Clustered systems share various data and system resources, such as access to disks and files. To achieve the coordination that is necessary to maintain resource integrity, the cluster must have clear criteria for membership and must disallow participation in the cluster by systems that do not meet those criteria.
This section provides the following information:
An overview of the connection manager functions (Section 4.1)
A discussion of quorum, votes, and cluster membership (Section 4.2)
A discussion of how the connection manager calculates quorum (Section 4.3)
An example using a three-member cluster (Section 4.4)
When and how to use a quorum disk (Section 4.5)
How to use the
clu_quorum
command to display cluster
quorum information (Section 4.6)
Examples that illustrate the results of various vote settings (Section 4.7)
How to monitor the connection manager (Section 4.8)
How to interpret connection manager panics (Section 4.9)
How to troubleshoot unfortunate expected vote and node vote settings (Section 4.10)
The connection manager is a distributed kernel component that monitors whether cluster members can communicate with each other, and enforces the rules of cluster membership. The connection manager:
Forms a cluster, adds members to a cluster, and removes members from a cluster
Tracks which members in a cluster are active
Maintains a cluster membership list that is consistent on all cluster members
Provides timely notification of membership changes using Event Manager (EVM) events
Detects and handles possible cluster partitions
An instance of the connection manager runs on each cluster member.
These
instances maintain contact with each other, sharing information such as
the cluster's membership list.
The connection manager uses a three-phase
commit protocol to ensure that all members have a consistent view of the
cluster.
4.2 Quorum and Votes
The connection manager ensures data integrity in the face of communication failures by using a voting mechanism. It allows processing and I/O to occur in a cluster only when a majority of votes are present. When the majority of votes are present, the cluster is said to have quorum.
The mechanism by which the connection manager calculates quorum and allows
systems to become and remain clusters members depends on a number of
factors, including expected votes, current votes, node votes, and quorum
disk votes.
This section describes these concepts.
4.2.1 How a System Becomes a Cluster Member
The connection manager is the sole arbiter of cluster membership.
A node
that has been configured to become a cluster member, either through the
clu_create
or
clu_add_member
command,
does not become a cluster member until it has rebooted with a clusterized
kernel and is allowed to form or join a cluster by the connection manager.
The difference between a cluster member
and a node that is configured to become a cluster member is important in any
discussion of quorum and votes.
After a node has formed or joined a cluster, the connection manager forever
considers it to be a cluster member (until someone uses
clu_delete_member
to remove it from the cluster).
In rare cases a disruption of communications
in a cluster (such as that caused by
broken or disconnected hardware) might cause an
existing cluster to divide into two or more clusters.
In such a case,
which is known as a
cluster partition,
nodes may consider themselves to be members of one cluster or
another.
However, as discussed in
Section 4.3,
the connection manager at most allows only
one of these clusters to function.
4.2.2 Expected Votes
Expected votes are the number of votes that the connection manager expects when all configured votes are available. In other words, expected votes should be the sum of all node votes (see Section 4.2.4) that are configured in the cluster, plus the vote of the quorum disk, if one is configured (see Section 4.2.5). Each member brings its own notion of expected votes to the cluster; it is important that all members agree on the same number of expected votes.
The connection manager refers to the node expected votes settings of booting cluster members to establish its own internal clusterwide notion of expected votes, which is referred to as cluster expected votes. The connection manager uses its cluster expected votes value to determine the number of votes the cluster requires to maintain quorum, as explained in Section 4.3.
Use the
clu_quorum
or
clu_get_info
-full
command to display the current value
of cluster expected votes.
The
clu_create
and
clu_add_member
scripts automatically adjust each member's expected votes as a new voting
member or quorum disk is configured in the cluster.
The
clu_delete_member
command automatically lowers expected
votes when a member is deleted.
Similarly, the
clu_quorum
command adjusts each member's expected votes
as a quorum disk is added or deleted or node votes are assigned to or
removed from a member.
These commands ensure that the member-specific
expected votes value is the same on each cluster member and that
it is the sum of all
node votes and the quorum disk vote (if a quorum disk is configured).
A member's expected votes are initialized from the
cluster_expected_votes
kernel attribute in the
clubase
subsystem of its
member-specific
etc/sysconfigtab
file.
Use the
clu_quorum
command
to display a member's expected votes.
To modify a
member's expected votes, you must use the
clu_quorum -e
command.
This ensures that
all members have the same and correct expected
votes settings.
You cannot modify the
cluster_expected_votes
kernel
attribute directly.
4.2.3 Current Votes
If expected votes are the number of configured votes in a cluster,
current votes
are the number of votes
that are contributed by current members and any configured quorum disk that
is on line.
Current votes are the actual number of votes that are
visible within the cluster.
4.2.4 Node Votes
Node votes are the fixed number of votes that a given member contributes towards quorum. Cluster members can have either 1 or 0 (zero) node votes. Each member with a vote is considered to be a voting member of the cluster. A member with 0 (zero) votes is considered to be a nonvoting member.
