This chapter introduces the TruCluster Server product and some basic cluster hardware configuration concepts.
The chapter discusses the following topics:
An overview of the TruCluster Server product (Section 1.1)
TruCluster Server memory requirements (Section 1.2)
TruCluster Server minimum disk requirements (Section 1.3)
A description of a generic two-node cluster with the minimum disk layout (Section 1.4)
How to grow a cluster to a no-single-point-of-failure (NSPOF) cluster (Section 1.5)
An overview of eight-member clusters (Section 1.6)
An overview of setting up the TruCluster Server hardware configuration (Section 1.7)
Subsequent chapters describe how to set up and maintain
TruCluster Server hardware configurations.
See the TruCluster Server
Cluster Installation
manual for information about software installation;
see the
Cluster Administration
manual for detailed
information about setting up member systems; see the
Cluster Highly Available Applications
manual for detailed
information about setting up highly available applications.
1.1 The TruCluster Server Product
TruCluster Server extends single-system management capabilities to clusters. It provides a clusterwide namespace for files and directories, including a single root file system that all cluster members share. It also offers a cluster alias for the Internet protocol suite (TCP/IP) so that a cluster appears as a single system to its network clients.
TruCluster Server preserves the availability and performance features found in the earlier TruCluster products:
Like the TruCluster Available Server Software and TruCluster Production Server products, TruCluster Server lets you deploy highly available applications that have no embedded knowledge that they are executing in a cluster. They can access their disk data from any member in the cluster.
Like the TruCluster Production Server Software product, TruCluster Server lets you run components of distributed applications in parallel, providing high availability while taking advantage of cluster-specific synchronization mechanisms and performance optimizations.
TruCluster Server augments the feature set of its predecessors by allowing
all cluster members access to all file systems and all storage in the
cluster, regardless of where they reside.
From the viewpoint of clients,
a TruCluster Server cluster appears to be a single system; from the viewpoint
of a system administrator, a TruCluster Server cluster is managed as if it
were a single system.
Because TruCluster Server has no built-in dependencies
on the architectures or protocols of its private cluster interconnect or
shared storage interconnect, you can more easily alter or expand your
cluster's hardware configuration as newer and faster technologies become
available.
1.2 Memory Requirements
The base operation system sets a minimum requirement for the amount of
memory required to install Tru64 UNIX.
In a cluster, each member
must have at least 64 MB more than this minimum requirement.
For
example, if the base operating system requires 128 MB of memory, each
system used in a cluster must have at least 192 MB of memory.
1.3 Minimum Disk Requirements
This section provides an overview of the
minimum file system or disk requirements for a two-node
cluster.
For more information on the amount of space required for
each required cluster file system, see the
Cluster Installation
manual.
1.3.1 Disks Needed for Installation
You need to allocate disks for the following uses:
One or more disks to hold the Tru64 UNIX operating system. The disks are either private disks on the system that will become the first cluster member, or disks on a shared bus that the system can access.
One or more disks on a shared SCSI bus to hold the
clusterwide root (/),
/usr, and
/var
Advanced File System (AdvFS) file systems.
One disk per member, normally on a shared SCSI bus, to hold member boot partitions.
Optionally, one disk on a shared SCSI bus to act as the quorum disk (see Section 1.3.1.4). For a more detailed discussion of the quorum disk, see the Cluster Administration manual.
The following sections provide more information about these disks.
Figure 1-1
shows a generic two-member cluster
with the required file systems.
1.3.1.1 Tru64 UNIX Operating System Disk
The Tru64 UNIX operating system is installed using AdvFS file systems on one or more disks that are accessible to the system that will become the first cluster member. For example:
dsk0a root_domain#root dsk0g usr_domain#usr dsk0h var_domain#var
The operating system disk (Tru64 UNIX disk) cannot be used as a clusterwide disk, as a member boot disk, or as the quorum disk.
Because the Tru64 UNIX operating system will be available on the
first cluster member, in an emergency, after shutting down the
cluster, you have the option of booting the Tru64 UNIX operating
system and attempting to fix the problem.
