A realtime application is one in which the correctness of the application depends on the timeliness and predictability of the application as well as on the results of computations. To assist the realtime application designer in meeting these goals, Tru64 UNIX provides features that facilitate efficient interprocess communication and synchronization, a fast interrupt response time, asynchronous input and output (I/O), memory management functions, file synchronization, and facilities for satisfying timing requirements. Tru64 UNIX provides realtime facilities as part of the standard kernel and optional subsets.
Realtime applications are becoming increasingly important in our daily lives and can be found in such diverse environments as the automatic braking system on an automobile, a lottery ticket system, or robotic environmental samplers on a space station. The use of realtime programming techniques is rapidly becoming a common means for improving the predictability of our technology.
This chapter includes the following sections:
Realtime Overview, Section 1.1
Tru64 UNIX Realtime System Capabilities, Section 1.2
Process Synchronization, Section 1.3
POSIX Standards, Section 1.4
Enabling Tru64 UNIX Realtime Features, Section 1.5
Building Realtime Applications, Section 1.6
Realtime applications provide an action or an answer to an external event in a timely and predictable manner. While many realtime applications require high-speed compute power, realtime applications cover a wide range of tasks with differing time dependencies. Timeliness has a different definition in each realtime application. What may be fast in one application may be slow or late in another. For example, an experimenter in high-energy physics needs to collect data in microseconds while a meteorologist monitoring the environment might need to collect data in intervals of several minutes. However, the success of both applications depends on well-defined time requirements.
The concept of predictability has many connotations, but for realtime applications it generally means that a task or set of tasks can always be completed within a predetermined amount of time. Depending on the situation, an unpredictable realtime application can result in loss of data, loss of deadlines, or loss of plant production. Examples of realtime applications include process control, factory automation robotics, vehicle simulation, scientific data acquisition, image processing, built-in test equipment, music or voice synthesis, and analysis of high-energy physics.
To have control over the predictability of an application, the programmer must understand which time bounds are significant. For example, an understanding of the average time it takes for a context switch does not guarantee task completion within a predictable timeframe. Realtime programmers must know the worst-case time requirements so that they can design an application that will always meet worst-case deadlines.
Realtime systems also use techniques to reduce the hazards associated with a worst-case scenario. In some situations, a worst-case realtime deadline may be significantly faster than the nonrealtime, average time.
Realtime applications can be classified as either hard or soft realtime. Hard realtime applications require a response to events within a predetermined amount of time for the application to function properly. If a hard realtime application fails to meet specified deadlines, the application fails. While many hard realtime applications require high-speed responses, the granularity of the timing is not the central issue in a hard realtime application. An example of a hard realtime application is a missile guidance control system, where a late response to a needed correction leads to disaster.
Soft realtime applications do not fail if a deadline is missed. Some soft realtime applications can process large amounts of data or require a very fast response time, but the key issue is whether or not meeting timing constraints is a condition for success. An example of a soft realtime application is an airline reservation system, where an occasional delay is tolerable.
Many realtime applications require high I/O throughput and fast response time to asynchronous external events. The ability to process and store large amounts of data is a key metric for data collection applications. Realtime applications that require high I/O throughput rely on continuous processing of large amounts of data. The primary requirement of such an application is the acquisition of a number of data points equally spaced in time.
High data throughput requirements are typically found in signal-processing applications, such as:
Sonar and radar analysis
Telemetry
Vibration analysis
Speech analysis
Music synthesis
Similarly, a continuous stream of data points must be acquired for many of the qualitative and quantitative methods used in the following types of applications:
Gas and liquid chromatography
Mass spectrometry
Automatic titration
Colorimetry
For some applications, the throughput requirements on any single channel are modest. However, an application may need to handle multiple data channels simultaneously, resulting in a high aggregate throughput. Realtime applications, such as medical diagnosis systems, need a response time of about 1 second while simultaneously handling data from, perhaps, ten external sources.
High I/O throughput may be important for some realtime control systems, but another key metric is the speed at which the application responds to asynchronous external events and its ability to schedule and provide communication among multiple tasks. Realtime applications must capture input parameters, perform decision-making operations, and compute updated output parameters within a given timeframe.
