in the specification file. For example, {digit} looks for a defined string named digit and inserts that string at the point in the expression where {digit} occurs. Do not confuse this construct with an interval expression; both are recognized by lex. |
| Quotation marks | Encloses literal strings to interpret as text characters. For example, "$" prevents lex from interpreting the dollar sign as an operator. You can use quotation marks for only part of a string; for example, both "abc++" and abc"++" match the literal string "abc++". | |
| a/b | Slash | Enables a match on the first expression (a) only if the second expression (b) follows it immediately. For example, dog/cat matches "dog" if, and only if, "cat" immediately follows "dog". |
| <x> | Angle brackets | Encloses a start condition. Executes the associated action only if the lexical analyzer is in the indicated start condition <x>. If the condition of being at the beginning of a line is start condition ONE, then the circumflex (^) operator would be the same as the expression <ONE>. |
| \n | Newline character | Do not use the actual newline character in an expression. Do not confuse the \n construct with the \n back-reference operator used in basic regular expressions. |
| \t | Tab | Matches a literal tab character (09 hexadecimal)) |
| \b | Backspace | Matches a literal backspace (08 hexadecimal) |
| \\ | Backslash | Matches a literal backslash. |
| \digits | Digits | The character whose encoding is represented by the three digit octal number. |
| \xdigits | xDigits | The character whose encoding is represented by the hexadecimal integer. |
Usually, white space (blanks or tabs) delimits the end of an expression and the start of its associated action. However, you can enclose blanks or tab characters in quotation marks ("") to include them in an expression. Use quotation marks around all blanks in expressions that are not already within sets of brackets ([]).
When more than one expression in the rules section of a specification file can match the current input, the lexical analyzer chooses which rule to apply using the following criteria:
For example, consider the following rules:
integer printf("found int keyword");
[a-z]+ printf("found identifier");
If the rules are given in this order and "integers" is the input word, the analyzer calls the input an identifier because [a-z]+ matches all eight characters of the word while integer matches only seven. However, if the input is "integer", both rules match. In this case, lex selects the keyword rule because it occurs first. A shorter input, such as "int", does not match the expression integer, so lex selects the identifier rule.
Because the lexical analyzer chooses the longest match first, you must
be careful not to use an expression that is too powerful for your
intended purpose. For example, a period followed by an asterisk and
enclosed in apostrophes
('.*')
might seem like a good way to recognize any string enclosed in
apostrophes. However, the analyzer reads far ahead, looking for a
distant apostrophe to complete the longest possible match. Consider
the following text:
'first' quoted string here, 'second' here
Given this input, the analyzer will match on the following string:
'first' quoted string here, 'second'
Because the period operator does not match a newline character, errors
of this type are usually not far reaching. Expressions like
.*
stop on the current line. Do not try to defeat this action with
expressions like the following:
[.\n]+
Given this expression, the lexical analyzer tries to read the entire input file, and an internal buffer overflow occurs.
The following rule finds the smaller quoted strings "first" and
"second" from the preceding text example:
'[^'\n]*'"
This rule stops after matching "first" because it looks for an apostrophe followed by any number of characters except another apostrophe or a newline character, then followed by a second apostrophe. The analyzer then begins again to search for an appropriate expression, and it will find "second" as it should. This expression also matches an empty quoted string ('').
Usually, the lexical analyzer program partitions the input stream. It
does not search for all possible matches of each expression. Each
character is accounted for exactly once. For example, to count
occurrences of both "she" and "he" in an input text, consider
the following rules:
she s++; he h++; \n ; . ;
The last two rules ignore everything other than the two strings of interest. However, because "she" includes "he", the analyzer does not recognize the instances of "he" that are included within "she".
A special action,
REJECT,
is provided to override this behavior. This directive tells the
analyzer to execute the rule that contains it and then, before
executing the next rule, restore the position of the input pointer to
where it was before the first rule was executed. For example, to count
the instances of "he" that are included within "she", use the
following rules:
she {s++; REJECT;}
he {h++; REJECT;}
\n ;
. ;
After counting an occurrence of "she", the analyzer rejects the input stream and then counts the included occurrence of "he". In this example, "she" includes "he" but the reverse is not true, and you can omit the REJECT action on "he". In other cases, such as when a wildcard regular expression is being matched, determining which input characters are in both classes can be difficult.
In general, REJECT is useful whenever the purpose is not to partition the input stream but rather to detect all examples of some items in the input where the instances of these items can overlap or include each other.
When the lexical analyzer matches one of the expressions in the rules section of the specification file, it executes the action that corresponds to the expression. Without rules to match all strings in the input stream, the lexical analyzer copies the input to standard output. Therefore, do not create a rule that only copies the input to the output. Use this default output to find conditions not covered by the rules.
When you use a lex-generated analyzer to process input for a parser that yacc produces, provide rules to match all input strings. Those rules must generate output that yacc can interpret. For information on using lex with yacc, see Section 4.5.
To ignore the input associated with an expression, use a
semicolon
(;),
the C language null statement, as an action. For example:
[ \t\n] ;
This rule ignores the three spacing characters (blank, tab, and newline character).