See the
Cluster Administration
manual for more information.
1.3.1.2 Clusterwide Disks
When you create a cluster, the installation scripts copy the
Tru64 UNIX root (/),
/usr, and
/var
file
systems from the Tru64 UNIX disk to the disk or disks you specify.
We recommend that the disk or disks that you use for the clusterwide file systems be placed on a shared SCSI bus so that all cluster members have access to these disks.
During the installation, you supply the disk device names and partitions
that will contain the clusterwide
root
(/),
/usr,
and
/var
file systems.
For example,
dsk3b,
dsk4c, and
dsk3g:
dsk3b cluster_root#root dsk4c cluster_usr#usr dsk3g cluster_var#var
The
/var
fileset cannot share the
cluster_usr
domain, but must be a separate domain,
cluster_var.
Each AdvFS file system must be a
separate partition; the partitions do not have to be on the same disk.
If any partition on a disk is used by a clusterwide file system, only
clusterwide file systems can be on that disk.
A disk containing a clusterwide
file system cannot also be used as the member boot disk or as the
quorum disk.
1.3.1.3 Member Boot Disk
Each member has a boot disk.
A boot disk contains that member's
boot, swap, and cluster-status partitions.
For example,
dsk1
is the boot disk for the first member and
dsk2
is
the boot disk for the second member:
dsk1 first member's boot disk [pepicelli] dsk2 second member's boot disk [polishham]
The installation scripts reformat each member's boot disk to contain
three partitions: an
a
partition for that member's
root (/) file system, a
b
partition for swap,
and an
h
partition for cluster status information.
(There
are no
/usr
or
/var
file systems on
a member's boot disk.)
A member boot disk cannot contain one of the clusterwide
root (/),
/usr, and
/var
file systems.
Also, a member boot disk cannot be
used as the quorum disk.
A member disk can contain more than the three
required partitions.
You can move the swap partition off the member
boot disk.
See the
Cluster Administration
manual for more information.
1.3.1.4 Quorum Disk
The quorum disk allows greater availability for clusters
consisting of two members.
Its
h
partition
contains cluster status and quorum information.
See the
Cluster Administration
manual for a discussion of how and
when to use a quorum disk.
The following restrictions apply to the use of a quorum disk:
A cluster can have only one quorum disk.
The quorum disk should be on a shared bus to which all cluster members are directly connected. If it is not, members that do not have a direct connection to the quorum disk may lose quorum before members that do have a direct connection to it.
The quorum disk must not contain any data.
The
clu_quorum
command will overwrite existing data
when initializing the quorum disk.
The integrity of data (or file
system metadata) placed on the quorum disk from a running cluster is
not guaranteed across member failures.
This means that the member boot disks and the disk holding the clusterwide root (/) cannot be used as quorum disks.
The quorum disk can be small. The cluster subsystems use only 1 MB of the disk.
A quorum disk can have either 1 vote or no votes. In general, a quorum disk should always be assigned a vote. You might assign an existing quorum disk no votes in certain testing or transitory configurations, such as a one-member cluster (in which a voting quorum disk introduces a single point of failure).
You cannot use the Logical Storage Manager (LSM) on the quorum disk.
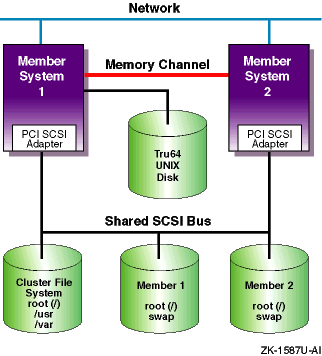
This section describes a generic two-node cluster with the minimum disk layout of four disks. Additional disks may be needed for highly available applications. In this section, and the following sections, the type of peripheral component interconnect (PCI) SCSI bus adapter is not significant. Also, although an important consideration, SCSI bus cabling, including Y cables or trilink connectors, termination, the use of UltraSCSI hubs, and the use of Fibre Channel are not considered at this time.
Figure 1-1 shows a generic two-node cluster with the minimum number of disks.