Some realtime applications, such as flight simulation programs, require a response time of microseconds while simultaneously handling data from a large number of external sources. The application might acquire several hundred input parameters from the cockpit controls, compute updated position, orientation, and speed parameters, and then send several hundred output parameters to the cockpit console and a visual display subsystem.
Realtime applications are usually characterized by a blend of requirements.
Some portions of the application may consist of hard, critical tasks, all
of which must meet their deadlines.
Other parts of the application may require
heavy data throughput.
Many parts of a realtime application can easily run
at a lower priority and require no special realtime functionality.
The key
to a successful realtime application is the developer's ability to accurately
define application requirements at every point in the program.
Resource allocation
and realtime priorities are used only when necessary so that the application
is not overdesigned.
1.2 Tru64 UNIX Realtime System Capabilities
The Tru64 UNIX operating system supports facilities to enhance the performance of realtime applications. These realtime facilities make it possible for the operating system to guarantee that the realtime application has access to resources whenever it needs them and for as long as it needs them. That is, the realtime applications running on the operating system can respond to external events regardless of the impact on other executing tasks or processes.
Realtime applications written to run on the operating system make use of and rely on the following system capabilities:
A preemptive kernel
Fixed-priority scheduling policies
Realtime clocks and timers
Memory locking
Asynchronous I/O
File synchronization
Queued realtime signals
Process communication facilities
All of these realtime facilities work together to provide the
realtime environment.
In addition, realtime applications make full use of
process synchronization techniques and facilities, as summarized in
Section 1.3.
1.2.1 The Value of a Preemptive Kernel
The responsiveness of the operating system to asynchronous events is a critical element of realtime systems. Realtime systems must be capable of meeting the demands of hard realtime tasks with tight deadlines. To do this, the operating system's reaction time must be short and the scheduling algorithm must be simple and efficient.
The amount of time it takes for a higher-priority process to displace a lower-priority process is referred to as process preemption latency. In a realtime environment, the primary concern of application designers is the maximum process preemption latency that can occur at run time, the worst-case scenario.
Every application can interact with the operating system in two modes: user mode and kernel mode. User-mode processes call utilities, library functions, and other user applications. A process running in user mode can be preempted by a higher-priority process. During execution, a user-mode process often makes system calls, switching context from user to kernel mode, where the process interacts with the operating system. Under the traditional timesharing scheduling algorithm, a process running in kernel mode cannot be preempted.
A preemptive kernel guarantees that a higher-priority process can quickly
interrupt a lower-priority process, regardless of whether the low-priority
process is in user or kernel mode.
Whenever a higher-priority process becomes
runnable, a preemption is requested, and the higher-priority process displaces
the running, lower-priority process.
1.2.1.1 Nonpreemptive Kernel
The standard UNIX kernel is a nonpreemptive kernel; it does not allow a user process to preempt a process executing in kernel mode. When a running process issues a system call and enters kernel mode, preemptive context switches are disabled until the system call is completed. Although there are context switches, a system call may take an arbitrarily long time to execute without voluntarily giving up the processor. During that time, the process that made the system call may delay the execution of a higher-priority, runnable, realtime process.
The maximum process preemption latency for a nonpreemptive kernel is
the maximum amount of time it can take for the running, kernel-mode process
to switch out of kernel mode back into user mode and then be preempted by
a higher-priority process.
Under these conditions, it is not unusual for worst-case
preemption to take seconds, which is clearly unacceptable for many realtime
applications.
1.2.1.2 Preemptive Kernel
A preemptive kernel, such as the Tru64 UNIX kernel with realtime preemption enabled, allows the operating system to respond quickly to a process preemption request. When a realtime user process engages one of the fixed-priority scheduling policies, the Tru64 UNIX kernel can break out of kernel mode to honor the preemption request.
A preemptive kernel supports the concept of process synchronization with the ability to respond quickly to interrupts while maintaining data integrity. The kernel employs mechanisms to protect the integrity of kernel data structures, and defines restrictions on when the kernel can preempt execution.
The maximum process preemption latency for a preemptive kernel is the
exact amount of time required to preserve system and data integrity and preempt
the running process.
Under these conditions, it is not unusual for worst-case
preemption to take only milliseconds.