Note
Single-user mode does not affect the voting status of the member. A member contributing a vote before being shut down to single-user mode continues contributing the vote in single-user mode. In other words, the connection manager still considers a member that is shut down to single-user mode to be a cluster member.
Voting members can form a cluster. Nonvoting members can only join an existing cluster.
You typically assign votes to a member during cluster configuration; for
example, while running
clu_create
to create the first
cluster member or running
clu_add_member
to add new
members.
By default,
clu_create
gives the first
member 1 vote.
By default, the number of votes
clu_add_member
offers for new potential members
is 0 (zero) if expected votes is 1, or 1 if expected votes is greater
than 1.
(clu_create
and
clu_add_member
automatically increment expected
votes when configuring a new vote in the cluster.)
You can later adjust the number of node votes that is given to a
cluster member by using the
clu_quorum -m
command.
A member's votes are initially determined
by the
cluster_node_votes
kernel attribute in the
clubase
subsystem of its
member-specific
etc/sysconfigtab
file.
Use either the
clu_quorum
or
clu_get_info -full
command to display a member's
node votes.
See
Section 4.6
for more information.
To modify a
member's node votes, you must use the
clu_quorum
command.
You cannot modify the
cluster_node_votes
kernel
attribute directly.
4.2.5 Quorum Disk Votes
In certain cluster configurations, described in Section 4.5, you may enhance cluster availability by configuring a quorum disk. Quorum disk votes are the fixed number of votes that a quorum disk contributes towards quorum. A quorum disk can have either 1 or 0 (zero) votes.
You typically configure a quorum disk and assign it a vote
while running
clu_create
to create the cluster.
If you define a quorum disk at cluster creation, it is given
one vote by default.
Quorum disk votes are initialized from the
cluster_qdisk_votes
kernel attribute in the
clubase
subsystem of each member's
etc/sysconfigtab
file.
Use either the
clu_quorum
command or
clu_get_info
command to display quorum disk
votes.
To modify the quorum
disk votes, you must use the
clu_quorum
command.
You cannot modify the
cluster_qdisk_votes
kernel
attribute directly.
When configured, a quorum disk's vote plays a unique role in cluster formation because of the following rules that are enforced by the connection manager:
A booting node cannot form a cluster unless it has quorum.
Before the node can claim the quorum disk and its vote, it must be a cluster member.
In the situation where the booting node needs the quorum disk vote to achieve quorum, these rules create an impasse: the booting node would never be able to form a cluster.
The connection manager resolves this dilemma by
allowing booting members to provisionally apply the quorum disk vote
towards quorum.
This allows a booting member to achieve quorum
and form the cluster.
After it has formed the cluster, it claims
the quorum disk.
At that point, the quorum disk's vote is no longer
provisional; it is real.
4.3 Calculating Cluster Quorum
The quorum algorithm is the method by which the connection manager determines the circumstances under which a given member can participate in a cluster, safely access clusterwide resources, and perform useful work. The algorithm operates dynamically: that is, cluster events trigger its calculations, and the results of its calculations can change over the lifetime of a cluster.
The quorum algorithm operates as follows:
The connection manager selects a set of cluster members upon which it bases its calculations. This set includes all members with which it can communicate. For example, it does not include configured nodes that have not yet booted, members that are down, or members that it cannot reach due to a hardware failure (for example, a detached cluster interconnect cable or a bad Memory Channel adapter).
When a cluster is formed and each time a node boots and joins the cluster, the connection manager calculates a value for cluster expected votes using the largest of the following values:
Maximum member-specific expected votes value from the set of proposed members selected in step 1.
The sum of the node votes from the set of proposed members that were selected in step 1, plus the quorum disk vote if a quorum disk is configured.
The previous cluster expected votes value.
Consider a three-member cluster with no quorum disk. All members are up and fully connected; each member has one vote and has its member-specific expected votes set to 3. The value of cluster expected votes is currently 3.
A fourth voting member is then added to the cluster. When the new member boots and joins the cluster, the connection manager calculates the new cluster expected votes as 4, which is the sum of node votes in the cluster.
Use the
clu_quorum
or
clu_get_info
-full
command to display the current value
of cluster expected votes.
Whenever
the connection manager recalculates cluster expected votes (or
resets cluster expected votes as the result of a
clu_quorum -e
command), it calculates a value for
quorum votes.
Quorum votes is a dynamically calculated clusterwide value, based on the value of cluster expected votes, that determines whether a given node can form, join, or continue to participate in a cluster. The connection manager computes the clusterwide quorum votes value using the following formula:
quorum votes = round_down((cluster_expected_votes+2)/2)
For example, consider the three-member cluster from the previous step. With cluster expected votes set to 3, quorum votes are calculated as round_down((3+2)/2), or 2. In the case where the fourth member was added successfully, quorum votes are calculated as 3 (round_down((4+2)/2)).
Note
Expected votes (and, hence, quorum votes) are based on cluster configuration, rather than on which nodes are up or down. When a member is shut down, or goes down for any other reason, the connection manager does not decrease the value of quorum votes. Only member deletion and the
clu_quorum -ecommand can lower the quorum votes value of a running cluster.