Tru64 UNIX disk
Clusterwide root (/),
/usr,
and
/var
Member 1 boot disk
Member 2 boot disk
A minimum configuration cluster may have reduced availability due to
the lack of a quorum disk.
As shown, with only two-member systems,
both systems must be operational to achieve quorum and form a cluster.
If only one system is operational, it will loop, waiting for the second
system to boot before a cluster can be formed.
If one system crashes,
you lose the cluster.
Figure 1-1: Two-Node Cluster with Minimum Disk Configuration and No Quorum Disk
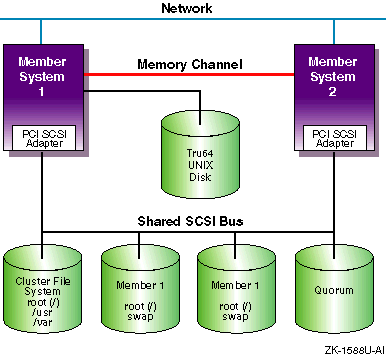
Figure 1-2
shows the same generic
two-node cluster as shown in
Figure 1-1,
but with the addition of a quorum disk.
By adding a quorum disk, a
cluster may be formed if both systems are operational, or if either of
the systems and the quorum disk is operational.
This cluster has a
higher availability than the cluster shown in
Figure 1-1.
See the
Cluster Administration
manual for a discussion of how and when to use a quorum disk.
Figure 1-2: Generic Two-Node Cluster with Minimum Disk Configuration and Quorum Disk
1.5 Growing a Cluster from Minimum Storage to an NSPOF Cluster
The following sections take a progression of clusters from a cluster with minimum storage to a no-single-point-of-failure (NSPOF) cluster -- a cluster where one hardware failure will not interrupt the cluster operation:
The starting point is a cluster with minimum storage for highly available applications (Section 1.5.1).
By adding a second storage shelf, you have a cluster with more storage for applications, but the single SCSI bus is a single point of failure (Section 1.5.2).
Adding a second SCSI bus allows the use of LSM to mirror
the clusterwide root (/),
/usr, and
/var
file
systems, the member system swap disks, and the data disks.
However, because LSM cannot mirror the member system boot or quorum
disks, full redundancy is not achieved (Section 1.5.3).
Using a redundant array of independent disks (RAID) array controller in transparent failover mode allows the use of hardware RAID to mirror the disks. However, without a second SCSI bus, second Memory Channel, and redundant networks, this configuration is still not an NSPOF cluster (Section 1.5.4).
By using an HSZ70, HSZ80, or HSG80 with multiple-bus
failover enabled, you can use two shared SCSI buses to access the
storage.
Hardware RAID is used to mirror the root
(/),
/usr, and
/var
file systems, and the member system
boot disks, data disks, and quorum disk (if used).
A second
Memory Channel, redundant networks, and redundant power must also be
installed to achieve an NSPOF cluster (Section 1.5.5).
Note
The figures in this section are generic drawings and do not show shared SCSI bus termination, cable names, and so forth.
1.5.1 Two-Node Clusters Using an UltraSCSI BA356 Storage Shelf and Minimum Disk Configurations
This section takes the generic illustrations of our cluster example one step further by depicting the required storage in storage shelves. The storage shelves can be BA350, BA356 (non-UltraSCSI), or UltraSCSI BA356s. The BA350 is the oldest model, and can only respond to SCSI IDs 0-6. The non-Ultra BA356 can respond to SCSI IDs 0-6 or 8-14 (see Section 3.2). The UltraSCSI BA356 also responds to SCSI IDs 0-6 or 8-14, but also can operate at UltraSCSI speeds (see Section 3.2).
Figure 1-3
shows a TruCluster Server
configuration using an UltraSCSI BA356 storage unit.
The DS-BA35X-DA
personality module used in the UltraSCSI BA356 storage unit is a
differential-to-single-ended signal converter, and therefore accepts
differential inputs.