1.2.1.3 Comparing Latency
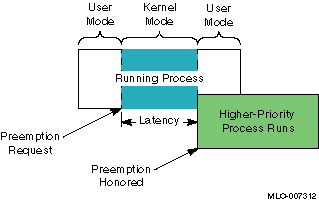
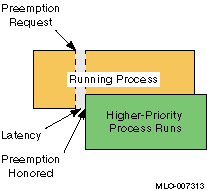
Figure 1-1 and Figure 1-2 illustrate the process preemption latency that can be expected from a nonpreemptive kernel and a preemptive kernel. In both figures, a higher-priority realtime process makes a preemption request, but the amount of elapsed time until the request is honored depends on the kernel. Latency is represented as the shaded area.
Figure 1-1 shows the expected latency of a nonpreemptive kernel. In this situation, the currently running process moves back and forth between user and kernel mode as it executes. The higher-priority, realtime process advances to the beginning of the priority process list, but cannot preempt the running process while it runs in kernel mode. The realtime process must wait until the running process either finishes executing or changes back to user mode before the realtime process is allowed to preempt the running process.
Figure 1-2
shows the expected latency of a preemptive
kernel.
In this situation, the running process is quickly preempted and the
higher-priority, realtime process takes its place on the run queue.
Figure 1-1: Nonpreemptive Kernel
1.2.2 Fixed-Priority Scheduling Policies
The scheduler determines how CPU resources are allocated to executing processes. Each process has a priority that associates the process with a run queue. Each process begins execution with a base priority that can change as the application executes, depending on the algorithm used by the scheduler or application requirements.
The algorithm or set of rules that governs how the scheduler selects runnable processes, how processes are queued, and how much time each process is given to run is called a scheduling policy. Scheduling policies work in conjunction with priority levels. Generally speaking, the higher a process's priority, the more frequently the process is allowed to execute. But the scheduling policy may determine how long the process executes. The realtime application designer balances the nature of the work performed by the process with the process's priority and scheduling policy to control use of system resources.
If the realtime subset is installed on your system, the
operating system supports two distinctly different scheduling interfaces:
the
nice
interface and the realtime interface.
The
nice
interface provides functions for managing nonrealtime applications
running at nonrealtime priority level.
The
nice
interface
uses the timesharing scheduling policy, which allows the scheduler to dynamically
adjust priority levels of a process.
You have access to the realtime scheduling
interface only if you have installed the realtime subset.
The realtime interface supports a nonrealtime (timesharing) scheduling policy and two fixed-priority, preemptive scheduling policies for realtime applications. Under the timesharing scheduling policy, process priorities are automatically adjusted by the scheduler. Under the fixed-priority scheduling policies (round-robin and first-in/first-out), the scheduler never automatically changes the priority of a process. Instead, the application designer determines when it is appropriate for a process to change priorities.
The realtime interface provides a number of functions to allow the realtime application designer to control process execution. In addition, realtime scheduling policies are attached to individual processes, giving the application designer control over individual processes.
POSIX scheduling policies have overlapping priority ranges: The highest
priority range is reserved for realtime applications, the middle priority
range is used by the operating system, and the lowest priority range is used
for nonprivileged user processes.
Realtime priority ranges loosely map to
the
nice
priority range, but provide a wider range of priorities
for a realtime process.
Figure 2-4
illustrates the
priority ranges for both the
nice
and realtime scheduling
interfaces.
Not all realtime processes need to run in the realtime priority range. When using the realtime interface, each process begins execution under the timesharing scheduling policy with an associated timesharing priority. The application designer determines which processes are time-critical and under what circumstances processes should run at an elevated priority level. The application designer calls P1003.1b functions to set the appropriate priority and scheduling policy.
Under the first-in/first-out (SCHED_FIFO) scheduling policy, a running process continues to execute if there are no other higher-priority processes. The user can raise the priority of a running process to avoid its being preempted by another process. Therefore, a high-priority, realtime process running under the first-in/first-out scheduling policy can use system resources as long as necessary to finish realtime tasks.
Under the round-robin (SCHED_RR) scheduling policy, the highest-priority process runs until either its allotted time (quantum) is complete or until the process is preempted by another, higher-priority process. When a process reaches the end of its quantum, it takes its place at the end of the run queue for processes that have the same priority. Processes at that priority continue to execute as long as the waiting processes have lower priorities. Therefore, high-priority processes running under the round-robin scheduling policy can share the processor with other time-critical processes.