To use the same action for several different expressions, create a
series of rules (one for each expression except the last) whose actions
consist of only a vertical bar character
(|).
For the last expression, specify the action as you would usually
specify it. The vertical bar character indicates that the action for
the rule containing it is the same as the action for the next rule.
For example, to ignore blank, tab, and newline characters (shown in
Section 4.3.2.3.1),
you could use the following set of rules:
" " | "\t" | "\n" ;
The quotation marks around the special character sequences (\n and \t) in this example are not mandatory.
To find out what text matched an expression in the rules section of the
specification file, include a C language
printf
function as one of the actions for that expression. When the lexical
analyzer finds a match in the input stream, the program puts that
matched string in an external character array, called
yytext.
To print the matched string, use a rule like the following:
[a-z]+ printf("%s", yytext);
Printing the output in this way is common. You can define an
expression like this
printf
statement as a macro in the definitions section of the specification
file. If this action is defined as
ECHO,
then the rules section entry looks like the following:
[a-z]+ ECHO;
See Section 4.3.1 for information on defining macros.
To find the number of characters that the lexical analyzer matched for
a particular expression, use the external variable
yyleng.
For example, the following rule counts both the number of words and
the number of characters in words in the input:
[a-zA-Z]+ {words++; chars += yyleng;}
This action totals the number of characters in the words matched and assigns that value to the chars variable.
The following expression finds the last character in the string
matched:
yytext[yyleng-1]
The lexical analyzer can run out of input before it completely matches an expression in a rules file. In this case, include a call to the lex function yymore in the action for that rule. Usually, the next string from the input stream overwrites the current entry in yytext. The yymore action appends the next string from the input stream to the end of the current entry in yytext. For example, consider a language that includes the following syntax:
The following rule processes these lexical characteristics:
\"[^"]* {
if (yytext[yyleng-l] == '\\')
yymore();
else
... normal user processing
}
When this lexical analyzer receives a string such as "abc\"def" (with the quotation marks exactly as shown), it first matches the first five characters, "abc\. The backslash causes a call to yymore to add the next part of the string, "def, to the end. The part of the action code labeled "normal user processing" must process the quotation mark that ends the string.
In some cases the lexical analyzer does not need all of the characters that are matched by the currently successful regular expression; or it might need to return matched characters to the input stream to be checked again for another match.
To return characters to the input stream, use the yyless(n) call, where n is the number of characters of the current string that you want to keep. Characters beyond the nth character in the stream are returned to the input stream. This function provides the same type of look-ahead that the slash operator (/) uses, but yyless allows more control over the look-ahead. Using yyless(0) is equivalent to using REJECT.
Use the
yyless
function to process text more than once. For example, a C
language expression such as
x=-a
is ambiguous. It could mean
x = -a,
or it could be an obsolete representation of
x -= a,
which is evaluated as
x = x - a.
To treat this ambiguous expression as
x = -a
and print a warning message, use a rule such as the following:
=-[a-zA-Z] {
printf("Operator (=-) ambiguous\n");
yyless(yyleng-1);
... action for =-...
}
The lex program provides a set of input/output (I/O) routines for the lexical analyzer to use. Include calls to the following routines in the C code fragments in your specification file:
These routines are provided as macro definitions. You can override them by writing your own code for routines of the same names in the user subroutines section. These routines define the relationship between external files and internal characters. If you change them, change them all in the same way. They should follow these rules:
If you write your own code, you must undefine these macros in the
definitions section of the specification file before the code for your
own definitions:
%{
#undef input
#undef unput
#undef output
}%
Note
Changing the relationship of unput to input causes the look-ahead functions not to work.
When you are using a lex-generated lexical analyzer as a simple transformer/recognizer for piping from standard input to standard output, you can avoid writing the "framework" by using the lex library (libl.a). This library contains the main routine, which calls the yylex function for you. The standard lex library lets the lexical analyzer back up a maximum of 100 characters.
If you need to be able to read an input file containing the NUL character (00 hexadecimal), you must create a different version of the input routine. The standard version of input returns a value of 0 when reading a null, and the analyzer interprets this value as indicating the end of the file.
The lexical analyzers that lex generates process character I/O through the input, output, and unput routines. Therefore, to return values in yytext, the analyzer uses the character representation that these routines use. Internally, however, each character is represented with a small integer. With the standard library, this integer is the value of the bit pattern that the computer uses to represent the character.
Usually, the letter "a" is represented in the same form as the character constant a. If you change this interpretation with different I/O routines, you must include a translation table in the definitions section of the specification file. The translation table begins and ends with lines that contain only the %T keyword, and it contains lines of the following form:
{integer} {character string}
The following example shows table entries that associate the letter
"A" and the digit "0" (zero) with their standard values:
%T
{65} {A}
{48} {0}
%T
When the lexical analyzer reaches the end of a file, it calls a library routine named yywrap. This routine returns a value of 1 to indicate to the lexical analyzer that it should continue with normal wrap-up (operations associated with the end of processing). However, if the analyzer receives input from more than one source, you must change the yywrap function. The new function must get the new input and return a value of 0 to the lexical analyzer. A return value of 0 indicates that the program should continue processing.
