This chapter contains information on the following topics:
Compiler system components (Section 2.1)
Data types in the Tru64 UNIX environment (Section 2.2)
Using the C preprocessor (Section 2.3)
Compiling source programs (Section 2.4)
Linking object files (Section 2.5)
Running programs (Section 2.6)
Object file tools (Section 2.7)
ANSI name space pollution cleanup in the standard C library (Section 2.8)
The compiler system is responsible for converting source code into an executable program. This can involve several steps:
Preprocessing -- The compiler system performs such operations as expanding macro definitions or including header files in the source code.
Compiling -- The compiler system converts a source file
or preprocessed file to an object file with the
.o
file
suffix.
Linking -- The compiler system produces a binary image.
These steps can be performed by separate preprocessing, compiling, and linking commands, or they can be performed in a single operation, with the compiler system calling each tool at the appropriate time during the compilation.
Other tools in the compiler system help debug the program after it has been compiled and linked, examine the object files that are produced, create libraries of routines, or analyze the run-time performance of the program.
Table 2-1
summarizes the tools in the compiler
system and points to the chapter or section where they are described in this
and other documents.
Table 2-1: Compiler System Functions
| Task | Tools | Where Documented |
| Compile, link, and load programs; build shared libraries | Compiler drivers, link editor, dynamic loader | This chapter, Chapter 4,
cc(1),
c89(1),
as(1),
ld(1),
loader(5),
Assembly Language Programmer's Guide,
Compaq C Language Reference Manual |
| Debug programs | Symbolic debugger (dbx
and
ladebug) and Third Degree |
Chapter 5, Chapter 6,
dbx(1),
third(5),
ladebug(1),
Ladebug Debugger Manual |
| Profile programs | Profiler, call graph profiler | Chapter 8,
prof(1),
gprof(1),
pixie(5),
atom(1),
hiprof(5),
atomtools(5) |
| Optimize programs | Optimizer, postlink optimizer | This chapter, Chapter 10,
cc(1),
third(5) |
| Examine object files | nm,
file,
size,
dis,
odump, and
stdump
tools |
This chapter,
nm(1),
file(1),
size(1),
dis(1),
odump(1),
stdump(1),
Programming Support Tools |
| Produce necessary libraries | Archiver (ar), linker
(ld) command |
This chapter, Chapter 4,
ar(1),
ld(1) |
2.1 Compiler System Components
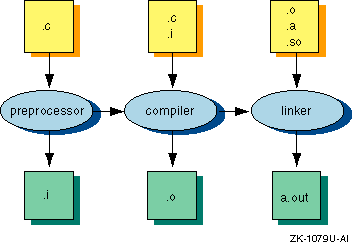
Figure 2-1
shows the relationship between the major components of the compiler system
and their primary inputs and outputs.
Figure 2-1: Compiling a Program
Compiler system commands, sometimes called driver programs, invoke the components of the compiler system. Each language has its own set of compiler commands and options.
The
cc
command invokes the C compiler.
In the Tru64 UNIX
programming environment, a single
cc
compiler command can
perform multiple actions, including the following:
Determine whether to call the appropriate preprocessor, compiler (or assembler), or linker based on the file name suffix of each file. Table 2-2 lists the supported file suffixes, which identify the contents of the input files.
Compile and link a source file to create an executable program. If multiple source files are specified, the files can be passed to other compilers before linking.
Assemble
one or more
.s
files, which are assumed to contain assembler
code, by calling the
as
assembler, and link the resulting
object files.
(Note that if you directly invoke the assembler, you need to
link the object files in a separate step; the
as
command
does not automatically link assembled object files.)
Prevent linking and the creation of the executable program,
thereby retaining the
.o
object file for a subsequent link
operation.
Pass the major options associated with the link command (ld) to the linker.
For example, you can include the
-L
option as part of the
cc
command to specify the directory path to search for a library.
Each language requires different libraries at link time; the driver program
for a language passes the appropriate libraries to the linker.
For more information
on linking with libraries, see
Chapter 4
and
Section 2.5.3.
Create an executable program file
with a default name of
a.out
or with
a name that you specify.
Table 2-2: File Suffixes and Associated Files
| Suffix | File |
.a |
Archive library |
.c |
C source code |
.i |
The driver assumes that the source code was
processed by the C preprocessor and that the source code is that of the processing
driver; for example,
% cc -c source.i.
The file,
source.i, is assumed to contain C
source code. |
.o |
Object file. |
.s |
Assembly source code. |
.so |
Shared object (shared library). |
2.2 Data Types in the Tru64 UNIX Environment
The following sections describe how data items are represented on the Tru64 UNIX system.
Note
The default memory access size on a Tru64 UNIX system is 8 bytes (quadword). This means that when two or more threads of execution are concurrently modifying adjacent memory locations, those locations must be quadword aligned to protect the individual modifications from being erroneously overwritten. Errors can occur, for example, if separate data items stored within a single quadword of a composite data structure are being concurrently modified.