When a process raises its priority and preempts a running process, the scheduler saves the run-time context of the preempted process so that context can be restored when the process is allowed to run again. The preempted process remains in a runnable state even though it was preempted.
For information on using priority and scheduling policy
functions, see
Chapter 2.
1.2.3 Realtime Clocks and Timers
Realtime timers often schedule tasks and events in time increments considerably
smaller than the traditional 1-second timeframe.
Because the system clock
and realtime timers use seconds and nanoseconds as the basis for time intervals,
the resolution for the system clock, realtime timers, and the
nanosleep
function has a fine granularity.
For example, in a robotic data
acquisition application, information retrieval and recalculation operations
may need to be completed within a 4-millisecond timeframe.
Timers are created
to fire every 4 milliseconds to trigger the collection of another round of
data.
On expiration, a timer sends a signal to the calling process.
Realtime timers must be flexible enough to allow the application to set timers based on either absolute or relative time. Furthermore, timers must be able to fire as a one-shot or periodic timer. The application creates timers in advance, but specifies timer characteristics when the timer is set.
Realtime applications use timers to coordinate and monitor the correctness of a realtime application. Some applications may require only one per-process timer; others may require multiple timers. Each timer is created and armed independently, which means that the application designer controls the action of each timer.
The system clock provides the timing base for realtime per-process timers, and is the source for timer synchronization. This clock maintains user and system time as well as the current time and date. An option is also available for using a high-resolution clock (see Section 6.1.5).
Clock and timer functions allow you to retrieve and set the system clock, suspend execution for a period of time, provide high-resolution timers, and use asynchronous signal and realtime signal notification.
For information on using clock and timer functions, see
Chapter 6.
1.2.4 Memory Locking
Memory locking is one of the primary tools available to the realtime application designer for reducing latency. Without locking time-critical processes into memory, the latency caused by paging would introduce involuntary and unpredictable time delays at run time.
A realtime application needs a mechanism for guaranteeing that time-critical processes are locked into memory and not subjected to memory management appropriate only for timesharing applications. (In a virtual memory system, a process may have part of its address space paged in and out of memory in response to system demands for critical space.)
The P1003.1b memory-locking functions allow the application designer to lock process address space into memory. The application can lock in not only the current address space, but also any future address space the process may use during execution.
For information on using memory-locking functions, see
Chapter 4.
1.2.5 Asynchronous I/O
Asynchronous I/O allows the calling process to resume execution immediately after an I/O operation is queued, without awaiting completion. Asynchronous I/O is desirable in many different applications, ranging from graphics and file servers to dedicated realtime data acquisition and control systems. The process immediately continues execution, thus overlapping operations.
Often, one process simultaneously performs multiple I/O functions while other processes continue execution. For example, an application may need to gather large quantities of data from multiple channels within a short, bounded period of time. In such a situation, blocking I/O may work at cross purposes with application timing constraints. Asynchronous I/O performs nonblocking I/O, allowing simultaneous reads and writes, which frees processes for additional processing.
Notification of asynchronous I/O completion is optional and can be done
without the overhead of calling signal functions by using the
aiocb
data structure, providing faster interprocess communication.
For information on using asynchronous I/O functions, see
Chapter 7.
1.2.6 Synchronized I/O
Synchronized I/O may be preferable to asynchronous I/O when the integrity of data and files is critical to an application. Synchronized output assures that data that is written to a device is actually stored there. Synchronized input assures that data that is read from a device is a current image of data on that device. For both synchronized input and output, the function does not return until the operation is complete and verified.
Synchronized I/O offers two separate options:
Ensure integrity of file data and file control information
Ensure integrity of file data and only the file control information that is needed to access the data
For information on using synchronized I/O features, see
Chapter 8.
1.2.7 Realtime Interprocess Communication
Interprocess communication (IPC) is the exchange of information between two or more processes. In single-process programming, modules within a single process communicate by using global variables and function calls, with data passing between the functions and the callers. In multiprocess programming with images running in separate address space, you need to use additional communication mechanisms for passing data.
Tru64 UNIX interprocess communication facilities allow the realtime application designer to synchronize independently executing processes by passing data within an application. Processes can pursue their own tasks until they must synchronize with other processes at some predetermined point. When they reach that point, they wait for some form of communication to occur. Interprocess communication can take any of the following forms:
Shared memory (Chapter 3) is the fastest form of interprocess communication. As soon as one process writes data to the shared memory area, it is available to other processes using the same shared memory. Tru64 UNIX supports P1003.1b shared memory.