Multiple files specified on the command line are treated as a single input file for the purpose of end-of-file handling.
You can also include code to print summary reports and tables in a special version of yywrap. The yywrap function is the only way to force yylex to recognize the end of the input.
You can define variables in either the definitions section or the rules section of the specification file. When you process a specification file, lex changes statements in the file into a lexical analyzer. Any line in the specification file that lex cannot interpret is passed unchanged to the lexical analyzer. The following four types of entries can be passed to the lexical analyzer in this manner:
Any rule can be associated with a start condition; the lexical analyzer recognizes that rule only when the analyzer is in that start condition. You can change the current start condition at any time.
You define start conditions in the definitions section of the specification file by using a line with the following format:
% Start name1 [ name2 ... ]
The name1 and name2 symbols represent conditions. There is no limit to the number of conditions, and they can appear in any order. You can abbreviate Start to either S or s. Start-condition names cannot be reserved words in C, nor can they be declared as the names of variables, fields, and so on.
When using a start condition in the rules section of the specification file, enclose the name of the start condition in angle brackets (<>) at the beginning of the rule. The following format defines a rule with a start condition:
<name1 [ ,name2 ... ] > expression
The lexical analyzer
recognizes
expression
only when the analyzer is in the condition corresponding to one of the
names. To put
lex
in a particular start condition, execute the following action statement
(in the action part of a rule):
BEGIN
name;
This statement changes the start condition to
name.
To resume the normal state, use the following action:
BEGIN 0;
As shown in the preceding syntax diagram, a rule can be active in
several start conditions. For example:
<start1,start2,start3> [0-9]+ printf("integer");
This rule prints "integer" only if it finds an integer while in one of the three named start conditions. Any rule that does not begin with a start condition is always active.
Generating a lex-based lexical analyzer program is a two-step process, as follows:
For example, if the
lex
specification file is called
lextest,
enter the following commands:
%
lex lextest
%
cc lex.yy.c -ll
Although the default lex I/O routines use the C language standard library, the lexical analyzers that lex generates do not require them. You can include different copies of the input, output, and unput routines to avoid using those in the library. (See Section 4.3.3.)
Table 4-2 describes the options for the lex command.
| Option | Description |
| -n | Suppresses the statistics summary that is produced by default when you set your own table sizes for the finite state machine. See the lex(1) reference page for information about specifying the state machine. |
| -t | Writes the generated lexical analyzer code to standard output instead of to the lex.yy.c file. |
| -v | Provides a one-line summary of the general finite state machine statistics. |
Because lex uses fixed names for intermediate and output files, you can have only one lex-generated program in a given directory unless you use the -t option to specify an alternative file name.
When used alone, the lex tool creates a lexical analyzer that recognizes simple one-word input or receives statistical input. You can also use lex with a parser generator, such as yacc. The yacc tool generates a program, called a parser, that analyzes the construction of multiple-word input. This parser program operates well with lexical analyzers that lex generates; these lexical analyzers recognize only regular expressions and format them into character packages called tokens.
A token is the smallest independent unit of meaning as defined by either the parser or the lexical analyzer. A token can contain data, a language keyword, an identifier, or other parts of a language syntax. A token can be any string of characters; it can be part or all of a word or series of words. The yacc tool produces parsers that recognize many types of grammar with no regard to context. These parsers need a preprocessor, such as a lex-generated lexical analyzer, to recognize input tokens.
When a lex-generated lexical analyzer is used as the preprocessor for a yacc-generated parser, the lexical analyzer partitions the input stream. The parser assigns structure to the resulting pieces. Figure 4-2 shows how lex and yacc generate programs and how the programs work together. You can also use other programs along with those generated by lex or yacc.
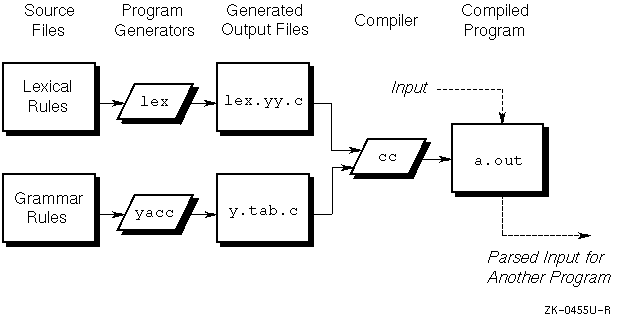
The parser program requires that its preprocessor (the lexical
analysis function) be named
yylex.
This is the name
lex
gives to the analysis code in a lexical analyzer it generates. If a
lexical analyzer is used by itself, the default
main
program in the
lex
library calls the
yylex
routine, but if a
yacc-generated
parser is loaded and its
main
program is used, the parser calls
yylex.