For details on the problems that non-quadword alignment can cause and the various situations in which the problems can occur, see the Granularity Considerations section in the Guide to the POSIX Threads Library.
The Tru64 UNIX system is little-endian; that is, the address of a multibyte integer is the address of its least significant byte and the more significant bytes are at higher addresses. The C compiler supports only little-endian byte ordering. The following table gives the sizes of supported data types:
| Data Type | Size, in Bits |
char |
8 |
short |
16 |
int |
32 |
long |
64 |
long long |
64 |
float |
32 (IEEE single) |
double |
64 (IEEE double) |
pointer |
64 [Footnote 1] |
long double |
128 |
2.2.2 Floating-Point Range and Processing
The C compiler supports IEEE single-precision
(32-bit
float) and double-precision (64-bit
double) floating-point data, as defined by the
IEEE Standard for Binary Floating-Point Arithmetic
(ANSI/IEEE Std 754-1985).
Floating-point numbers have the following ranges:
float: 1.17549435e-38f to 3.40282347e+38f
double: 2.2250738585072014e-308 to 1.79769313486231570e+308
Tru64 UNIX provides the basic floating-point number formats, operations
(add, subtract, multiply, divide, square root, remainder, and compare), and
conversions defined in the standard.
You can obtain full IEEE-compliant trapping
behavior (including NaN [not-a-number]) by specifying a compilation option,
or by specifying a fast mode when IEEE-style traps are not required.
You can
also select, at compile time, the rounding mode applied to the results of
IEEE operations.
See
cc(1)
for information on the options that support IEEE
floating-point processing.
A user program can control the delivery of floating-point traps to a
thread by calling
ieee_set_fp_control(), or dynamically
set the IEEE rounding mode by calling
write_rnd().
See
ieee(3)
for more information on how to handle IEEE floating-point exceptions.
2.2.3 Structure Alignment
The C compiler aligns structure members on natural boundaries by default. That is, the components of a structure are laid out in memory in the order in which they are declared. The first component has the same address as the entire structure. Each additional component follows its predecessor on the next natural boundary for the component type.
For example, the following structure is aligned as shown in Figure 2-2:
struct {char c1;
short s1;
float f;
char c2;
}
Figure 2-2: Default Structure Alignment
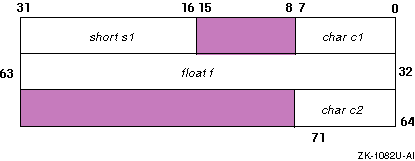
The first component of the structure,
c1, starts
at offset 0 and occupies the first byte.
The second component,
s1, is a
short; it must start on a word boundary.
Therefore, padding is added between
c1
and
s1.
No padding is needed to make
f
and
c2
fall on their natural boundaries.
However, because size is rounded
up to a multiple of
f's alignment, three bytes of padding
are added after
c2.
You can use the following mechanisms to override the default alignment of structure members:
The
#pragma member_alignment
and
#pragma nomember_alignment
directives
The
#pragma pack
directive
The
-Zpn
option
See
Section 3.6
and
Section 3.8
for information on these directives.
2.2.4 Bit-Field Alignment
In general, the alignment of a bit field is determined by the bit size and bit offset of the previous field. For example, the following structure is aligned as shown in Figure 2-3:
struct a {
char f0: 1;
short f1: 12;
char f2: 3;
} struct_a;
Figure 2-3: Default Bit-Field Alignment
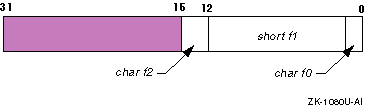
The first bit field,
f0, starts on bit offset 0 and
occupies 1 bit.
The second,
f1, starts at offset 1 and
occupies 12 bits.
The third,
f2, starts at offset 13 and
occupies 3 bits.
The size of the structure is two bytes.
Certain conditions can cause padding to occur prior to the alignment of the bit field:
Bit fields of size 0 cause padding to the next pack boundary.
(The pack boundary is determined by the
#pragma pack
directive
or the
-Zpn
compiler option.)
For bit fields of size 0, the bit field's base type is ignored.
For example,
consider the following structure:
struct b {
char f0: 1;
int : 0;
char f1: 2;
} struct_b;
If the source file is compiled with the
-Zp1
option or if a
#pragma pack 1
directive is encountered in the compilation,
f0
would start at offset 0 and occupy 1 bit, the unnamed bit field would start
at offset 8 and occupy 0 bits, and
f1
would start at offset
8 and occupy 2 bits.
Similarly, if the
-Zp2
option or the
#pragma pack 2
directive were used,
the unnamed bit field would start at offset 16.
With
-Zp4
or
#pragma pack 4, it would
start at offset 32.
If the bit field does not fit in the current unit, padding
occurs to either the next pack boundary or the next unit boundary, whichever
is closest.