Signals (Chapter 5) provide a means to communicate to a large number of processes. Signals for timer expiration and asynchronous I/O completion use a data structure, making signal delivery asynchronous, fast, and reliable. POSIX 1003.1b realtime signals include:
A range of priority-ordered, application-specific signals from SIGRTMIN to SIGRTMAX.
A mechanism for queueing signals for delivery to a process.
A mechanism for providing additional information about a signal to the process to which it is delivered.
Features that allow efficient signal delivery to a process when a POSIX 1003.1b timer expires, when a message arrives on an empty message queue, or when an asynchronous I/O operation completes.
Functions that allow a process to respond more quickly to signal delivery.
Semaphores (Chapter 9) are most commonly used to control access to system resources, such as shared-memory regions. Tru64 UNIX supports P1003.1b semaphores.
Messages (Chapter 10) can be used by cooperating processes that communicate by accessing systemwide message queues. The message queue interface is a set of structures and data that allows processes to send and receive messages to a message queue.
Some forms of interprocess communication are traditionally supplied by the operating system and some are specifically modified for use in realtime functions. All allow a user-level or kernel-level process to communicate with a user-level process. Interprocess communication facilities are used to notify processes that an event has occurred or to trigger the process to respond to an application-defined occurrence. Such occurrences can be asynchronous I/O completion, timer expiration, data arrival, or some other user-defined event.
To provide rapid signal communication on timer expiration and asynchronous
I/O completion, these functions send signals through a common data structure.
It is not necessary to call signal functions.
1.3 Process Synchronization
Use of synchronization techniques and restricting access to resources can ensure that critical and noncritical tasks execute at appropriate times with the necessary resources available. Concurrently executing processes require special mechanisms to coordinate their interactions with other processes and their access to shared resources. In addition, processes may need to execute at specified intervals.
Realtime applications synchronize process execution through the following techniques:
Waiting for a specified period of time
Waiting for semaphores
Waiting for communication
Waiting for other processes
The basic mechanism of process synchronization is waiting. A process must synchronize its actions with the arrival of an absolute or relative time, or until a set of conditions is satisfied. Waiting is necessary when one process requires another process to complete a certain action, such as releasing a shared system resource or allowing a specified amount of time to elapse, before processing can continue.
The point at which the continued execution of a process depends on the state of certain conditions is called a synchronization point. Synchronization points represent intersections in the execution paths of otherwise independent processes, in which the actions of one process depend on the actions of another process.
The application designer identifies synchronization points between processes and selects the functions best suited to implement the required synchronization.
The application designer identifies resources, such as message queues and shared memory, that the application will use. Failure to control access to critical resources can result in performance bottlenecks or inconsistent data. For example, the transaction processing application of a national ticket agency must be prepared to process purchases simultaneously from sites around the country. Ticket sales are transactions recorded in a central database. Each transaction must be completed as either rejected or confirmed before the application performs further updates to the database. The application performs the following synchronization operations:
Restricts access to the database
Provides a reasonable response time
Ensures against overbookings
Processes compete for access to the database.
In doing so, some processes
must wait for either confirmation or rejection of a transaction.
1.3.1 Waiting for a Specified Period of Time or an Absolute Time
A process can postpone execution for a specified period of time or until a specified time and date. This synchronization technique allows processes to work periodically and to carry out tasks on a regular basis. To postpone execution for a specified period of time, use one of these methods:
Sleep functions
Per-process timers
The
sleep
function measures time by seconds, while
the
nanosleep
function uses nanoseconds.
The granularity
of the
nanosleep
function may make it more suitable for
realtime applications.
For example, a vehicle simulator application may rely
on retrieval and recalculation operations that are completed every 5 milliseconds.
The application requires a number of per-process timers armed with repetition
intervals that allow the application to retrieve and process information within
the 5-millisecond deadline.
Realtime clocks and timers allow an application to synchronize and coordinate
activities according to a predefined schedule.
Such a schedule might require
repeated execution of one or more processes at specific time intervals or
only once.
A timer is set (armed) by specifying an initial start time value
and an interval time value.
Realtime timing facilities provide applications
with the ability to use relative or absolute time and to schedule events on
a one-shot or periodic basis.