Whenever a cluster member senses that the number of votes it can see has changed (a node has joined the cluster, an existing member has been deleted from the cluster, or a communications error is reported), it compares current votes to quorum votes.
The action the member takes is based on the following conditions:
If the value of current votes is greater than or equal to quorum votes, the member continues running or resumes (if it had been in a suspended state).
If the value of current votes is less than quorum votes, the member suspends all process activity, all I/O operations to cluster-accessible storage, and all operations across networks external to the cluster until sufficient votes are added (that is, until enough members have joined the cluster or the communications problem is mended) to bring current votes to a value greater than or equal to quorum.
The comparision of current votes to quorum votes occurs on a member-by-member basis, although events may make it appear that quorum loss is a clusterwide event. When a cluster member loses quorum, all of its I/O is suspended and all network interfaces except the Memory Channel interfaces are turned off. No commands that must access a clusterwide resource work on that member. It may appear to be hung.
Depending upon how the member lost quorum,
you may be able to remedy the situation by booting
a member with enough votes for the member in quorum hang to
achieve quorum.
If all cluster members have lost quorum,
your options are limited to booting a new member with enough votes
for the members in quorum hang to achieve quorum, rebooting the entire
cluster, or resorting to the procedures that are discussed in
Section 4.10.
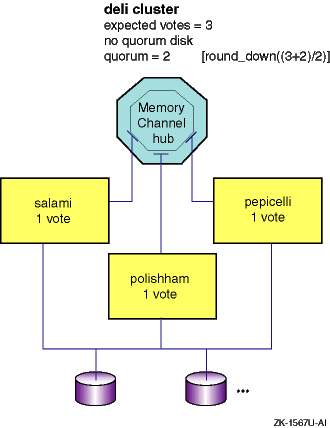
4.4 A Connection Manager Example
The connection manager forms a cluster when enough nodes with votes have booted for the cluster to have quorum, possibly after claiming the vote of a quorum disk.
Consider the three-member
deli
cluster in
Figure 4-1.
When all members are up and operational, each
member contributes one node vote; cluster expected votes is 3, and quorum
votes is calculated as 2.
The
deli
cluster can survive
the failure of any one member.
Figure 4-1: The Three-Member deli Cluster
When node
salami
was first booted, the console displayed
the following messages:
CNX MGR: Node salami id 3 incarn 0xbde0f attempting to form or join cluster deli CNX MGR: insufficient votes to form cluster: have 1 need 2 CNX MGR: insufficient votes to form cluster: have 1 need 2 . . .
When node
polishham
was booted, its node vote plus
salami's node vote allowed them to achieve quorum
(2) and proceed to form the cluster, as evidenced by the following
CNX MGR
messages:
. . . CNX MGR: Cluster deli incarnation 0x1921b has been formed Founding node id is 2 csid is 0x10001 CNX MGR: membership configuration index: 1 (1 additions, 0 removals) CNX MGR: quorum (re)gained, (re)starting cluster operations. CNX MGR: Node salami 3 incarn 0xbde0f csid 0x10002 has been added to the cluster CNX MGR: Node polishham 2 incarn 0x15141 csid 0x10001 has been added to the cluster
The boot log of node
pepicelli
shows similar messages
as
pepicelli
joins the existing cluster, although,
instead of the cluster formation message, it displays:
CNX MGR: Join operation complete CNX MGR: membership configuration index: 2 (2 additions, 0 removals) CNX MGR: Node pepicelli 1 incarn 0x26510f csid 0x10003 has been added to the cluster
Of course, if
pepicelli
is booted at the same time
as the other two nodes, it participates in the cluster formation
and shows cluster formation messages like those nodes.
If
pepicelli
is then shut down, as shown in
Figure 4-2,
members
salami
and
polishham
each compare their notions of cluster current votes (2) against quorum
votes (2).
Because current votes equals quorum votes, they can proceed as
a cluster and survive the shutdown of
pepicelli.
The
following log messages describe this activity:
memory channel - removing node 2
rm_remove_node: removal took 0x0 ticks
ccomsub: Successfully reconfigured for member 2 down
ics_RM_membership_change: Node 3 in RM slot 2 has gone down
CNX MGR: communication error detected for node 3
CNX MGR: delay 1 secs 0 usecs
.
.
.
CNX MGR: Reconfig operation complete
CNX MGR: membership configuration index: 13 (2 additions, 1 removals)
CNX MGR: Node pepicelli 3 incarn 0x21d60 csid 0x10001 has been removed
from the cluster
Figure 4-2: Three-Member deli Cluster Loses a Member
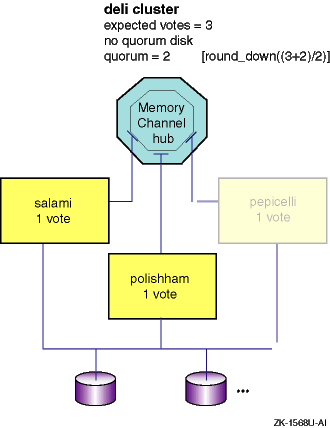
However, this cluster cannot survive the loss of yet another member.