(The unit boundary is determined by the bit field's base type;
for example, the unit boundary associated with the declaration "char foo: 1" is a byte.) The current unit is determined by
the current offset, the bit field's base size, and the kind of packing specified,
as shown in the following example:
struct c {
char f0: 7;
short f1: 11;
} struct_c;
Assuming that you specify either the
-Zp1
option or the
#pragma pack 1
directive,
f0
starts on bit offset 0 and occupies
7 bits in the structure.
Because the base size of
f1
is
8 bits and the current offset is 7,
f1
will not fit in
the current unit.
Padding is added to reach the next unit boundary or the
next pack boundary, whichever comes first, in this case, bit 8.
The layout
of this structure is shown in
Figure 2-4.
Figure 2-4: Padding to the Next Pack Boundary

2.2.5 The _ _align Storage Class Modifier
Data alignment is implied
by data type.
For example, the C compiler aligns an
int
(32 bits) on a 4-byte boundary and a
long
(64 bits) on
an 8-byte boundary.
The
_ _align
storage-class modifier
aligns objects of any of the C data types on the specified storage boundary.
It can be used in a data declaration or definition.
The
_ _align
modifier has the following format:
_ _align (keyword)
_ _align (n)
Where keyword is a predefined alignment constant and n is an integer power of 2. The predefined constant or power of 2 tells the compiler the number of bytes to pad in order to align the data.
For example, to align an integer on the next quadword boundary, use any of the following declarations:
int _ _align( QUADWORD ) data; int _ _align( quadword ) data; int _ _align( 3 ) data;
In this example,
int _ _align ( 3 )
specifies an alignment of 2x2x2 bytes, which is 8 bytes, or a quadword of
memory.
The following table shows the predefined alignment constants, their equivalent power of 2, and equivalent number of bytes:
| Constant | Power of 2 | Number of Bytes |
| BYTE or byte | 0 | 1 |
| WORD or word | 1 | 2 |
| LONGWORD or longword | 2 | 4 |
| QUADWORD or quadword | 3 | 8 |
The
C preprocessor performs macro expansion, includes header files, and executes
preprocessor directives prior to compiling the source file.
The following
sections describe the Tru64 UNIX specific operations performed by the
C preprocessor.
For more information on the C preprocessor, see
cc(1),
cpp(1),
and the
Compaq C Language Reference Manual.
2.3.1 Predefined Macros
When the compiler is invoked, it defines C preprocessor
macros that identify the language of the input files and the environments
on which the code can run.
See
cc(1)
for a list of the preprocessor macros.
You can reference these macros in
#ifdef
statements to
isolate code that applies to a particular language or environment.
Use the
following statement to uniquely identify Tru64 UNIX:
#if defined (_ _digital_ _) && defined (_ _unix_ _)
The type of source file and the type of standards you apply determine the macros that are defined. The C compiler supports several levels of standardization:
The
-std
option enforces the ANSI
C standard, but allows some common programming practices disallowed by the
standard, and defines the macro
_ _STDC_ _
to be 0 (zero).
This is the default.
The
-std0
option enforces the Kernighan
and Ritchie (K & R) programming style, with certain ANSI extensions in
areas where the K & R behavior is undefined or ambiguous.
In general,
-std0
compiles most pre-ANSI C programs
and produces expected results.
It does not define the
_ _STDC_ _
macro.
The
-std1
option strictly enforces
the ANSI C standard and all of its prohibitions (such as those that apply
to handling a
void, the definition of an
lvalue
in expressions, the mixing of integrals and pointers, and the modification
of an
rvalue).
It defines the
_ _STDC_ _
macro to be 1.
Header files are typically used for the following purposes:
To define interfaces to system libraries
To define constants, types, and function prototypes common to separately compiled modules in a large application
C header files, sometimes known as include files, have a
.h
suffix.
Typically, the reference page for a library routine or
system call indicates the required header files.
Header files can be used
in programs written in different languages.
Note
If you intend to debug your program using
dbxorladebug, do not place executable code in a header file. The debugger interprets a header file as one line of source code; none of the source lines in the file appears during the debugging session. For more information on thedbxdebugger, see Chapter 5. For details onladebug, see the Ladebug Debugger Manual.
You can include header files in a program source file in one of two ways:
#include "filename"This indicates that the C macro preprocessor should first
search for the include file
filename
in the directory
in which it found the file that contains the directive, then in the search
path indicated by the
-I
options, and finally in
/usr/include.
#include <filename>This indicates that the C macro preprocessor should search
for the include file
filename
in the search path
indicated by the
-I
options and then in
/usr/include, but not in the directory where it found the file that
contains the directive.
You can also use the
-Idir
and
-nocurrent_include
options to specify additional pathnames
(directories) to be searched by the C preprocessor for
#include
files:
For
-Idir, the
C preprocessor searches first in the directory where it found the file that
contains the directive, followed by the specified pathname (dir), and then the default directory (/usr/include).
If
dir
is omitted, the default directory
is not searched.
For
-I
with no arguments, the C preprocessor
does not search in
/usr/include.