In this case, each
lex
rule should end with the following line, where the appropriate token
value is returned:
return(token);
To find the names for tokens that
yacc
uses, compile the lexical analyzer (the
lex
output file) as part of the parser (the
yacc
output file) by placing the following line in the last section of the
yacc
grammar file:
#include lex.yy.c
Alternatively, you can include the
yacc
output (the
y.tab.h
file) into your
lex
program specification file, and use the token names that
y.tab.h
defines. For example, if the grammar file is named
good
and the specification file is named
better,
the following command sequence creates the final program:
%
yacc good
%
lex better
%
cc y.tab.c -ly -ll
To get a main program that invokes the yacc parser, load the yacc library (-ly in the preceding example) before the lex library. You can generate lex and yacc programs in either order.
To generate a parser with yacc, you must write a grammar file that describes the input data stream and what the parser is to do with the data. The grammar file includes rules describing the input structure, code to be invoked when these rules are recognized, and a routine to do the basic input.
The yacc tool uses the information in the grammar file to generate yyparse, a program that controls the input process. This is the parser that calls the yylex input routine (the lexical analyzer) to pick up tokens from the input stream. The parser organizes these tokens according to the structure rules in the grammar file. The structure rules are called grammar rules. When the parser recognizes a grammar rule, it executes the user code (action) supplied for that rule. Actions return values and use the values returned by other actions.
In addition to the specifications that yacc recognizes and uses, the grammar file can also contain the following functions:
The function must return an integer that represents the kind of token that was read. The integer is called the token number. In addition, if a value is associated with the token, the lexical analyzer must assign that value to the external variable yylval. See Section 4.7.1.3 for more information on token numbers.
To build a lexical analyzer that works well with the parser that yacc generates, use the lex tool (see Section 4.3).
The yacc tool processes a grammar file to generate a file of C language functions and data, named y.tab.c. When compiled using the cc command, these functions form a combined function named yyparse. This yyparse function calls yylex, the lexical analyzer, to get input tokens.
The analyzer continues providing input until the parser detects an
error or the analyzer
returns an
endmarker
token to indicate the end of the operation. If an error occurs and
yyparse
cannot recover,
yyparse
returns a value of 1 to the
main
function. If it finds the
endmarker
token,
yyparse
returns a value of 0 to
main.
Use the C programming language to write the action code and other subroutines. The yacc program uses many of the C language syntax conventions for the grammar file.
You must provide function routines named
main
and
yyerror
in the grammar file. To ease the initial effort of using
yacc,
the
yacc
library provides simple versions of the
main
and
yyerror
routines. You can include these routines by using the
-ly
option to the loader or the
cc
command. The source code for the
main
library function is as follows:
main()
{
yyparse();
}
The source code for the
yyerror
library function follows:
#include <stdio.h>
void yyerror(s) char *s; { fprintf( stderr, " %s\n" ,s); }
The argument to yyerror is a string containing an error message, usually the string syntax error.
These are very limited programs. You should provide more sophistication in these routines, such as keeping track of the input line number and printing it along with the message when a syntax error is detected. You can use the value of the external integer variable yychar. This variable contains the look-ahead token number at the time the error was detected.
The yylex program input routine that you supply must be able to do the following:
A token is a symbol or name that tells yyparse which pattern is being sent to it by the input routine. A symbol can be in one of the following two classes:
For example, if the lexical analyzer recognizes any numbers, names, and operators, these elements are taken to be terminal symbols. Nonterminal symbols that the yacc grammar recognizes are elements like EXPR, TERM, and FACTOR. Suppose the input routine separates an input stream into the tokens of WORD, NUMBER, and PUNCTUATION. Consider the input sentence "I have 9 turkeys." The analyzer could pass the following strings and tokens to the parser:
| String | Token |
| I | WORD |
| have | WORD |
| 9 | NUMBER |
| turkeys | WORD |
| . | PUNCTUATION |
The yyparse function must contain definitions for the tokens that the input routine passes to it. The yacc command's -d option causes the program to generate a list of tokens in a file named .Nx r y.tab.h file list of tokens y.tab.h. This list is a set of #define statements that let yylex use the same tokens as the parser.
To avoid conflict with the parser, do not use names that begin with the letters yy. You can use lex to generate the input routine, or you can write it in the C language. See Section 4.3 for information about using lex.
A yacc grammar file consists of the following three sections:
Two percent signs (%%) that appear together separate the sections of the grammar file. To make the file easier to read, put the percent signs on a line by themselves. A grammar file has the following format:
[
declarations
]
%%
rules
[
%%
programs
]
Except for the first pair of percent signs
(%%),
which mark the beginning of the rules, and the rules themselves, all
parts of the grammar file are optional. The minimum
yacc
grammar file contains no definitions and no programs, as follows:
%% rules
Except within names or reserved symbols, the yacc program ignores blanks, tabs, and newline characters in the grammar file. You can use these characters to make the grammar file easier to read. Do not use blanks, tabs, or newline characters in names or reserved symbols.
The declarations section of the yacc grammar file contains the following elements:
Declarations for variables or constants conform to the syntax of the C programming language, as follows:
type-specifier declarator ;
In this syntax, type-specifier is a data type keyword and declarator is the name of the variable or constant. Names can be any length and can consist of letters, dots, underscores, and digits. A name cannot begin with a digit. Uppercase and lowercase letters are distinct. The names used in the body of a grammar rule can represent tokens or nonterminal symbols.