Shutting down member
polishham
results in the situation
that is depicted in
Figure 4-3
and discussed in
Section 4.5.
The
deli
cluster loses
quorum and ceases operation with the following messages:
memory channel - removing node 4
rm_remove_node: removal took 0x0 ticks
ccomsub: Successfully reconfigured for member 4 down
ics_RM_membership_change: Node 2 in RM slot 4 has gone down
CNX MGR: communication error detected for node 2
CNX MGR: delay 1 secs 0 usecs
CNX MGR: quorum lost, suspending cluster operations.
.
.
.
CNX MGR: Reconfig operation complete
CNX MGR: membership configuration index: 16 (8 additions, 8 removals)
CNX MGR: Node pepicelli 2 incarn 0x59fb4 csid 0x50001 has been removed
from the cluster
In a two-member cluster configuration, where each member has one member vote and expected votes has the value of 2, the loss of a single member will cause the cluster to lose quorum and all applications to be suspended. This type of configuration is not highly available.
A more realistic (but not substantially better) two-member configuration assigns one member 1 vote and the second member 0 (zero) votes. Expected votes are 1. This cluster can lose its second member (the one with no votes) and remain up. However, it cannot afford to lose the first member (the voting one).
To foster better availability in such a configuration, you can designate a disk on a shared bus as a quorum disk. The quorum disk acts as a virtual cluster member whose purpose is to add one vote to the total number of expected votes. When a quorum disk is configured in a two-member cluster, the cluster can survive the failure of either the quorum disk or one member and continue operating.
For example, consider the two-member
deli
cluster
without a quorum disk shown in
Figure 4-3.
Figure 4-3: Two-Member deli Cluster Without a Quorum Disk
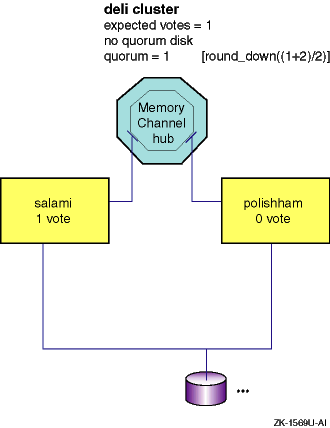
One member contributes 1 node vote and the other contributes 0, so cluster expected votes is 1. The connection manager calculates quorum votes as follows:
quorum votes = round_down((cluster_expected_votes+2)/2) = round_down((1+2)/2) = 1
The failure or shutdown of member
salami
causes
member
polishham
to lose quorum.
Cluster operations are
suspended.
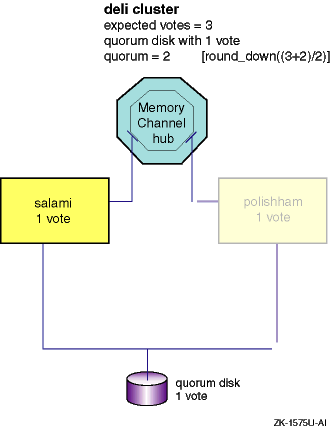
However, if the cluster includes a quorum disk (adding one vote to the
total of cluster expected votes), and member
polishham
is also given a vote, expected votes become 3 and
quorum votes become 2:
quorum votes = round_down((cluster_expected_votes+2)/2) = round_down((3+2)/2) = 2
Now, if either member or the quorum disk leaves the cluster,
sufficient current votes remain to keep the cluster from losing
quorum.
The cluster in
Figure 4-4
can continue operation.
Figure 4-4: Two-Member deli Cluster with Quorum Disk Survives Member Loss
The
clu_create
utility allows you to specify a quorum
disk at cluster creation and assign it a vote.
You can also
use the
clu_quorum
utility to add a quorum disk
at some other moment in the life of a cluster; for example, when
the result of a
clu_delete_member
is a two-member
cluster with compromised availability.
To configure a quorum disk, use the
clu_quorum -d add
command.
For example, the following command defines
/dev/disk/dsk11
as a quorum disk with one vote:
# clu_quorum -d add dsk11 1
Collecting quorum data for Member(s): 1 2
Info: Disk available but has no label: dsk11
Initializing cnx partition on quorum disk : dsk11h
Successful quorum disk creation.
# clu_quorum
Cluster Common Quorum Data
Quorum disk: dsk11h
.
.
.
The following restrictions apply to the use of a quorum disk:
A cluster can have only one quorum disk.
The quorum disk should be on a shared bus to which all cluster members are directly connected. If it is not, members that do not have a direct connection to the quorum disk may lose quorum before members that do have a direct connection to it.
The quorum disk must not contain any data.
The
clu_quorum
command will overwrite existing data when
initializing the quorum disk.
The integrity of data (or file system
metadata) that is placed on the quorum disk from a running cluster is
not guaranteed across member failures.
This means that the member boot disks and the disk holding the clusterwide root (/) cannot be used as quorum disks.
The quorum disk can be quite small. The cluster subsystems use only 1 MB of the disk.