For
-nocurrent_include, the C preprocessor
does not search the directory containing the file that contains the
#include
directive; that is,
#include "filename"
is treated the same as
#include <filename>.
2.3.3 Setting Up Multilanguage Include Files
C, Fortran, and assembly
code can reside in the same include files, and can then be conditionally included
in programs as required.
To set up a shareable include file, you must create
a
.h
file and enter the respective code, as shown in the
following example:
#ifdef _ _LANGUAGE_C_ _
.
. (C code)
.
#endif
#ifdef _ _LANGUAGE_ASSEMBLY_ _
.
. (assembly code)
.
#endif
When the compiler includes this file in a C source file, the
_ _LANGUAGE_C_ _
macro is defined and the C code is
compiled.
When the compiler includes this file in an assembly language source
file, the
_ _LANGUAGE_ASSEMBLY_ _
macro is
defined, and the assembly language code is compiled.
2.3.4 Implementation-Specific Preprocessor Directives (#pragma)
The
#pragma
directive
is a standard method of implementing features that vary from one compiler
to the next.
The C compiler supports the following implementation-specific
pragmas:
#pragma environment
#pragma extern_prefix
#pragma function
#pragma inline
#pragma intrinsic
#pragma linkage
#pragma member_alignment
#pragma message
#pragma pack
#pragma pointer_size
#pragma use_linkage
#pragma weak
Chapter 3
provides detailed descriptions of these
pragmas.
2.4 Compiling Source Programs
The compilation environment established by the
cc
command produces object files that comply with the common object
file format (COFF).
Options supported by the
cc
command select
a variety of program development functions, including debugging, optimizing,
and profiling facilities, and the names assigned to output files.
See
cc(1)
for
details on
cc
command-line options.
The following sections describe the default compiler behavior and how
to compile multilanguage programs.
2.4.1 Default Compilation Behavior
Most compiler options have default values that are used if the option
is not specified on the command line.
For example, the default name for an
output file is
filename.o
for
object files, where
filename
is the base name of
the source file.
The default name for an executable program object is
a.out.
The following example uses the defaults in compiling
two source files named
prog1.c
and
prog2.c:
%cc prog1.c prog2.c
This command runs the C compiler, creating object files
prog1.o
and
prog2.o
and the executable program
a.out.
When you enter the
cc
compiler
command with no other options, the following options are in effect:
Turns off ANSI C aliasing rules, which prevents the optimizer from being aggressive in its optimizations.
Generates instructions that are appropriate for all Alpha processors.
Allows the compiler to make such an assumption, and thereby generate more efficient code for pointer dereferences of aligned pointer types.
Allows the
compiler to make the assumption that the program might interrogate
errno
after any call to a math library routine that is capable of
setting
errno.
Produces a dynamic executable file that uses shareable objects at run time.
Disables the run-time checking of array bounds.
Causes the C macro preprocessor to be called on C and assembly source files before compiling.
Limits the number of error-level diagnostics that the compiler will output for a given compilation to 30.
Informs the compiler that
it is not necessary to promote expressions of type
float
to type
double.
Directs the compiler not to reorder floating-point computations in a way that might affect accuracy.
Performs normal rounding (unbiased round to nearest) of floating-point numbers.
Generates instructions that do not generate floating-point underflow or inexact trapping modes.
Does not produce symbol information for symbolic debugging.
Specifies that
#include
files whose names do not begin with a slash (/) are always
sought first in the directory
/usr/include.
Inlines only those
function calls explicitly requested for inlining by a
#pragma inline
directive.
Directs the compiler to recognize certain functions as intrinsics and perform appropriate optimizations.
Directs the compiler to naturally align data structure members (with the exception of bit-field members).
Generates alignment faults for arbitrarily aligned addresses.
Sets the nesting level limit for include files to 50.
Enables global optimizations.
Disables profiling.
Turns off
gprof
profiling.
Allows symbol preemption on a module-by-module basis.
Suppresses messages
for nonportable constructs in header files whose pathnames are prefixed with
/usr/include.
Causes type
char
to use the same representation as
signed char.
Enforces the ANSI C standard, but allows some common programming practices disallowed by the standard.
Selects instruction tuning that is appropriate for all implementations of the Alpha architecture.
Makes string literals writable.
The following list includes miscellaneous aspects of the default
cc
compiler behavior:
Source files are automatically linked if compilation (or assembly) is successful.
The output file is named
a.out
unless another
name is specified by using the
-o
option.
Floating-point computations are fast floating point, not full IEEE.
Pointers are 64 bits. For information on using 32-bit pointers, see Appendix A.
Temporary files are placed in the
/tmp
directory or the directory specified by the environment variable
$TMPDIR.
2.4.2 Compiling Multilanguage Programs
When the source language of the main program differs from that
of a subprogram, compile each program separately with the appropriate driver
and link the object files in a separate step.