If you do not declare a name in the declarations section, you can use that name only as a nonterminal symbol. Define each nonterminal symbol by using it as the left side of at least one rule in the rules section. The #include statements are identical to C language syntax and perform the same function.
The yacc tool has a set of keywords, listed in Table 4-3, that define processing conditions for the generated parser. Each of the keywords begins with a percent sign (%) and is followed by a list of tokens.
| Keyword | Description |
| %left | Identifies tokens that are left-associative with other tokens. |
| %nonassoc | Identifies tokens that are not associative with other tokens. |
| %right | Identifies tokens that are right-associative with other tokens. |
| %start | Identifies a name for the start symbol. |
| %token | Identifies the token names that yacc accepts. Declare all token names in the declarations section. |
All tokens listed on the same line have the same precedence level and
associativity; lines appear in the file in order of increasing
precedence or binding strength. For example:
%left '+' '-' %left '*' '/'
This example describes the precedence and associativity of the four arithmetic operators. The addition (+) and subtraction (-) operators are left-associative and have lower precedence than the multiplication (*) and division (/) operators, which are also left-associative.
You can define global variables to be used by some or all parser
actions, as well as by the lexical analyzer, by enclosing the
declarations for those variables in matched pairs of symbols consisting
of a percent sign and a brace
(%{
and
%}).
For example, to make the
var
variable available to all parts of the complete program, place the
following entry in the declarations section of the grammar file:
%{ int var = 0; %}
The parser recognizes a special symbol called the start symbol. The start symbol is the name assigned to the grammar rule that describes the most general structure of the language to be parsed. Because it is the most general structure, it is the structure where the parser starts in its top-down analysis of the input stream. You declare the start symbol in the declarations section by using the %start keyword. If you do not declare a start symbol, the parser uses the name of the first grammar rule in the file.
For example, in parsing a C language procedure, the following is the
most general structure for the parser to recognize:
main()
{
code_segment
}
The start symbol should point to the rule that describes this structure. All remaining rules in the file describe ways to identify lower-level structures within the procedure.
Token numbers are nonnegative integers that represent the names of tokens. Because the lexical analyzer passes the token number to the parser instead of the actual token name, the programs must assign the same numbers to the tokens.
You can assign numbers to the tokens used in the yacc grammar file. If you do not assign numbers to the tokens, yacc assigns numbers using the following rules:
Note
Do not assign a token number of 0 (zero). This number is assigned to the endmarker token. You cannot redefine it.
To assign a number to a token (including literals) in the declarations section of the grammar file, put a nonzero positive integer immediately after the token name in the %token line. This integer is the token number of the name or literal. Each number must be unique. Any lexical analyzer used with yacc must return either 0 (zero) or a negative value for a token when the end of the input is reached.
The rules section of the yacc grammar file contains one or more grammar rules. Each rule describes a structure and gives it a name. A grammar rule has the following format:
nonterminal-name : BODY ;
In this syntax, BODY is a sequence of zero or more names and literals. The colon and the semicolon are required yacc punctuation.
If there are several grammar rules with the same nonterminal name, use
the vertical bar
(|)
to avoid rewriting the left side. In addition, use the semicolon
(;)
only at the end of all rules joined by vertical bars. The two
following sets of grammar rules are equivalent:
Set 1A : B C D ; A : E F ; A : G ;
Set 2
A : B C D | E F | G ;
To indicate a nonterminal symbol that matches the null string, use a
semicolon by itself in the body of the rule, as follows:
nullstr : ;
When the lexical analyzer reaches the end of the input stream, it sends a special token, called endmarker, to the parser. This token signals the end of the input and has a token value of 0. When the parser receives an endmarker token, it checks to see that it has assigned all of the input to defined grammar rules and that the processed input forms a complete unit (as defined in the yacc grammar file). If the input is a complete unit, the parser stops. If the input is not a complete unit, the parser signals an error and stops.
The lexical analyzer must send the endmarker token at the correct time, such as the end of a file, or the end of a record.
With each grammar rule, you can specify actions to be performed each time the parser recognizes the rule in the input stream. Actions return values and obtain the values returned by previous actions. The lexical analyzer can also return values for tokens.
An action is a C language statement that does input and output, calls
subprograms, and alters external vectors and variables. You specify an
action in the grammar file with one or more statements enclosed in
braces
({}).
For example, the following are grammar rules with actions:
A : '('B')'
{
hello(1, "abc" );
};
XXX : YYY ZZZ
{
printf("a message\n");
flag = 25;
}
An action can receive values generated by other actions by using
numbered
yacc
parameter keywords
($1,
$2,
and so on). These keywords refer to the values returned by the
components of the right side of a rule, reading from left to right.
For example:
A : B C D ;
When this code is executed, $1 has the value returned by the rule that recognized B, $2 the value returned by the rule that recognized C, and $3 the value returned by the rule that recognized D.