A quorum disk can have either 1 vote or no votes. In general, a quorum disk should always be assigned a vote. You might assign an existing quorum disk no votes in certain testing or transitory configurations, such as a one-member cluster (in which a voting quorum disk introduces a second point of failure).
You cannot use the Logical Storage Manager (LSM) on the quorum disk.
Conceptually, a vote that is supplied by a quorum disk serves as a tie-breaker in cases where a cluster can partition with an even number of votes on either side of the partition. The tie-breaker vote allows one side to achieve quorum and continue cluster operations. In this regard, the quorum disk's vote is no different than a vote, for example, that is brought to a two-member cluster by a third voting member or brought to a four-member cluster by a fifth voting member. This is an important consideration when planning larger clusters containing many non-voting members that do not have direct connectivity to all shared storage.
Consider a cluster containing two large members that act as file servers. Because these members are directly connected to the important cluster file systems and application databases, they are considered critical to the operation to the cluster and are each assigned one vote. The other members of this cluster process client requests and direct them to the servers. Because they are not directly connected to shared storage, they are less critical to cluster operation and are assigned no votes. However, because this cluster has only two votes, it cannot withstand the failure of a single file server member until we configure a tie-breaker vote.
In this case, what should provide the tie-breaker vote? Configuring a quorum disk with the vote is be a poor choice. The quorum disk in this configuration is directly connected to only the two file server members. The client processing members, as a result, cannot count its vote towards quorum. If the quorum disk or a single file server member fails, the client processing members lose quorum and stop shipping client requests to the servers. This effectively hampers the operation of the server members, even though they retain quorum. A better solution for providing a tie-breaker vote to this type of configuration is to assign a vote to one of the client processing members. The cluster as a whole can then survive the loss of a single vote and continue to operate.
If you attempt
to add a quorum disk and that vote, when added, is be
needed to sustain quorum, the
clu_quorum
command displays the following message:
Adding the quorum disk could cause a temporary loss of quorum until the disk becomes trusted. Do you want to continue with this operation? [yes]:
You can usually respond "yes" to this question.
It usually takes about
20 seconds for the
clu_quorum
command to
determine the trustworthiness of the quorum disk.
For the quorum disk
to become trusted, the member
needs direct connectivity to it, must be able to read to and write from it,
and must either claim ownership of it or be a member of the same cluster as
a member that claims ownership.
If you attempt to adjust the votes of an existing quorum disk and the
member does not consider that disk to be trusted (as indicated by a zero
value in the
qdisk_trusted
attribute of the
cnx
subsystem), the
clu_quorum
command displays the following message:
The quorum disk does not currently appear to be trusted. Adjusting the votes on the quorum disk could cause quorum loss. Do you want to continue with this operation? [no]:
If the quorum disk is not currently trusted, it is unlikely to become
trusted unless you do something that allows it to meet the preceding
requirements.
You should probably answer "no" to this question and
investigate other ways of adding a vote to the cluster.
4.5.1 Replacing a Failed Quorum Disk
If a quorum disk fails during cluster operation and the cluster does not lose quorum, you can replace the disk by following these steps:
Make sure that the disk is disconnected from the cluster.
Use the
clu_quorum
command and note the running
value of quorum disk votes.
Use the
clu_quorum -f -d remove
command to remove the
quorum disk from the cluster.
Replace the disk.
Enter the
hwmgr -scan scsi
command
on each cluster member.
Note
You must run
hwmgr -scan scsion every cluster member.
Wait a few moments for all members to recognize the presence of the new disk.
Use the
hwmgr -view devices -cluster
command to determine the
device special file name (that is, the
dsk
name)
of the new disk.
Its name will be different from that of the failed
quorum disk.
Optionally, you can use the
dsfmgr -n
command to rename the new device special file to the name of the failed
disk.
Use the
clu_quorum -f -d add
command to configure the
new disk as the quorum disk.
The new disk should have the same number of
votes as noted in step 2.
If a quorum disk fails during cluster operation and the
cluster loses quorum and suspends operations, you must use the procedure
in
Section 4.10.1
to halt one
cluster member and reboot it interactively to
restore quorum to the cluster.
You can then perform the previous
steps.
4.6 Using the clu_quorum Command to Display Cluster Vote Information
When specified without options (or with
-f
and/or
-v), the
clu_quorum
command displays information about the current quorum
disk, member node votes, and expected votes configuration of the cluster.
This information includes:
Cluster common quorum data.
This includes the device name of any configured
quorum disk, plus quorum information from the clusterwide
/etc/sysconfigtab.cluster.
Member-specific quorum data from each member's running kernel and
/etc/sysconfigtab
file, plus an indication of whether
the member is
UP
or
DOWN.
By default,
no quorum data is returned for
a member with
DOWN
status.
However, as long as the
DOWN
member's boot partition is accessible to the member
running the
clu_quorum
command, you can use the
-f
option to display the
DOWN
member's file quorum data values.
See
clu_quorum(8)
for a description of the
individual items the
clu_quorum
displays.