You can create objects suitable
for linking by specifying the
-c
option, which stops a
driver immediately after the object file has been created.
For example:
%cc -c main.c
This command produces the object file
main.o, not
the executable file
a.out.
After creating object modules for source files written in languages
other than C, you can use the
cc
command to compile C
source files and link all of the object modules into an executable file.
For
example, the following
cc
command compiles
c-prog.c
and links
c-prog.o
and
nonc-prog.o
into the executable file
a.out:
%cc nonc-prog.o c-prog.c
2.4.3 Enabling Run-Time Checking of Array Bounds
The
cc
command's
-check_bounds
option
generates run-time code to perform array bounds verification.
The
-nocheck_bounds
option (the default) disables the run-time checking
of array bounds.
The kind of code that causes the compiler to emit run-time checks, and the exact bounds values used in a given check, are subject to certain characteristics of the compiler implementation that would not be obvious to a user. The exact conditions, which assume a good understanding of the C language rules involving arrays, are as follows:
Checks are made only when the name of a declared array object is used. No checks are made when a pointer value is used, even if the pointer is dereferenced using the subscript operator. This means, for example, that no checks are made on formal parameters declared as arrays of one dimension because they are considered pointers in the C language. However, if a formal parameter is a multidimensional array, the first subscript represents a pointer-manipulation that determines the array object to be accessed, and that bound cannot be checked, but bounds checks are generated for the second and subsequent subscripts.
If an array is accessed using the subscript operator (as either the left or right operand) and the subscript operator is not the operand of an address-of operator, the check is for whether the index is between zero and the number of elements in the array minus one inclusive.
If an array is accessed using the subscript operator (as either the left or right operand) and the subscript operator is the operand of the address-of operator, the check is for whether the index is between zero and the number of elements in the array inclusive. The C language specifically requires that it be valid to use the address that is one past the end of an array in a computation, to allow such common programming practice as loop termination tests like:
int a[10];
int *b;
for (b = a ; b < &a[10] ; b++) { .... }
In this case, the use of
&a[10]
is allowed even
though
a[10]
is outside the bounds of the array.
If the array is being accessed using pointer addition, the check is for whether the value being added is between zero and the number of elements in the array inclusive. Adding an integer to an array name involves converting the array name to a pointer to the first element and adding the integer value scaled by the size of an element. The implementation of bounds checking in the compiler is triggered by the conversion of the array name to a pointer, but at the point in time when the bounds check is introduced, it is not known whether the resulting pointer value will be dereferenced. Therefore, this case is treated like the previous case: only the computation of the address is checked and it is valid to compute the address of one element beyond the end of the array.
If the array is being accessed using pointer subtraction (that is, the subraction of an integer value from a pointer, not the subtraction of one pointer from another), the check is for whether the value being subtracted is between the negation of the number of elements in the array and zero inclusive.
Note that in the last three cases, an optional compile-time message
(ident SUBSCRBOUNDS2) can be enabled to detect the case
where an array has been accessed using either a constant subscript or constant
pointer arithmetic, and the element accessed is exactly one past the end of
the array.
No check is made for arrays declared with one element.
Because
ANSI C does not allow arrays without dimensions inside
struct
declarations, it is common practice to implement a dynamic-sized array as
a
struct
that holds the number of elements allocated in
some member, and whose last member is an array declared with one element.
Because accesses to the final array member are intended to be bounded by the
run-time allocated size, it is not useful to check against the declared bound
of 1.
Note that in this case, an optional compile-time message (ident SUBSCRBOUNDS1) can be enabled to detect the case where an
array declared with a single element has been accessed using either a constant
subscript or constant pointer arithmetic, and the element accessed is not
part of the array.
The compiler will emit run-time checks for arrays indexed by constants (even though the compiler can and does detect this case at compile-time). An exception would be that no run-time check is made if the compiler can determine that the access is valid.
If a multidimensional array is accessed, the compiler will
perform checks on each of the subscript expressions, making sure each is within
the corresponding bound.
So, for the following code the compiler will check
that both
x
and
y
are between 0 and
9 (it will not check that
10 * x + y
is between 0 and 99):
int a[10][10]; int x,y,z; x = a[x][y];
The following examples illustrate these rules:
int a[10];
int *b;
int c;
int *d;
int one[1];
int vla[c]; // C9X variable-length array
a[c] = 1; // check c is 0-9, array subscript
c[a] = 1; // check c is 0-9, array subscript
b[c] = 1; // no check, b is a pointer
d = a + c; // check c is 0-10, computing address
d = b + c; // no check, b is a pointer
b = &a[c] // check c is 0-10, computing address
*(a + c) = 1; // check c is 0-10, computing address
*(a - c) = 1; // check c is -10 to 0, computing address
a[1] = 1; // no run-time check - know access is valid
vla[1] = 1; // run-time check, vla has run-time bounds
a[10] = 1; // run-time check (and compiler diagnostic)
d = a + 10; // no run-time check, computing address
// SUBSCRBOUNDS2 message can be enabled
c = one[5]; // no run-time check, array of one element
// SUBSCRBOUNDS1 message can be enabled
When an out-of-bounds access is encountered, the output is as follows:
Trace/BPT trap (core dumped)
A program can trap this error with the following code:
signal(SIGTRAP, handler);
Note that when run-time checking is enabled, incorrect checks might be made in certain cases where arrays are legitimately accessed using pointer arithmetic.