Figure 1-3: Minimum Two-Node Cluster with UltraSCSI BA356 Storage Unit
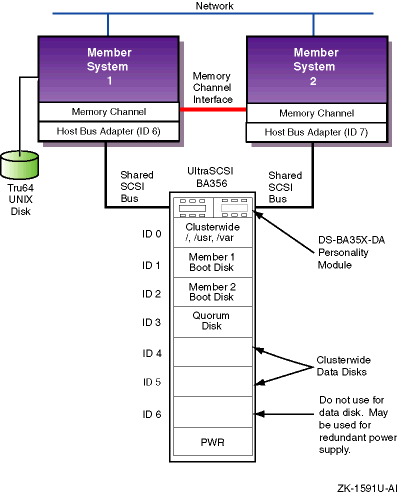
The configuration shown in Figure 1-3 might represent a typical small or training configuration with TruCluster Server Version 5.1A required disks.
In this configuration, because of the TruCluster Server Version 5.1A disk requirements, only two disks are available for highly available applications.
Note
Slot 6 in the UltraSCSI BA356 is not available because SCSI ID 6 is generally used for a member system SCSI adapter. However, this slot can be used for a second power supply to provide fully redundant power to the storage shelf.
With the use of the cluster file system (see the
Cluster Administration
manual for a discussion of the cluster file system),
the clusterwide root (/),
/usr, and
/var
file systems
can be physically placed on a private bus of either of the member
systems.
But, if that member system is not available, the other
member systems do not have access to the clusterwide file systems.
Therefore, we do not recommend placing the clusterwide root
(/),
/usr, and
/var
file systems on a private bus.
Likewise, the quorum disk can be placed on the local bus of either of the member systems. If that member is not available, quorum can never be reached in a two-node cluster. We do not recommend placing the quorum disk on the local bus of a member system because it creates a single point of failure.
The individual member boot and swap partitions can also be placed on a local bus of either of the member systems. If the boot disk for member system 1 is on a SCSI bus internal to member 1, and the system is unavailable due to a boot disk problem, other systems in the cluster cannot access the disk for possible repair. If the member system boot disks are on a shared SCSI bus, they can be accessed by other systems on the shared SCSI bus for possible repair.
By placing the swap partition on a system's internal SCSI bus, you reduce total traffic on the shared SCSI bus by an amount equal to the system's swap volume.
TruCluster Server Version 5.1A configurations require one or more disks to hold the Tru64 UNIX operating system. The disks are either private disks on the system that will become the first cluster member, or disks on a shared bus that the system can access.
We recommend that you place the clusterwide root
(/),
/usr, and
/var
file systems, member boot disks, and
quorum disk on a shared SCSI bus that is connected to all member
systems.
After installation, you have the option to reconfigure
swap and can place the swap disks on an internal SCSI bus to
increase performance.
See the
Cluster Administration
manual for more information.
1.5.2 Two-Node Clusters Using UltraSCSI BA356 Storage Units with Increased Disk Configurations
The configuration shown in Figure 1-3 is a minimal configuration, with a lack of disk space for highly available applications. Starting with Tru64 UNIX Version 5.0, 16 devices are supported on a SCSI bus. Therefore, multiple BA356 storage units can be used on the same SCSI bus to allow more devices on the same bus.
Figure 1-4
shows the configuration in
Figure 1-3
with a second UltraSCSI
BA356 storage unit that provides an additional seven disks for highly
available applications.
Figure 1-4: Two-Node Cluster with Two UltraSCSI DS-BA356 Storage Units
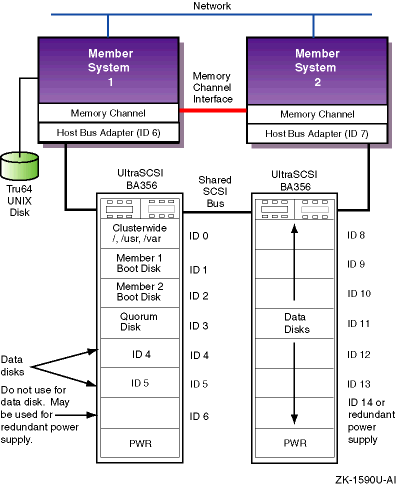
This configuration, while providing more storage, has
a single SCSI bus that presents a single point
of failure.