4.7 Cluster Vote Assignment Examples
Table 4-1
presents how various settings of
the
cluster_expected_votes
and
cluster_node_votes
attributes on cluster members
affect the cluster's ability to form.
It also points out which setting combinations can be disastrous and
highlights those that foster the best cluster availability.
The table
represents two-, three-, and four-member cluster configurations.
In this table:
"Node Expected Votes" indicates the on-disk
setting of the
cluster_expected_votes
attribute in the
clubase
stanza of a member's
/etc/sysconfigtab
file.
"M1," "M2," "M3", and "M4" indicate the votes that are assigned to cluster members.
"Qdisk" represents the votes that are assigned to the quorum disk (if configured).
The notation "---" indicates that a given node has not been configured in the cluster.
Table 4-1: Effects of Various Member cluster_expected_votes Settings and Vote Assignments in a Two- to Four-Member Cluster
| Node Expected Votes | M1 | M2 | M3 | M4 | Qdisk | Result |
| 1 | 1 | 0 | --- | --- | 0 | Cluster can form only when M1 is present. Cluster can survive the failure of M2 but not M1. This is a common configuration in a two-member cluster when a quorum disk is not used. Try adding a vote to M2 and a quorum disk to this configuration. |
| 2 | 1 | 1 | --- | --- | 0 | Cluster can form only when both members are present. Cluster cannot survive a failure of either member. As discussed in Section 4.4, this is a less available configuration than the previous one. Try a quorum disk in this configuration. See Section 4.5. |
| 3 | 1 | 1 | --- | --- | 1 | With the quorum disk configured and given 1 vote, the cluster can survive the failure of either member or the quorum disk. This is the recommended two-member configuration. |
| 1 | 1 | 0 | 0 | --- | 0 | Cluster can survive failures of members M2 and M3 but not a failure of M1. |
| 2 | 1 | 1 | 0 | --- | 0 | Cluster requires both M1 and M2 to be up. It can survive a failure of M3. |
| 3 | 1 | 1 | 1 | --- | 0 | Cluster can survive the failure of any one member. This is the recommended three-member cluster configuration. |
| 4 | 1 | 1 | 1 | --- | 1 | Because 3 votes are required for quorum, the presence of a voting quorum disk does not make this configuration any more highly available than the previous one. In fact, if the quorum disk were to fail (an unlikely event), the cluster would not survive a member failure. [Footnote 2] |
| 4 | 1 | 1 | 1 | 1 | 0 | Cluster can survive failure of any one member. Try a quorum disk in this configuration. See Section 4.5. |
| 5 | 1 | 1 | 1 | 1 | 1 | Cluster can survive failure of any two members or of any member and the quorum disk. This is the recommended four-member configuration. |
4.8 Monitoring the Connection Manager
The connection manager provides several kinds of output for administrators. It posts Event Manager (EVM) events for four types of events:
Node joining cluster
Node removed from cluster
Quorum disk becoming unavailable (due to error, removal, and so on)
Quorum disk becoming available again
Each of these events also results in console message output.
The connection manager displays various informational messages on the console during member boots and cluster transactions.
A cluster transaction is the mechanism for modifying some clusterwide state on all cluster members atomically; either all members adopt the new value or none do. The most common transactions are membership transactions, such as when the cluster is formed, members join, or members leave. Certain maintenance tasks also result in cluster transactions, such as the addition or removal of a quorum disk, the modification of the clusterwide expected votes value, or the modification of a member's vote.
Cluster transactions are global (clusterwide) occurrences.
Console messages are also printed on the console of an individual
member in response to certain local events, such as when the connection
manager notices a change in connectivity on a given node
(to another node or to the quorum disk),
or when it gains or loses quorum.
4.9 Connection Manager Panics
The connection manager continuously monitors cluster members. In the rare case of a cluster partition, in which an existing cluster divides into two or more clusters, nodes may consider themselves to be members of one cluster or another. As discussed in Section 4.3, the connection manager at most allows only one of these clusters to function.
To preserve data integrity if a cluster partitions, the connection manager will cause a member to panic. The panic string indicates the conditions under which the partition was discovered. These panics are not due to connection manager problems but are reactions to bad situations, where drastic action is appropriate to ensure data integrity. You cannot repair a partition without rebooting one or more members to have them rejoin the cluster.
The connection manager reacts to the following situations by panicking a cluster member:
Quorum disk that is attached to two different clusters:
CNX QDISK: configuration error. Qdisk in use by cluster of different name. CNX QDISK: configuration error. Qdisk written by cluster of different name.
Quorum disk ownership that is being contested by different clusters after a cluster partition. The member that discovers this condition decides either to continue trying to claim the quorum disk or to yield to the other cluster by panicking:
CNX QDISK: Yielding to foreign owner with quorum. CNX QDISK: Yielding to foreign owner with provisional quorum. CNX QDISK: Yielding to foreign owner without quorum.
Connection manager on a node that is already a cluster member discovers a node that is a member of a different cluster (may be a different incarnation of the same cluster). Depending on quorum status, the discovering node either directs the other node to panic, or panics itself.