The compiler is only able to output the checking code for the first
arithmetic operation performed on a pointer that results from converting an
array name to a pointer.
This can result in an incorrect check if the resulting
pointer value is again operated on by pointer arithmetic.
Consider the expression
a = b + c - d, where
a
is a pointer,
b
is an array, and
c
and
d
are integers.
When bounds-checking is enabled, a check will be made to verify
that
c
is within the bounds of the array.
This will lead
to an incorrect run-time trap in cases where
c
is outside
the bounds of the array but
c - d
is not.
In these cases, you can recode the pointer expression so that the integer part is in parentheses. This way, the expression will contain only one pointer arithmetic operation and the correct check will be made. In the previous example, the expression would be changed to the following:
a = b + (c - d);
The
cc
driver command
can link object files to produce an executable program.
In some cases, you
may want to use the
ld
linker directly.
Depending on the
nature of the application, you must decide whether to compile and link separately
or to compile and link with one compiler command.
Factors to consider include:
Whether all source files are in the same language
Whether any files are in source form
2.5.1 Linking with Compiler Commands
You can use a compiler command instead
of the linker command to link separate objects into one executable program.
Each compiler (except the assembler) recognizes the
.o
suffix as the name of a file that contains object code suitable for linking
and immediately invokes the linker.
Because the compiler driver programs pass the libraries associated with
that language to the linker, using the compiler command is usually recommended.
For example, the
cc
driver uses the C library (libc.so) by default.
For information about the default libraries
used by each compiler command, see the appropriate command in the reference
pages, such as
cc(1).
You can also use the
-l
option of the
cc
command to specify additional libraries to be searched for unresolved
references.
The following example shows how to use the
cc
driver to pass the names of two libraries to the linker with the
-l
option:
%cc -o all main.o more.o rest.o -lm -lexc
The
-lm
option specifies the math library; the
-lexc
option specifies the exception library.
Compile and link modules with a single command when you want to optimize your program. Most compilers support increasing levels of optimization with the use of certain options. For example:
The
-O0
option requests no optimization
(usually for debugging purposes).
The
-O1
option requests certain local (module-specific)
optimizations.
Cross-module
optimizations must be requested with the
-ifo
option.
Specifying
-O3
in addition to
-ifo
improves the quality
of cross-module optimization.
In this case, compiling multiple files in one
operation allows the compiler to perform the maximum possible optimizations.
The
-ifo
option produces one
.o
file for
multiple source files.
2.5.2 Linking with the ld Command
Normally, you do not need to run the linker directly, but use
the
cc
command to indirectly invoke the
linker.
Executables that need to be built solely from assembler objects can
be built with the
ld
command.
The linker (ld) combines one or more object files
(in the order specified) into one executable program file, performing relocation,
external symbol resolutions, and all other processing required to make object
files ready for execution.
Unless you specify otherwise, the linker names
the executable program file
a.out.
You can execute the program file or use it as input
for another linker operation.
The
as
assembler does not automatically invoke the
linker.
To link a program written in assembly language, do either of the following:
Assemble and link with one of the other compiler commands.
The
.s
suffix of the assembly language source file automatically
causes the compiler command to invoke the assembler.
Assemble with the
as
command and then link
the resulting object file with the
ld
command.
For information about the options and libraries that affect the linking
process, see
ld(1).
2.5.3 Specifying Libraries
When you compile your program on the Tru64 UNIX
system, it is automatically linked with the C library,
libc.so.
If you
call routines that are not in
libc.so
or one of the archive
libraries associated with your compiler command, you must explicitly link
your program with the library.
Otherwise, your program will not be linked
correctly.
You need to explicitly specify libraries in the following situations:
When compiling multilanguage programs
If you compile multilanguage programs, be sure to explicitly request
any required run-time libraries to handle unresolved references.
Link the
libraries by specifying
-lstring,
where
string
is an abbreviation of the library
name.
For example, if you write a main program in C and some procedures in
another language, you must explicitly specify the library for that language
and the math library.
When you use these options, the linker replaces the
-l
with
lib
and appends the specified characters
(for the language library and for the math library) and the
.a
or
.so
suffix, depending upon whether it is a static (nonshared
archive library) or dynamic (call-shared object or shared library) library.
Then, it searches the following directories for the resulting library
name:
/usr/shlib
/usr/ccs/lib
/usr/lib/cmplrs/cc
/usr/lib
/usr/local/lib
/var/shlibFor a list of the libraries that each language uses, see the reference pages of the compiler drivers for the various languages.