1.3.2 Waiting for Semaphores
The semaphore allows a process to synchronize its access to a resource shared with other processes, most commonly, shared memory. A semaphore is a kernel data structure shared by two or more processes that controls metered access to the shared resource. Metered access means that up to a specified number of processes can access the resource simultaneously. Metered access is achieved by using semaphores.
The semaphore takes its name from the signaling system railroads developed to prevent more than one train from using the same length of track, a technique that enforces exclusive access to the shared resource of the railroad track. A train waiting to enter the protected section of track waits until the semaphore shows that the track is clear, at which time the train enters the track and sets the semaphore to show that the track is in use. Another train approaching the protected track while the first train is using it waits for the signal to show that the track is clear. When the first train leaves the shared section of track, it resets the semaphore to show that the track is clear.
The semaphore protection scheme works only if all the trains using the shared resource cooperate by waiting for the semaphore when the track is busy and resetting the semaphore when they have finished using the track. If a train enters a track marked busy without waiting for the signal that it is clear, a collision can occur. Conversely, if a train exiting the track fails to signal that the track is clear, other trains will think the track is in use and refrain from using it.
The same is true for processes synchronizing their actions through the use of semaphores and shared memory. To gain access to the resource protected by the semaphore, cooperating processes must lock and unlock the semaphore. A calling process must check the state of the semaphore before performing a task. If the semaphore is locked, the process is blocked and waits for the semaphore to become unlocked. Semaphores restrict access to a shared resource by allowing access to only one process at a time.
An application can protect the following resources with semaphores:
Global variables, such as file variables, pointers, counters, and data structures. Synchronizing access to these variables means preventing simultaneous access, which also prevents one process from reading information while another process is writing it.
Hardware resources, such as tape drives. Hardware resources require controlled access for the same reasons as global variables; that is, simultaneous access could result in corrupted data.
The kernel. A semaphore can allow processes to alternate execution by limiting access to the kernel on an alternating basis.
For information on using shared memory and semaphores, see
Chapter 3
and
Chapter 9.
1.3.3 Waiting for Communication
Typically, communication between processes is used to trigger process execution so the flow of execution follows the logical flow of the application design. As the application designer maps out the program algorithm, dependencies are identified for each step in the program. Information concerning the status of each dependency is communicated to the relevant processes so that appropriate action can be taken. Processes synchronize their execution by waiting for something to happen; that is, by waiting for communication that an event occurred or a task was completed. The meaning and purpose of the communication are established by the application designer.
Interprocess communication facilitates application control over the following:
When and how a process executes
The sequence of execution of processes
How resources are allocated to service requests from the processes
Section 1.2.7
introduced the forms of interprocess
communication available to the realtime application designer.
For further
information on using interprocess communication facilities, see
Chapter 3,
Chapter 5,
Chapter 9,
and
Chapter 10.
1.3.4 Waiting for Another Process
Waiting for another process means waiting until that process has terminated. For example, a parent process can wait for a child process or thread to terminate. The parent process creates a child process, which needs to complete some task before the waiting parent process can continue. In such a situation, the actions of the parent and child processes are sometimes synchronized in the following way:
The parent process creates the child process.
The parent process synchronizes with the child process.
The child process executes until it terminates.
The termination of the child process signals the parent process.
The parent process resumes execution.
The parent process can continue execution in parallel with the child process. However, if child processes are used as a form of process synchronization, the parent process can use other synchronization mechanisms, such as signals and semaphores, while the child process executes.
For information on using signals, see
Chapter 5,
and for information on using semaphores, see
Chapter 9.
1.3.5 Realtime Needs and System Solutions
Table 1-1
summarizes the common realtime needs
and the solutions available through P1003.1b functions and the Tru64 UNIX
operating system.
The realtime needs in the left column of the table are
ordered according to their requirement for fast system performance.