CNX MGR: restart requested to resynchronize with cluster with quorum. CNX MGR: restart requested to resynchronize with cluster
Panicking node has discovered a cluster and will try to reboot and join:
CNX MGR: rcnx_status: restart requested to resynchronize with cluster
with quorum.
CNX MGR: rcnx_status: restart requested to resynchronize with cluster
A node is removed from the cluster during a reconfiguration because of communication problems:
CNX MGR: this node removed from cluster
4.10 Troubleshooting Unfortunate Expected Vote and Node Vote Settings
As long as a cluster maintains quorum, you can use
the
clu_quorum
command to adjust node votes, expected
votes,
and quorum disk votes across the cluster.
Using the
-f
option to the command, you can force changes on members that are currently
down.
However, if a cluster member loses quorum, all I/O is suspended and
all network interfaces except the Memory Channel interfaces are turned off.
No commands that must access cluster shared resources work, including the
clu_quorum
command.
Either a member with enough votes rejoins the cluster
and quorum is regained, or you must halt and reboot a cluster member.
Sometimes you may need to adjust the vote configuration of a cluster
that is hung in quorum loss or for a cluster that has insufficient
votes to form.
The following scenarios describe some cluster problems
and the mechanisms you can use to resolve them.
4.10.1 Joining a Cluster After a Cluster Member or Quorum Disk Fails and Cluster Loses Quorum
Consider a cluster that has lost one or more members (or a quorum disk) due to hardware problems -- problems that prevent these members from being rebooted. Without these members, the cluster has lost quorum, and its surviving members' expected votes or node votes settings are not realistic for the downsized cluster. Having lost quorum, the cluster hangs.
You can resolve this type of quorum loss
situation without shutting the entire cluster down.
The procedure involves
halting a single cluster member and rebooting it in such a way that it
can join the cluster and restore quorum.
After you have booted this member,
you must use the
clu_quorum
command to fix the original
problem.
Note
If only a single cluster member survives the member or quorum disk failures, use the procedure in Section 4.10.2 for booting a cluster member with sufficient votes to form a cluster.
To restore quorum for a cluster that has lost quorum due to one or more member or quorum disk failures, follow these steps:
Halt one cluster member by using its Halt button.
Reboot the halted cluster member interactively.
When the
boot procedure requests you to enter the name of the kernel from which to
boot, specify both the kernel name and a value of 0 (zero) for
the
cluster_adjust_expected_votes
clubase
attribute.
A value of 0 (zero) causes the connection manager to set
expected votes to the total number of member and quorum disk votes that
are currently available in the cluster.
Note
Because the
cluster_adjust_expected_votestransaction is performed only after the booting node joins the cluster, this method is effective only for those cases where an existing cluster is hung in quorum loss. If the cluster cannot form because expected votes is too high, thecluster_adjust_expected_votestransaction cannot run and the booting member will hang. In this case, you must use one of the methods in Section 4.10.2 to boot the member and form a cluster.
For example:
>>> boot -fl "ia" (boot dkb200.2.0.7.0 -flags ia) block 0 of dkb200.2.0.7.0 is a valid boot block reading 18 blocks from dkb200.2.0.7.0 bootstrap code read in base = 200000, image_start = 0, image_bytes = 2400 initializing HWRPB at 2000 initializing page table at fff0000 initializing machine state setting affinity to the primary CPU jumping to bootstrap code
.
.
.
Enter kernel_name [option_1 ... option_n] Press Return to boot default kernel 'vmunix':vmunix clubase:cluster_adjust_expected_votes=0[Return]
When you resume the boot, the member can join the cluster and the connection manager communicates the new operative expected votes value to the other cluster members so that they regain quorum.
Caution
The
cluster_adjust_expected_votessetting modifies only the operative expected votes setting in the currently active cluster, and is used only as long as the entire cluster remains up. It does not modify the values that are stored in the/etc/sysconfigtabfile. Unless you now explicitly reconfigure node votes, expected votes, and the quorum disk configuration in the cluster, a subsequent cluster reboot may result in booting members not being able to attain quorum and form a cluster. For this reason, you must proceed to fix node votes and expected votes values on this member and other cluster members, as necessary.
Consulting
Table 4-2, use
the appropriate
clu_quorum
commands to temporarily
fix the configuration of votes in the cluster until the
broken hardware is repaired or replaced.
In general, as soon as the cluster is up and stable, you may
use the
clu_quorum
command to fix the original problem.
For example, you might:
Lower the node votes on the members who are having hardware problems:
# clu_quorum -f -m member-ID lower_node_votes_value
This command may return an error if it cannot access the member's
boot disk (for example, if the boot disk is on a member private bus).
If
the command fails for this reason, use the
clu_quorum -f -e
command to adjust expected votes appropriately.
Lower the expected votes on all members to compensate for the members who can no longer vote due to loss of hardware and whose votes you cannot remove:
# clu_quorum -f -e lower_expected_votes_value
If a
clu_quorum -f
command cannot access a down
member's
/etc/sysconfigtab
file, it fails with
an appropriate message.
This usually happens when the down member's boot
disk is on a bus private to that member.