To return a value, the action sets the pseudovariable
$$
to some value. For example, the following action returns a value of 1:
{ $$ = 1;}
By default, the value of a rule is the value of the first element in it
($1).
Therefore, you do not need to provide actions for rules that have the
following form:
A : B ;
To get control of the parsing process before a rule is completed, write
an action in the middle of a rule. If this rule returns a value
through the
$n parameters, actions that come after it can use that value. The action
can use values returned by actions that come before it. Therefore, the
following rule sets
x
to 1
and
y
to the value returned by
C:
A : B
{
$$ =1;
}
C
{
x = $2;
y = $3;
}
;
Internally,
yacc
creates a new nonterminal symbol name for the action that occurs in the
middle, and it creates a new rule matching this name to the null
string. Therefore,
yacc
treats the preceding program as if it were written in the following
form, where
$ACT
is an empty action:
$ACT : /* null string */
{
$$ = 1;
}
;
A : B $ACT C
{
x = $2;
y = $3;
}
;
The programs section of the yacc grammar file contains C language functions that can be used by the actions in the rules section. In addition, if you write a lexical analyzer (yylex, the input routine to the parser), include it in the programs section.
The following sections describe some general guidelines for using yacc grammar files. They provide information on the following:
Comments in the grammar file explain what the program is doing. You
can put comments anywhere in the grammar file that you can put a name.
However, to make the file easier to read, put the comments on lines by
themselves at the beginning of functional blocks of rules. Comments in
a
yacc
grammar file have exactly the same form as comments in a C language
program; that is, they begin with a slash and an asterisk
(/*)
and end with an asterisk and a slash
(*/).
For example:
/* This is a comment on a line by itself. */
A literal string is one or more characters enclosed in apostrophes, or single quotation marks (''). As in the C language, the backslash (\) is an escape character within literals, and all the C language special-character sequences are recognized, as follows:
| \n | Newline character |
| \r | Return |
| \' | Apostrophe, or single quote |
| \\ | Backslash |
| \t | Tab |
| \b | Backspace |
| \f | Form feed |
| \nnn | The value nnn in octal |
Never use \0 or 0 (the null character) in grammar rules.
The following guidelines will help make the yacc grammar file more readable:
Recursion is the process of using a function to define itself. In
language definitions, these rules usually take the following form:
rule : end case
| rule, end case
The simplest case of rule is the end case, but rule can also be made up of more than one occurrence of end case. The entry in the second line that uses rule in the definition of rule is the instance of recursion. Given this rule, the parser cycles through the input until the stream is reduced to the final end case.
The
yacc
tool supports left-recursive grammar, not right-recursive. When you
use recursion in a rule, always put the call to the name of the rule as
the leftmost entry in the rule (as it is in the preceding example). If
the call to the name of the rule occurs later in the line, as in the
following example, the parser can run out of internal stack space and
crash:
rule : end case
| end case, rule
The yacc tool cannot produce a parser for all sets of grammar specifications. If the grammar rules contradict themselves or require matching techniques different from those that yacc has, yacc will not produce a parser. In most cases, yacc provides messages to indicate the errors. To correct these errors, redesign the rules in the grammar file or provide a lexical analyzer to recognize the patterns that yacc cannot handle.
When the parser reads an input stream, that input stream can fail to match the rules in the grammar file. If there is an error-handling routine in the grammar file, the parser can allow for entering the data again, skipping over the bad data, or for a cleanup and recovery action. When the parser finds an error, for example, it might need to reclaim parse tree storage, delete or alter symbol table entries, and set switches to avoid generating any further output.
When an error occurs, the parser stops unless you provide error-handling routines. To continue processing the input to find more errors, restart the parser at a point in the input stream where the parser can try to recognize more input. One way to restart the parser when an error occurs is to discard some of the tokens following the error, and try to restart the parser at that point in the input stream.
The yacc tool has a special token name, error, to use for error handling. Put this token in your grammar file at places where an input error might occur so that you can provide a recovery routine. If an input error occurs in a position protected by the error token, the parser executes the action for the error token rather than the normal action.
To prevent a single error from producing many error messages, the
parser remains in an error state until it successfully processes three
tokens following an error. If another error occurs while the parser is
in the error state, the parser discards the input token and does not
produce a message. You can also specify a point at which the parser
should resume processing by providing an argument to the
error
action. For example:
stat : error ';'
This rule tells the parser that, when there is an error, it should skip over the token and all following tokens until it finds the next semicolon. All tokens after the error and before the next semicolon are discarded. When the parser finds the semicolon, it reduces this rule and performs any cleanup action associated with it.
You can allow the person entering the input stream in an interactive
environment to correct any input errors by reentering a line in the
data stream. For example:
input : error '\n'
{
printf(" Reenter last line: " );
}
input
{
$$ = $4;
}
;
In the previous example the parser stays in the error state for three
input tokens following the error. If an error is encountered in the
first three tokens, the parser deletes the tokens and does not
display a message. Use the
yyerrok;
statement for recovery. When the parser encounters the
yyerrok;
statement, it leaves the error state and begins normal processing.