Table 1-1: Realtime Needs and System Solutions
| Realtime Need | Realtime System Solution |
| Change the availability of a process for scheduling | Use scheduler functions to set the scheduling policy and priority of the process |
| Keep critical code or data highly accessible | Use memory-locking functions to lock the process address space into memory |
| Perform an operation while another operation is in progress | Create a child process or separate thread, or use asynchronous I/O |
| Perform higher throughput or special-purpose I/O | Use asynchronous I/O |
| Ensure that data read from a device is actually a current image of data on that device, or that data written to a device is actually stored on that device | Use synchronized I/O |
| Share data between processes | Use shared memory, or use memory-mapped files |
| Synchronize access to resources shared between cooperating processes | Use semaphores |
| Communicate between processes | Use messages, semaphores, shared memory, signals, pipes, and named pipes |
| Synchronize a process with a time schedule | Set and arm per-process timers |
| Synchronize a process with an external event or program | Use signals, use semaphores, or cause the process to sleep and to awaken when needed |
The purpose of standards is to enhance the portability of programs and applications; that is, to support creation of code that is independent of the hardware or even the operating system on which the application runs. Standards allow users to move between systems without major retraining. In addition, standards introduce internationalization concepts as part of application portability.
The POSIX standards and draft standards apply to the operating system. For the most part, these standards apply to applications coded in the C language. These standards are not mutually exclusive; the Tru64 UNIX realtime environment uses a complement of these standards.
POSIX is a set of standards generated and maintained by standards organizations -- they are developed and approved by the Institute of Electrical and Electronics Engineers, Inc. (IEEE) and adopted by the International Organization for Standardization (ISO) and the International Electrotechnical Commission (IEC). Compaq's POSIX implementations follow the standards and drafts defined by the POSIX standards.
Formal standards to date include POSIX 1003.1 for basic system interfaces, and POSIX 1003.13 for assertions a vendor must test to claim conformance to POSIX 1003.1. Draft standards are not formal standards. They are working documents that will evolve over time into formal standards.
Tru64 UNIX supports POSIX standards for a programming interface, threads, and realtime programming extensions, as follows:
POSIX 1003.1 defines the standard for basic system services on an operating system and describes how system services can be used by POSIX applications. These services allow an application to perform such operations as process creation and execution, file system access, and I/O device management.
POSIX 1003.1c defines a set of thread functions that can be used in the design and creation of multithreaded realtime applications.
POSIX 1003.1b provides support for functions that support the needs of realtime applications, such as enhanced interprocess communication, scheduling and memory management control, asynchronous I/O operations, and file synchronization.
As Compaq adds support for evolving and final standards, customers should modify their POSIX applications to conform to the latest version of these standards. Because draft standards are working documents and not formal standards, the level of backward compatibility and formal support for older versions (drafts) will be less than that normally expected from a stable Compaq product.
An application that strictly conforms to any combination of these standards can be developed on one system and then ported to another system that supports the same POSIX standards. (A strictly conforming application uses only the facilities within the applicable standards.) Similarly, an application developed on a non-Compaq platform, if it strictly conforms to the POSIX standards and drafts supported by Compaq systems, can be ported and run on a Compaq system on which the POSIX software is installed.
It is the source code of an application that is portable. Most applications written for a POSIX environment use the C programming language. Each system that supports a POSIX environment includes POSIX run-time libraries and C run-time libraries. A portable application that requires an executable image must be compiled and linked on a system after being ported. It is important that you compile and link your POSIX applications against the run-time libraries on the system where they will run.
The POSIX standards are based on the UNIX environment.
However, POSIX
specifies an interface to an operating system, not the operating system itself.
Additional information on POSIX standards is contained in the
IEEE Standard Portable Operating System Interface for Computer Environments
manuals, published by the Institute of Electrical and Electronics
Engineers, Inc.
1.5 Enabling Tru64 UNIX Realtime Features
The files that make up the realtime facility are included with the base system software, and are installed when you choose the realtime option during installation. This provides extended features, such as realtime preemption and symmetric multiprocessing.
Note
If you installed Tru64 UNIX with the default options, realtime preemption is disabled. To enable realtime preemption, the system configuration parameter
rt_preempt_optmust be set to 1. See the Installation Guide for complete instructions.
1.6 Building Realtime Applications
To build a Tru64 UNIX realtime application, you must first define
the POSIX environment, then compile the application with the appropriate compile
command switches.
These steps draw POSIX header information and realtime libraries
into your code.
1.6.1 Defining the POSIX Environment
Realtime applications should include the
unistd.h
header file before they include any other
header files.
This header file defines the standard macros, for
example _POSIX_C_SOURCE, that are required to compile programs
containing POSIX 1003.1b functions.
