B Contents of Japanese Locale Definitions
The Tru64 UNIX operating system offers the following Japanese locales:
ja_JP.eucJP, ja_JP.SJIS, ja_JP.deckanji, ja_JP.sdeckanji, and UTF-8.
The contents
of the definitions of the four ja_JP.* Japanese locales are identical, except
for the codeset-dependent definitions.
The Japanese locales meet the definitions
in the UI-OSF Japanese Environment Installation Conventions (1993).
This chapter describes the definitions of CHARMAP, LC_CTYPE, LC_COLLATE,
LC_MESSAGES, LC_MONETARY, LC_NUMERIC, and LC_TIME environment variables.
For
details on the meanings of items and keywords defined in the locale, see
charmap(4)
and
locale(4).
B.1 CHARMAP
The
charmap
file referenced during creation of a
locale database exists for each of the codesets.
It describes the correspondence
between the symbolic names and code values that are used for the codeset attributes
and locale definitions.
Table B-1
lists the attributes
of the Japanese codesets that are displayed with the
locale -k CHARMAP
command.
The attributes are listed by
charmap
file keyword.
In the table,
code_set_name
is the value
of the locale in program execution.
To obtain the appropriate value, invoke
n1_langinfo(CODESET).
Table B-1: Japanese Codeset Attributes
| Attributes |
Japanese EUC |
Shift JIS |
DEC Kanji |
Super DEC Kanji |
UTF-8 |
| code_set_name |
"eucJP" |
"SJIS" |
"deckanji" |
"sdeckanji" |
"UTF-8" |
| mb_cur_max |
3 |
2 |
2 |
3 |
3 |
| mb_cur_min |
1 |
1 |
1 |
1 |
1 |
B.2 LC_TYPE
The LC_TYPE environment variable contains the definitions for the character
class that determines the action of the
isw*()
function.
It also contains the character conversion information that determines the
action of
tow*()
function.
There are two categories of character classes: standard and extended.
The standard character classes are specified in standard specifications such
as the Programming Language C and POSIX standards.
These classes always exist
in a system conforming to the standard of XPG4 or POSIX.
The extended character classes include required character classes that
are also defined for each of the locales.
These classes include those character
classes required for the Japanese locales that are not specified in the standard
specification.
Table B-2
summarizes the contents of the definitions
of the standard character classes.
Table B-3
summarizes
the contents of the definitions of the extended character classes.
(For UTF-8,
no extended character classes are undefined.) To make a decision for an extended
character class by using a program, combine the
wctype()
and
iswctype()
functions.
Table B-2: Standard Character Classes
| Character Class
Name |
Contents of Definition |
| upper |
ASCII 'A' to 'Z', JIS X 0208 Roman
uppercase characters, JIS X 0208 Greek uppercase characters, JIS X 0208 Russian
uppercase characters, JIS X 0212 Greek uppercase characters with diacritical
marks, JIS X 0212 Cyrillic alphabetic uppercase character, JIS X 0212 Latin
Alphabetic lowercase characters, JIS X 0212 Latin Alphabetic uppercase characters
with diacritical marks |
| lower |
ASCII 'a' to 'z', JIS X 0208 Roman
lowercase characters, JIS X 0208 Greek lowercase characters, JIS X 0208 Russian
lowercase characters, JIS X 0212 Greek lowercase characters with diacritical
marks, JIS X 0212 Cyrillic alphabetic lowercase characters, JIS X 0212 Latin
Alphabetic lowercase characters, JIS X 0212 Latin Alphabetic lowercase characters
with diacritical marks |
| alpha |
Characters defined in upper and
lower |
| digit' |
ASCII '0' to '9' |
| space |
ASCII ' ', '\t' (0/9), '\n' (0/10),
'\/v' (0/11), '\f' (0/12), '\r (0/13)', and space in JIS X 0208 (1st Ku, 1st
Ten) |
| cntrl |
C0 and C1 control characters (except
SS2 and SS3 for eucJP and sdeckanji) |
| punct |
ASCII '!' (2/1) to '/' (2/15), ':' (3/10) to '@' (4/0), '['
(5/11) to '`' (6/0), '{' (7/11) to '~' (7/14)
JIS X 0208 '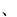 ' (1st Ku,
2nd Ten) to ' ' (1st Ku,
2nd Ten) to '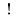 ' (1st Ku, 10th Ten),
' ' (1st Ku, 10th Ten),