Follwoing is the recovery example:
input : error '\n'
{
yyerrok;
printf( "Reenter last line: " );
}
input
{
$$ = $4
}
;
The look-ahead token is the next token to be examined by the parser. When an error occurs, the look-ahead token becomes the token at which the error was detected. However, if the error recovery action includes code to find the correct place to start processing again, that code must also change the look-ahead token. To clear the look-ahead token, include the yyclearin; statement in the error recovery action.
The yacc program turns the grammar file into a C language program that, when compiled and executed, parses the input according to the grammar rules.
The parser is a finite state machine with a stack. The parser can read and remember the next input token (the look-ahead token). The current state is always the state that is on the top of the stack. The states of the finite state machine are represented by small integers. Initially, the machine is in state 0 (zero), the stack contains only 0 (zero), and no look-ahead token has been read.
The machine can perform one of the following four actions:
| shift n | The parser pushes the current state onto the stack, makes n the current state, and clears the look-ahead token. |
| reduce r | The r argument is a rule number. When the parser finds a token sequence matching rule number r in the input stream, the parser replaces that sequence with the rule number in the output stream. |
| accept | The parser has looked at all input, matched it to the grammar specification, and recognized the input as satisfying the highest level structure (defined by the start symbol). This action appears only when the look-ahead token is the end marker and indicates that the parser has successfully done its job. |
| error | The parser cannot continue processing the input stream and still successfully match it with any rule defined in the grammar specification. The input tokens it looked at, together with the look-ahead token, cannot be followed by anything that would result in a legal input. The parser reports an error and attempts to recover the situation and resume parsing. |
The parser performs the following actions during one process step:
The
shift
action is the most common action the parser takes. Whenever the parser
does a
shift,
there is always a look-ahead token. Consider the following parser
action rule:
IF shift 34
When the parser is in the state that contains this rule and the look-ahead token is IF, the parser performs the following steps:
The reduce action prevents the stack from growing too large. The parser uses reducing actions after it has matched the right side of a rule with the input stream and is ready to replace the tokens in the input stream with the left side of the rule. The parser might have to use the look-ahead token to decide if the pattern is a complete match.
Reducing actions are associated with individual grammar rules. Because
grammar rules also have small integer numbers, you can easily confuse
the meanings of the numbers in the
shift
and
reduce
actions. For example, the first of the two
following actions refers to
grammar rule 18; the second refers to machine state 34:
reduce 18 IF shift 34
For example, consider reducing the following rule:
A : x y z ;
The parser pops off the top three states from the stack. The number of states popped equals the number of symbols on the right side of the rule. These states are the ones put on the stack while recognizing x, y, and z. After popping these states, the parser uncovers the state the parser was in before beginning to process the rule (the state that needed to recognize rule A to satisfy its rule). Using this uncovered state and the symbol on the left side of the rule, the parser performs a goto action, which is similar to a shift of A. A new state is obtained and pushed onto the stack, and parsing continues.
The
goto
action is different from an ordinary
shift
of a token. The look-ahead token is cleared by a
shift
but is not affected by a
goto.
When the three states are popped in this example, the uncovered state
contains an entry such as the following:
A goto 20
This entry causes state 20 to be pushed onto the stack and become the current state.
The reduce action is also important in the treatment of user-supplied actions and values. When a rule is reduced, the parser executes the code that you included in the rule before adjusting the stack. In addition to the stack holding the states, another stack running in parallel with it holds the values returned from the lexical analyzer and the actions. When a shift takes place, the external variable yylval is copied onto the value stack. After executing the code that you provide, the parser performs the reduction. When the parser performs the goto action, it copies the external variable yylval onto the value stack. The yacc variables whose names begin with a dollar sign ($) refer to the value stack.
A set of grammar rules is ambiguous if any possible input string can be
structured in two or more different ways. For example:
expr : expr '-' expr
This rule forms an arithmetic expression by putting
two other expressions together with a minus sign between them, but
this grammar rule does not specify how to structure all complex inputs.
For example:
expr - expr - expr
Using the preceding rule, a program could structure this input as
either left-associative or right-associative:
( expr - expr ) - expror
expr - ( expr - expr )
These two forms produce different results when evaulated.
When the parser tries to handle an ambiguous rule, it can become confused over which of its four actions to perform when processing the input. The following two types of conflicts develop:
| Shift/reduce conflict | A rule can be evaluated correctly using either a shift action or a reduce action, with different results. |
| Reduce/reduce conflict | A rule can be evaluated correctly using one of two different reduce actions, producing two different actions. |
A shift/shift conflict is not possible.
These conflicts result when a rule is not as complete as it could
be. For example, consider the following input and the preceding
ambiguous rule:
a - b - c
After reading the first three parts of the input, the parser has the
following:
a - b
This input matches the right side of the grammar rule. The parser can
reduce the input by applying this rule. After applying the rule, the
input becomes the following:
expr
This is the left side of the rule. The parser then reads the final
part of the input, as follows:
- c
The parser now has the following:
expr - c
Reducing this input produces a left-associative interpretation.