If you need to exclude any of the
standards definitions provided by the
unistd.h
header file, you should explicitly define those standards macros in the
source file or on the compilation command line.
As a general rule, use specific definitions in your application
only
if your application must
exclude
certain
definitions related to other unneeded standards, such as XPG3.
For example,
if you defined _POSIX_C_SOURCE (#define _POSIX_C_SOURCE 199506L)
in your application, you would get
only
the definitions
for POSIX 1003.1b and other definitions pulled in by that definition, such
as POSIX 1003.1.
Restriction
Currently, one known anomaly is associated with explicitly defining _POSIX_C_SOURCE in your application (or on the compile line). The symbol SA_SIGINFO, defined in
sys/signal.h, is not visible under certain namespace conditions when _POSIX_C_SOURCE is explicitly defined.If you do not explicitly define _POSIX_C_SOURCE, and instead allow it to be implicitly defined by
unistd.h, the SA_SIGINFO symbol is visible.However, if you must explicitly define _POSIX_C_SOURCE, then you can make SA_SIGINFO visible if you also explicitly define _OSF_SOURCE.
The following example shows the code you would include as the first line of code in either your local header file or your application code:
#include <unistd.h>
Because the
unistd.h
header file defines all the
standards needed for realtime applications, it is important that this
#include
is the first line of code in your application.
1.6.2 Compiling and Linking Realtime Applications
When you compile realtime applications, you must explicitly load
the required realtime run-time library,
librt, and,
if asynchronous I/O is used, the required asynchronous I/O run-time
library,
libaio.
1.6.2.1 Compiling Realtime Applications
Realtime applications require the realtime library,
librt.
The
librt
library provides the following functions to support realtime
programming:
P1003.1b priority scheduling functions
P1003.1b clock functions
P1003.1b timer functions
P1003.1b memory-locking functions
P1003.1b message functions
P1003.1b shared-memory functions
P1003.1b semaphore functions
P1003.1b realtime signal functions
You can specify the realtime shareable library,
librt.so,
or the static library,
librt.a.
(To use
librt.a, your Tru64 UNIX system installation
must include Software Development Software Subset
OSFLIBAnnn, Static Libraries.)
The following example specifies that the realtime shareable
library,
librt.so, is to be included from the
/usr/shlib
directory:
# cc myprogram.c -L/usr/shlib -lrt
The
-l
switch specifies the name of a library
(omitting its
lib- prefix) to include.
The
-L
switch indicates the search path for the linker to use to locate
libraries.
To find the realtime library, the
ld
linker expands
the command specification by replacing the
-l
with
lib
and adding the specified library characters and the
appropriate suffix,
.so
or
.a.
Because the linker searches default directories in an
attempt to locate the realtime run-time library, you must specify the pathname
if you do not want to use the default.
The following example specifies that the realtime static
library,
librt.a, is to be included from the
/usr/ccs/lib
directory:
# cc -non_shared myprogram.c -L/usr/ccs/lib -lrt
The realtime library uses the
libc
library.
When
you compile an application, the
libc
library is automatically
pulled into the compilation.
For most compiler drivers, you can view the compilation phases of
the driver program and the libraries being searched by specifying the
-v
option on the compile command.
1.6.2.2 Compiling Realtime Applications That Use Asynchronous I/O
Realtime applications that use asynchronous I/O
require the asynchronous I/O shareable run-time library,
libaio.
(If your application performs
asynchronous I/O to raw partitions rather than files, you require
libaio_raw; see
Section 7.3.)
The
libaio
library provides P1003.1b
asynchronous I/O functions.
When you compile an application that uses asynchronous I/O, you must
also specify
-pthread
on the compile command line.
Doing so directs the linker to use threadsafe libraries
and to include the P1003.1c POSIX Threads interfaces from
libpthread.so.
The following example specifies that the asynchronous I/O shareable run-time
library,
libaio.so, is to be included from the
/usr/shlib
directory:
# cc myprogram.c -L/usr/shlib -laio -pthread
1.6.2.3 Linking a Previously Compiled Realtime Application
Should a situation require you to just link (not compile)
your realtime application,
you must explicitly include the
libc
library.
Because files are processed in the order in which they appear on the link command
line,
libc
must appear after
librt.
For example, you would link an application with the realtime shareable library,
librt.so, as follows:
# ld myprogram.o -L/usr/shlib -lrt -lc