Providing a second SCSI bus can allow
the use of the Logical Storage Manager (LSM) to mirror the
clusterwide root (/),
/usr, and
/var
file
systems, and the data disks across SCSI buses, removing the single SCSI
bus as a single point of failure for these file systems.
1.5.3 Two-Node Configurations with UltraSCSI BA356 Storage Units and Dual SCSI Buses
By adding a second shared SCSI bus, you now have the capability to use
LSM to mirror data disks, and the
clusterwide root (/),
/usr, and
/var
file
systems across SCSI buses.
Note
You cannot use LSM to mirror the member system boot or quorum disks, but you can use hardware RAID.
Figure 1-5
shows a small cluster
configuration with dual SCSI buses using LSM to mirror the
clusterwide root (/),
/usr, and
/var
file systems
and the data disks.
Figure 1-5: Two-Node Configurations with UltraSCSI BA356 Storage Units and Dual SCSI Buses
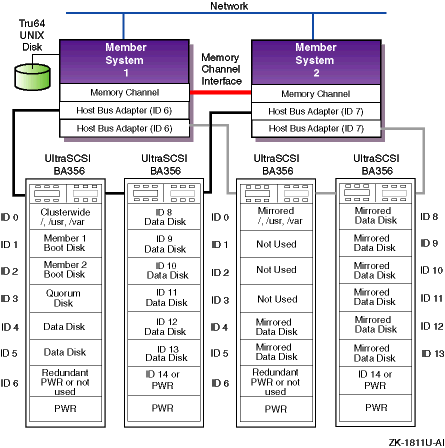
By using LSM to mirror the clusterwide root
(/),
/usr
and
/var
file systems and the data disks, we have
achieved higher availability.
But, even if you have a second
Memory Channel and redundant networks, because we cannot use LSM to mirror
the quorum or the member system boot disks, we do not have a
no-single-point-of-failure (NSPOF) cluster.
1.5.4 Using Hardware RAID to Mirror the Quorum and Member System Boot Disks
You can use hardware RAID with any of the supported RAID array
controllers to mirror the quorum and member system boot disks.
Figure 1-6
shows a cluster
configuration using an HSZ70 RAID array controller.
An HSZ40,
HSZ50, HSZ80, HSG60, or HSG80, or RAID array 3000 (with HSZ22
controller) can be used instead of the HSZ70.
The array
controllers can be configured as a dual redundant pair.
If you
want the capability to fail over from one controller to another
controller, you must install the second controller.
Also, you
must set the failover mode.
Figure 1-6: Cluster Configuration with HSZ70 Controllers in Transparent Failover Mode
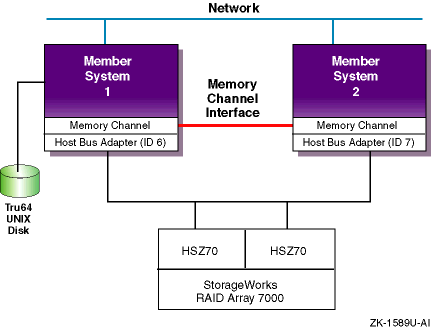
In
Figure 1-6
the HSZ40, HSZ50, HSZ70,
HSZ80, HSG60, or HSG80 has transparent failover mode enabled (SET
FAILOVER COPY = THIS_CONTROLLER).
In transparent failover
mode, both controllers are connected to the same shared SCSI bus and
device buses.
Both controllers service the entire group of
storagesets, single-disk units, or other storage devices.
Either
controller can continue to service all of the units if the other
controller fails.
Note
The assignment of HSZ target IDs can be balanced between the controllers to provide better system performance. See the RAID array controller documentation for information on setting up storagesets.
In the configuration shown in
Figure 1-6, there is only one shared SCSI bus.
Even by
mirroring the clusterwide root and member boot disks, the single
shared SCSI bus is a single point of failure.