When storing object files in an archive library
You must include the pathname of the library on the compiler or linker
command line.
For example, the following command specifies that the
libfft.a
archive library in the
/usr/jones
directory
is to be linked along with the math library:
%cc main.o more.o rest.o /usr/jones/libfft.a -lm
The linker searches libraries in the order that you specify. Therefore, if any file in your archive library uses data or procedures from the math library, you must specify the archive library before you specify the math library.
To run an executable program in your current
working directory, in most cases you enter its file name.
For example, to
run the program
a.out
located in your current directory,
enter:
%a.out
If the executable program is not in a directory in your path, enter the directory path before the file name, or enter:
%./a.out
When the program is invoked, the
main
function in
a C program can accept arguments from the command line if the
main
function is defined with one or more of the following optional
parameters:
int
main ( int
argc, char *argv[ ], char *envp[ ] )[...]
The
argc
parameter is the number of arguments
in the command line that invoked the program.
The
argv
parameter is an array of character strings containing the arguments.
The
envp
parameter is the environment array containing process information,
such as the user name and controlling terminal.
(The
envp
parameter has no bearing on passing command-line arguments.
Its primary use
is during
exec
and
getenv
function calls.)
You can access only the parameters that you define. For example, the following program defines the argc and argv parameters to echo the values of parameters passed to the program:
/*
* Filename: echo-args.c
* This program echoes command-line arguments.
*/
#include <stdio.h>
int main( int argc, char *argv[] )
{
int i;
printf( "program: %s\n", argv[0] ); /* argv[0] is program name */
for ( i=1; i < argc; i++ )
printf( "argument %d: %s\n", i, argv[i] );
return(0);
}
The program is compiled with the following command to produce
a program file called
a.out:
$cc echo-args.c
When the user invokes
a.out
and passes command-line
arguments, the program echoes those arguments on the terminal.
For example:
$a.out Long Day\'s "Journey into Night"program: a.out argument 1: Long argument 2: Day's argument 3: Journey into Night
The shell parses all arguments
before passing them to
a.out.
For this reason, a single
quote must be preceded by a backslash, alphabetic arguments are delimited
by spaces or tabs, and arguments with embedded spaces or tabs are enclosed
in quotation marks.
2.7 Object File Tools
After a source file has been compiled, you can examine the object file or executable file with following tools:
odump
-- Displays the contents of
an object file, including the symbol table and header information.
stdump
-- Displays symbol table information
from an object file.
nm
-- Displays only symbol table information.
file
-- Provides descriptive information
on the general properties of the specified file, for example, the programming
language used.
size
-- Displays the size of the text,
data, and bss segments.
dis
-- Disassembles object files into
machine instructions.
The following sections describe these tools.
In addition, see
strings(1)
for information on using the
strings
command to find the
printable strings in an object file or other binary file.
2.7.1 Dumping Selected Parts of Files (odump)
The
odump
tool displays header tables and other selected parts of an
object or archive file.
For example,
odump
displays the
following information about the file
echo-args.o:
%odump -at echo-args.o***ARCHIVE SYMBOL TABLE*** ***ARCHIVE HEADER*** Member Name Date Uid Gid Mode Size ***SYMBOL TABLE INFORMATION*** [Index] Name Value Sclass Symtype Ref echo-args.o: [0] main 0x0000000000000000 0x01 0x06 0xfffff [1] printf 0x0000000000000000 0x06 0x06 0xfffff [2] _fpdata 0x0000000000000000 0x06 0x01 0xfffff
For more information, see
odump(1).
2.7.2 Listing Symbol Table Information (nm)
The
nm
tool displays symbol table
information for object files.
For
example,
nm
displays the following information about the
object file produced for the executable file
a.out:
%nmnm: Warning: - using a.out Name Value Type Size .bss | 0000005368709568 | B | 0000000000000000 .data | 0000005368709120 | D | 0000000000000000 .lit4 | 0000005368709296 | G | 0000000000000000 .lit8 | 0000005368709296 | G | 0000000000000000 .rconst | 0000004831842144 | Q | 0000000000000000 .rdata | 0000005368709184 | R | 0000000000000000
.
.
.
The
Name
column contains the symbol or external name;
the
Value
column shows the address of the symbol, or debugging
information; the
Type
column contains a letter showing
the symbol type; and the
Size
column shows the symbol's
size (accurate only when the source file is compiled with the debugging option,
for example,
-g).
Some of the symbol type letters
are:
B
-- External zeroed data
D
-- External initialized data
G
-- External small initialized data
Q
-- Read-only constants
R
-- External read-only data
For more information, see
nm(1).
2.7.3 Determining a File's Type (file)
The
file
command reads input files,
tests each file to classify it by type, and writes the file's type to standard
output.
The
file
command uses the
/etc/magic
file to identify files that contain a magic number.
(A magic
number is a numeric or string constant
that indicates a file's type.)