However, the parser can also look ahead in the input stream. If, after
receiving the first three parts of the input, it continues reading the
input stream until it has the next two parts, it then has the following
input:
a - b - c
Applying the rule to the rightmost three parts reduces
b - c
to
expr.
The parser then has the following:
a - expr
Reducing the expression once more produces a right-associative interpretation.
Therefore, at the point where the parser has read the first three parts, it can take one of two legal actions: a shift or a reduce. If the parser has no rule by which to decide between the actions, a shift/reduce conflict results.
A similar situation occurs if the parser can choose between two valid reduce actions. That situation is called a reduce/reduce conflict.
When shift/reduce or reduce/reduce conflicts occur, yacc produces a parser by selecting a valid step wherever it has a choice. If you do not provide a rule to make the choice, yacc uses the following rules:
Using actions within rules can cause conflicts if the action must be done before the parser can be sure which rule is being recognized. In these cases, using the preceding rules leads to an incorrect parser. For this reason, yacc reports the number of shift/reduce and reduce/reduce conflicts that it has resolved by applying its rules.
For normal operation, the external integer variable yydebug is set to 0. However, if you set it to any nonzero value, the parser generates a running description of the input tokens that it receives and the actions that it takes for each token. You can set the yydebug variable in one of the following two ways:
yydebug = 1;
You can use the programs for a lex-generated lexical analyzer and a yacc-generated parser, shown in Example 4-1 and Example 4-2, to create a simple desk calculator program that performs addition, subtraction, multiplication, and division operations. The calculator program also lets you assign values to variables (each designated by a single lowercase letter) and then use the variables in calculations. The files that contain the programs are as follows:
By convention, lex and yacc programs use the letters .l and .y respectively as file name suffixes. Example 4-1 and Example 4-2 contain the program fragments exactly as they should be entered.
The following processing instructions assume that the files are in your current directory; perform the steps in the order shown to create the calculator program using lex and yacc:
%
yacc -d calc.y
This command creates the following files:
%
lex calc.l
This command creates the lex.yy.c file, containing the C language source file that lex created for the lexical analyzer.
%
cc -o calc y.tab.c lex.yy.c
You can run the program by entering the
calc
command. You can then enter numbers and operators in algebraic
fashion. After you press Return, the program displays the result of
the operation. You can assign a value to a variable as follows:
m=4
You can use variables in calculations as follows:
m+5
9
Example 4-1 shows the contents of the calc.y file. This file has entries in all three of the sections of a yacc grammar file: declarations, rules, and programs. The grammar defined by this file supports the usual algebraic hierarchy of operator precedence.
Descriptions of the various elements of the file and their functions
follow the example.
%{
#include <stdio.h> [1]
int regs[26]; [2]
int base;
%}
%start list [3]
%token DIGIT LETTER [4]
%left '|' [5]
%left '&'
%left '+' '-'
%left '*' '/' '%'
%left UMINUS /*supplies precedence for unary minus */
%% /* beginning of rules section */
list: /*empty */
| list stat'\n'
| list error'\n'
{
yyerrok;
}
;
stat: expr
{
printf("%d\n",$1);
}
|
LETTER '=' expr
{
regs[$1] = $3;
}
;
expr: '(' expr ')'
{
$$ = $2;
}
|
expr '*' expr
{
$$ = $1 * $3;
}
|
expr '/' expr
{
$$ = $1 / $3;
}
|
expr '%' expr
{
$$ = $1 % $3;
}
|
expr '+' expr
{
$$ = $1 + $3;
}
|
expr '-' expr
{
$$ = $1 - $3;
}
|
expr '&' expr
{
$$ = $1 & $3;
}
|
expr '|' expr
{
$$ = $1 | $3;
}
|
'-' expr %prec UMINUS
{
$$ = -$2;
}
|
LETTER
{
$$ = regs[$1];
}
|
number
;
number: DIGIT
{
$$ = $1;
base = ($1==0) ? 8:10;
}
|
number DIGIT
{
$$ = base * $1 + $2;
}
;
%%
main()
{
return(yyparse());
}
yyerror(s)
char *s;
{
fprintf(stderr," %s\n",s);
}
yywrap()
{
return(1);
}
The declarations section contains entries that perform the following functions:
The rules section defines the rules that parse the input stream.
The programs section contains the following routines. Because these routines are included in this file, you do not need to use the yacc library when processing this file.
![]()
Example 4-2
shows the contents of the
calc.l
file. This file contains
#include
statements for standard input and output and for the
y.tab.h
file, which is generated by
yacc
before you run
lex
on
calc.l.
The
y.tab.h
file defines the tokens that the parser program uses.
Also,
calc.l
defines the rules to generate the tokens from the input stream.
%{
#include <stdio.h>
#include "y.tab.h"
int c;
extern int yylval;
%}
%%
" " ;
[a-z] {
c = yytext[0];
yylval = c - 'a';
return(LETTER);
}
[0-9] {
c = yytext[0];
yylval = c - '0';
return(DIGIT);
}
[^a-z0-9\b] {
c = yytext[0];
return(c);
}