1.5.5 Creating an NSPOF Cluster
A no-single-point-of-failure (NSPOF) cluster can be achieved by:
Using two shared SCSI buses and hardware RAID to mirror the cluster file system
Using multiple shared SCSI buses with storage shelves and mirroring those file systems that can be mirrored with LSM, and by judicial placement of those file systems that cannot be mirrored with LSM.
To create an NSPOF cluster with hardware RAID or LSM and shared SCSI buses with storage shelves, you need to:
Install a second Memory Channel interface for redundancy.
Install redundant power supplies.
Install redundant networks.
Connect the systems and storage to an uninterruptible power supply (UPS).
Additionally, if you are using hardware RAID, you need to:
Use hardware RAID to mirror the clusterwide root
(/),
/usr, and
/var
file systems, the member boot disks, quorum disk (if
present), and data disks.
Use at least two shared SCSI buses to access dual-redundant RAID array controllers set up for multiple-bus failover mode (HSZ70, HSZ80, HSG60, and HSG80).
Tru64 UNIX support for multipathing provides support for multiple-bus failover.
Notes
Only the HSZ70, HSZ80, HSG60, and HSG80 are capable of supporting multiple-bus failover (
SET MULTIBUS_FAILOVER COPY = THIS_CONTROLLER).Partitioned storagesets and partitioned single-disk units cannot function in multiple-bus failover dual-redundant configurations with the HSZ70 or HSZ80. You must delete any partitions before configuring the controllers for multiple-bus failover.
Partitioned storagesets and partitioned single-disk units are supported with the HSG60 and HSG80 and ACS V8.5 or later.
Figure 1-7
shows a cluster
configuration with dual-shared SCSI buses and a storage array with
dual-redundant HSZ70s.
If there is a failure in one SCSI bus, the
member systems can access the disks over the other SCSI bus.
Figure 1-7: NSPOF Cluster Using HSZ70s in Multiple-Bus Failover Mode
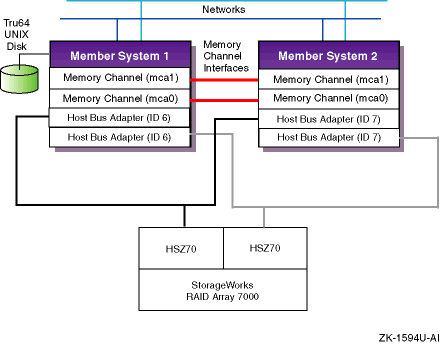
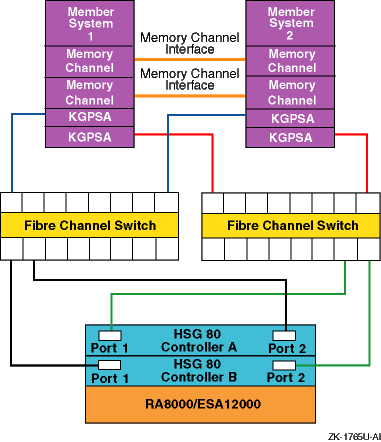
Figure 1-8
shows a cluster
configuration with dual-shared Fibre Channel buses and a storage
array with dual-redundant HSG80s configured for multiple-bus failover.
Figure 1-8: NSPOF Fibre Channel Cluster Using HSG80s in Multiple-Bus Failover Mode
If you are using LSM and multiple shared SCSI buses with storage shelves, you need to:
Mirror the clusterwide root (/),
/usr, and
/var
file
systems across two shared SCSI buses.
Place the boot disk for each member system on a separate shared SCSI bus.
Provide another shared SCSI bus for the quorum disk.
Figure 1-9
shows a two-member cluster
configuration with three shared SCSI buses.
The clusterwide root
(/),
/usr, and
/var
file systems are mirrored across the
first two shared SCSI buses.
The boot disk for member system one
is on the first shared SCSI bus.
The boot disk for member system
two is on the second shared SCSI bus.
The quorum disk is on the
third shared SCSI bus.
You can lose one system, or any one
shared SCSI bus, and still maintain a cluster.