The following example shows the output of the
file
command on a directory containing a C source file, object file, and executable
file:
%file *.*.: directory ..: directory a.out: COFF format alpha dynamically linked, demand paged executable or object module not stripped - version 3.11-8 echo-args.c: c program text echo-args.o: COFF format alpha executable or object module not stripped - version 3.12-6
For more information, see
file(1).
2.7.4 Determining a File's Segment Sizes (size)
The
size
tool displays information about the text, data, and bss segments
of the specified object or archive file or files in octal, hexadecimal, or
decimal format.
For example, when it is called without any arguments, the
size
command returns information on
a.out.
You
can also specify the name of an object or executable file on the command line.
For example:
%sizetext data bss dec hex 8192 8192 0 16384 4000%size echo-args.otext data bss dec hex 176 96 0 272 110
For more information, see
size(1).
2.7.5 Disassembling an Object File (dis)
The
dis
tool disassembles
object file modules into machine language.
For example, the
dis
command produces the following output when it disassembles the
a.out
program:
%dis a.out
.
.
.
_ _start: 0x120001080: 23defff0 lda sp, -16(sp) 0x120001084: b7fe0008 stq zero, 8(sp) 0x120001088: c0200000 br t0, 0x12000108c 0x12000108c: a21e0010 ldl a0, 16(sp) 0x120001090: 223e0018 lda a1, 24(sp)
.
.
.
For more information, see
dis(1).
2.8 ANSI Name Space Pollution Cleanup in the Standard C Library
The ANSI C standard states that users whose
programs link against
libc
are guaranteed a certain range
of global identifiers that can be used in their programs without danger of
conflict with, or pre-emption of, any global identifiers in
libc.
The ANSI C standard also reserves a range of global identifiers that
libc
can use in its internal implementation.
These are called reserved
identifiers and consist of the following, as defined in ANSI document number
X3.159-1989:
Any external identifier beginning with an underscore
Any external identifier beginning with an underscore followed by an uppercase letter or an underscore
ANSI conformant programs are not permitted to define global identifiers that either match the names of ANSI routines or fall into the reserved name space specified earlier in this section. All other global identifier names are available for use in user programs.
Historical
libc
implementations contain large numbers
of non-ANSI, nonreserved global identifiers that are both documented and supported.
These routines are often called from within
libc
by other
libc
routines, both ANSI and otherwise.
A user's program that defines
its own version of one of these non-ANSI, nonreserved items would pre-empt
the routine of the same name in
libc.
This could alter
the behavior of supported
libc
routines, both ANSI and
otherwise, even though the user's program may be ANSI-conformant.
This potential
conflict is known as ANSI name space pollution.
The implementation of
libc
on Tru64 UNIX includes
a large number of non-ANSI, nonreserved global identifiers that are both documented
and supported.
To protect against pre-emption of these global identifiers
within
libc
and to avoid pollution of the user's name space,
the vast majority of these identifiers have been renamed to the reserved name
space by prepending two underscores (_ _) to the identifier names.
To preserve external access to these items, weak identifiers have been added
using the original identifier names that correspond to their renamed reserved
counterparts.
Weak identifiers work much like symbolic links between files.
When the weak identifier is referenced, the strong counterpart is used instead.
User programs linked statically against
libc
may
have extra symbol table entries for weak identifiers.
Each of these identifiers
will have the same address as its reserved counterpart,
which will also be included in the symbol table.
For
example, if a statically linked program simply called the
tzset()
function from
libc, the symbol table would contain
two entries for this call, as follows:
#stdump -b a.out | grep tzset18. (file 9) (4831850384) tzset Proc Text symref 23 (weakext)39. (file 9) (4831850384) _ _tzset Proc Text symref 23
In this example,
tzset
is the weak identifier and
_ _tzset
is its strong counterpart.
The
_ _tzset
identifier is the routine that will actually do the work.
User programs linked as shared should not see such additions to the symbol table because the weak/strong identifier pairs remain in the shared library.
Existing user programs that reference non-ANSI, nonreserved identifiers
from
libc
do not need to be recompiled because of these
changes, with one exception: user programs that depended on pre-emption of
these identifiers in
libc
will no longer be able to pre-empt
them using the nonreserved names.
This kind of pre-emption is not ANSI-compliant
and is highly discouraged.
However, the ability to pre-empt these identifiers
still exists by using the new reserved names (those preceded by two underscores).
These changes apply to the dynamic and static versions of
libc:
/usr/shlib/libc.so
/usr/lib/libc.a
When debugging programs linked against
libc, references
to weak symbols resolve to their strong counterparts, as in the following
example:
%dbx a.outdbx version 3.11.4 Type 'help' for help. main: 4 tzset(dbx) stop in tzset[2] stop in _ _tzset(dbx)
When the weak symbol
tzset
in
libc
is referenced, the debugger responds with the strong counterpart
_ _tzset
instead because the strong counterpart actually
does the work.
The behavior of the
dbx
debugger is the
same as if
_ _tzset
were referenced directly.