'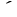 ' (1st Ku, 13th Ten) to ' ' (1st Ku, 13th Ten) to ' ' (1st Ku, 18th Ten), ' ' (1st Ku, 18th Ten), '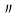 '
(1st Ku, 23rd Ten), ' '
(1st Ku, 23rd Ten), '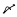 ' (1st Ku, 26th
Ten), ' ' (1st Ku, 26th
Ten), '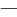 ' (1st Ku, 29th Ten), to ' ' (1st Ku, 29th Ten), to ' ' (1st Ku, 94th Ten) ' (1st Ku, 94th Ten)
JIS X 0201 RH Kuten (2/1), left parenthesis (2/2), right parenthesis
(2/3), Touten (2/4), Nakaten (2/5)
JIS X 0202 diacritical marks (2nd Ku, 15th Ten to 25th Ten),
description symbols (2nd Ku, 34th Ten; 2nd Ku, 36th Ten), unit symbol (2nd
Ku, 80th Ten), ordinary symbols (2nd Ku, 35 Ten; 75th to 79th Ten, 81st Ten)
|
| graph |
Characters included in ASCII upper, lower, digit, and punct
All characters (including undefined fields) other than JIS
X 0208 space
All JIS X 0212 RH characters (2/1 to 5/15)
All JIS X 0212 characters (including undefined fields)
All characters in the user-defined character fields
|
| print |
|
| xdigit |
ASCII '0' to '9', 'a' to
'f', 'A' to 'F' |
| blank |
ASCII '2/0', '\t' (0/9)
|
Table B-3: Extended Character Classes
| Character Class
Name |
Contents of Definition |
| ascii |
All ASCII characters |
| line |
JIS X 0208 ruled lines (8th Ku,
1st Ten to 8th Ku, 32nd Ten) |
| jdigit |
JIS X 0208 digits ('0' to '9') |
| paren |
ASCII '(', ')', '[', ']', '{', '}'
JIS X 0208 aggregation signs (1st Ku, 38th Ten to 1st Ku,
59th Ten)
JIS X 0201 RH left parenthesis (2/2), right parenthesis (2/3)
|
| jparen |
JIS X 0208 aggregation signs (1st Ku, 38th Ten to 1st Ku,
59th Ten)
JIS X 0201 RH left parenthesis (2/2), right parenthesis (2/3)
|
| jisx0201 |
All JIS X 0201 characters
|
| jisx0201r |
All JIS X 0201 RH characters
|
| jisx0208 |
All JIS X 0208 characters
(JIS-defined fields only) |
| jisx0212 |
All JIS X 0212 characters
(JIS-defined fields only) |
| udc |
User-defined characters |
| vdc |
Vendor-defined characters (undefined
because this does not exist in Tru64 UNIX) |
| gaiji |
User- and vendor-defined characters |
| jhira |
JIS X 0208 '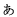 '
(4th Ku, 1st Ten) to ' '
(4th Ku, 1st Ten) to '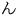 ' (4th Ku, 83rd
Ten), ' ' (4th Ku, 83rd
Ten), '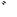 ' (1st Ku, 11th Ten), ' ' (1st Ku, 11th Ten), '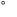 ' (1st Ku, 12th Ten), ' ' (1st Ku, 12th Ten), '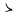 '(1st
Ku, 21st Ten), ' '(1st
Ku, 21st Ten), '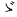 '(1st Ku, 22nd Ten),
' '(1st Ku, 22nd Ten),
'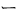 '(1st Ku, 28th Ten) '(1st Ku, 28th Ten) |
| jkata |
JIS X 0208 ] '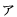 '
(5th Ku, 1st Ten) to ' '
(5th Ku, 1st Ten) to '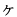 ' (5th Ku, 86th
Ten), '' (1st Ku, 11th Ten), '' (1st Ku, 12th Ten), ' ' (5th Ku, 86th
Ten), '' (1st Ku, 11th Ten), '' (1st Ku, 12th Ten), '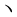 '
(1st Ku, 19th Ten), ' '
(1st Ku, 19th Ten), '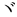 '(1st Ku, 20th
Ten), '' (1st Ku, 28th Ten) '(1st Ku, 20th
Ten), '' (1st Ku, 28th Ten) |
| jhankana |
JIS X 0201 RH Katakana (2/6 to
5/13), voiced sound symbol (5/14), semivoiced sound symbol (5/15) |
| jkanji |
JIS X 0208 Kanji (16th to 84th JIS-defined characters), ' ' (1st Ku, 24 Ten), ' ' (1st Ku, 24 Ten), '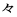 '
(1st Ku, 25 Ten), ' '
(1st Ku, 25 Ten), ' ' (1st Ku, 27 Ten) ' (1st Ku, 27 Ten)
JIS X 0212 Kanji (16th to 77th Ku JIS-defined characters)
|
| jspace |
JIS X 0208 space (1st Ku,
1st Ten) |
| english |
JIS X 0208 'A' to 'Z', 'a' to
'z' |
| number |
JIS X 0208 '0' to '9' |
| special |
JIS X 0208 special characters
(1st to 2nd Ku JIS-defined characters) |
| phonogram |
JIS X 0208 ''
(4th Ku, 1st Ten) to '' (4th Ku, 83rd
Ten), '' (5th Ku, 1st Ten) to '' (5th Ku, 86th Ten) |
| ideogram |
All JIS X 0208 characters (including
undefined JIS fields) |
The LC_TYPE environment variable defines the correspondence between
uppercase and lowercase characters referenced from the
towupper()
and
towlower()
functions.