To resolve quorum problems
involving such a member, boot that member interactively,
setting
cluster_expected_votes
to a value that allows the member to join the cluster.
When it joins,
use the
clu_quorum
command to correct vote settings as
suggested in this section.
See
Table 4-2
for examples on how to
restore quorum to a four-member cluster with a quorum disk and a five-member
cluster without one.
In the table, the abbreviation NC indicates that
the member or quorum disk is not configured in the cluster.
Table 4-2: Examples of Resolving Quorum Loss in a Cluster with Failed Members or Quorum Disk
| M1 | M2 | M3 | M4 | M5 | Qdisk | Procedure |
| Up, 1 vote | Up, 1 vote | Failed, 1 vote | Failed, 1 vote | NC | Failed | 1.
Boot
M1 or M2 interactively with
2.
Remove
the node votes from M3 and M4 by using
3.
Delete the quorum disk by using the
4.
Repair or
replace the broken hardware.
The most immediate need of the
two-member cluster, if it is to survive a failure, is a voting quorum disk.
Use the
If you cannot add a quorum
disk, use the
|
| Up, 1 vote | Up, 1 vote | Failed, 1 vote | Failed, 1 vote | Failed, 1 vote | NC | 1.
Boot
M1 or M2 interactively with
2.
Remove
the node votes from M3, M4, and M5 by using
3.
Repair
or replace the broken hardware.
The most immediate need of the
two-member cluster, if it is to survive a failure, is a voting quorum disk.
Use the
If the broken
members will be unavailable for a considerable time,
use the
|
4.10.2 Forming a Cluster When Members Do Not Have Enough Votes to Boot and Form a Cluster
Consider a cluster that cannot form. When you attempt to boot all members, each hangs, waiting for a cluster to form. All together they lack sufficient votes to achieve quorum. A small cluster that experiences multiple hardware failures can also devolve to a configuration in which the last surviving voting member has lost quorum.
The following procedure effectively allows you to form the cluster by booting a single cluster member with sufficient votes to form the cluster. You then can adjust node votes and boot the remaining members into the cluster.
Halt each cluster member.
Consult Table 4-3 to determine the kernel attributes that must be adjusted at boot time to resolve your cluster's specific quorum loss situation.
Boot one voting cluster member interactively.
When the
boot procedure requests you to enter the name of the kernel from which to
boot, specify both the kernel name and the recommended kernel attribute
setting.
For instance, for a two-member cluster (with two node votes and
a quorum disk) that has experienced both a member failure and a quorum
disk failure, enter
clubase:cluster_expected_votes=1
clubase:cluster_qdisk_votes=0.
For example:
>>> boot -fl "ia" (boot dkb200.2.0.7.0 -flags ia) block 0 of dkb200.2.0.7.0 is a valid boot block reading 18 blocks from dkb200.2.0.7.0 bootstrap code read in base = 200000, image_start = 0, image_bytes = 2400 initializing HWRPB at 2000 initializing page table at fff0000 initializing machine state setting affinity to the primary CPU jumping to bootstrap code
.
.
.
Enter kernel_name [option_1 ... option_n] Press Return to boot default kernel 'vmunix':vmunix clubase:cluster_expected_votes=1 clubase:cluster_qdisk_votes=0[Return]
When you resume the boot, the member can form a cluster.
While referring to
Table 4-3, use
the appropriate
clu_quorum
commands to
fix the configuration of votes in the cluster temporarily until the
broken hardware is repaired or replaced.
If an unavailable quorum disk contributed to the problem, make sure
that the disk is available and has a vote.
Replace the quorum disk if
necessary (see
Section 4.5.1).
Otherwise, other
members may not be able to boot.
Reboot remaining members.
See
Table 4-3
for examples on how to repair a quorum
deficient cluster by booting a cluster member with sufficient
votes to form the cluster.
In the table, the abbreviation NC indicates that
the member or quorum disk is not configured in the cluster.
Table 4-3: Examples of Repairing a Quorum Deficient Cluster by Booting a Member with Sufficient Votes to Form the Cluster
| M1 | M2 | M3 | Qdisk | Procedure |
| Up, 1 vote | Up, 0 votes | NC | Failed, 1 vote | 1.
Boot
M2 interactively with
2.
Use
the
3.
Replace
the broken quorum
disk using the
|
| Up, 1 vote | Failed, 1 vote | NC | Failed, 1 vote | 1.
Boot M1
interactively with
2.
Use
the
3.
Use
the
4. Repair or replace the broken hardware. If you cannot immediately obtain a second voting member with a voting quorum disk, adding a second member with no votes may be a reasonable interim solution. This will result in a configuration that can survive the failure of the nonvoting member. |
| Up, 1 vote | Failed, 1 vote | Failed, 1 vote | NC | 1.
Boot
M1 interactively with
2.
Use
the appropriate
3. Repair or replace the broken hardware. If you cannot immediately obtain a second voting member with a voting quorum disk, adding a second member with no votes may be a reasonable interim solution. This will result in a configuration that can survive the failure of the nonvoting member. |