Figure 1-9: NSPOF Cluster Using LSM and UltraSCSI BA356s
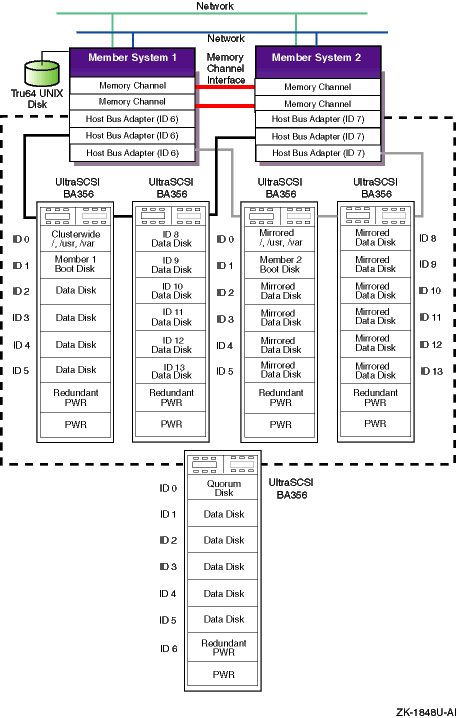
TruCluster Server Version 5.1A supports eight-member cluster configurations as follows:
Fibre Channel: Eight-member systems may be connected to common storage over Fibre Channel in a fabric (switch) configuration.
Parallel SCSI: Only four of the member systems may be connected to any one SCSI bus, but you can have multiple SCSI buses connected to different sets of nodes, and the sets of nodes may overlap. We recommend you use a DS-DWZZH-05 UltraSCSI hub with fair arbitration enabled when connecting four-member systems to a common SCSI bus using RAID array controllers.
An eight-member cluster using Fibre Channel can be extrapolated easily from the discussions in Chapter 6; just connect the systems and storage to your fabric.
An eight-member cluster using shared SCSI storage is more complicated than Fibre Channel, and requires considerable care to configure. One way to configure an eight-member cluster using external termination is discussed in Chapter 11.
1.7 Overview of Setting Up the TruCluster Server Hardware Configuration
To set up a TruCluster Server hardware configuration, follow these steps:
Plan your hardware configuration. (See Chapter 3, Chapter 4, Chapter 6, Chapter 9, Chapter 10, and Chapter 11.)
Draw a diagram of your configuration.
Compare your diagram with the examples in Chapter 3, Chapter 6, Chapter 10, and Chapter 11.
Identify all devices, cables, SCSI adapters, and so forth. Use the diagram that you just constructed.
Prepare the shared storage by installing disks and configuring any RAID controller subsystems. (See Chapter 3, Chapter 6, and Chapter 10 and the documentation for the StorageWorks enclosure or RAID controller.)
Install signal converters in the StorageWorks enclosures, if applicable. (See Chapter 3 and Chapter 10.)
Connect storage to the shared SCSI buses. Terminate each bus. Use Y cables or trilink connectors where necessary. (See Chapter 3 and Chapter 10.)
For a Fibre Channel configuration, connect the HSG60 or HSG80 controllers to the switches. You want the HSG60 or HSG80 to recognize the connections to the systems when the systems are powered on.
Prepare the member systems by installing:
Additional Ethernet or Asynchronous Transfer Mode (ATM) network adapters for client networks.
SCSI bus adapters. Ensure that adapter terminators are set correctly. Connect the systems to the shared SCSI bus. (See Chapter 4 or Chapter 9.)
The KGPSA host bus adapter for Fibre Channel configurations.
Ensure that the KGPSA is operating in the correct mode
(FABRIC
or
LOOP).
Connect the
KGPSA to the switch.
(See
Chapter 6.)
Memory Channel adapters. Ensure that jumpers are set correctly. (See Chapter 5.)
Connect the Memory Channel adapters to each other or to the Memory Channel hub as appropriate. (See Chapter 5.)
Turn on the Memory Channel hubs and storage shelves, then turn on the member systems.
Install the firmware, set SCSI IDs, and enable fast bus speed as necessary. (See Chapter 4 and Chapter 9.)
Display configuration information for each member system, and ensure that all shared disks are seen at the same device number. (See Chapter 4, Chapter 6, or Chapter 9.)