The following list
describes the alphabetic characters defined in
toupper()
and
tolower().
ASCII Roman characters (lowercase 'a' to 'z' <==>
uppercase
'A' to 'Z')
JIS X 0208 Roman characters (lowercase 'a' to 'z' <==>
uppercase 'A' to 'Z')
JIS X 0208 Greek characters (lowercase '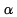 '
to '
'
to '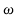 ' <==>
uppercase '
' <==>
uppercase '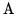 ' to '
' to '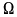 ')
')
JIS X 0208 Russian characters (lowercase '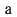 ' to '
' to '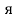 ' <==>
uppercase '
' <==>
uppercase '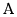 ' to '
' to '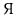 ')
')
JIS X 0212 Greek alphabet with diacritical marks
JIS X 0212 Cyrillic alphabet
JIS X 0212 Latin alphabet
JIS X 0212 Latin alphabet with diacritical marks
B.3 LC_COLLATE
The LC_COLLATE environment variable contains the definitions for the
character collating sequence.
The collating sequence for the characters defined
in the Japanese locales uses the following order:
ASCII characters
JIS X 0201 RH characters
JIS X 0208 characters (including undefined JIS fields)
JIS X 0221 characters (including undefined JIS fields)
User-defined characters of DEC Extended Kanji fields
In each character set, the characters are sequenced in ascending order
of the codes.
B.4 LC_MESSAGES
When you enter a character string to a question that forces a selection
of either YES (affirmative) or NO (negative), the LC_MESSAGES environment
variable defines which character string is affirmative and which is negative.
Use a regular expression for this definition.
In the Japanese locales, the
following definitions have been adopted:
Any character string beginning with 'y' or 'Y' in the ASCII
or JIS X 0208 alphabet is determined as YES.
Any character string beginning with 'n' or 'N' in the ASCII
or JIS X 0208 alphabet is determined as NO.
Table B-4
summarizes the contents of the definitions
of LC_MESSAGES.
Table B-4: LC_MESSAGES Definitions
| Keyword |
Contents of Definition |
| yesexpr |
"^[yY£ù£Ù]" |
| noexpr |
"^[nN£î£Î]" |
B.5 LC_MONETARY
The LC_MONETARY environment variable contains the definitions of the
characters and rules that are used to represent an amount of money.
Table B-5
summarizes the contents of the LC_MONETARY definitions.
Table B-5: Definitions of LC_MONETARY
| Keyword |
Contents of Definition |
| int_curr_symbol |
"JPY " |
| currency_symbol |
"¥" |
| mon_decimal_point |
"" |
| mon_thousands_sep |
"," |
| mon_grouping |
3 |
| positive_sign |
"" |
| negative_sign |
"-" |
| int_frac_digits |
0 |
| frac_digits |
0 |
| p_cs_precedes |
1 |
| p_sep_by_space |
0 |
| n_cs_precedes |
1 |
| n_sep_by_space |
0 |
| p_sign_posn |
1 |
| n_sign_posn |
4 |
B.6 LC_NUMERIC
The LC_NUMERIC environment variable contains the definitions of the
characters and rules that are used to represent numeric values other than
an amount of money.
Table B-6
summarizes the contents
of the LC_NUMERIC definitions.
Table B-6: Definitions of LC_NUMERIC
| Keyword |
Contents of Definition |
| decimal_point |
"." |
| thousands_sep |
"," |
| grouping |
3 |
B.7 LC_TIME
The LC_TIME environment variable contains the definitions of the character
strings and rules that are used to represent date and time information.
The
following table summarizes the contents of the LC_TIME definitions.
The contents
of the definitions of each keyword are referenced from the conversion specification
for the
strftime()
function listed in the table.
