The Tru64 UNIX operating system supports different file system options that have various performance features and functionality.
This chapter describes the following:
Gathering information about all types of file systems (Section 9.1)
Applying tuning guidelines that are applicable to all types of file systems (Section 9.2)
Managing Advanced File System (AdvFS) performance (Section 9.3)
Managing UNIX File System (UFS) performance (Section 9.4)
Managing Network File System (NFS) performance (Section 9.5)
9.1 Gathering File System Information
The following sections describe how to use tools to monitor general file system activity and describe some general file system tuning guidelines.
See
Section 6.3.4
for information about using
dbx
to check the Unified Buffer Cache (UBC).
9.1.1 Displaying File System Disk Space
The
df
command displays the disk
space used by a UFS file system or AdvFS fileset.
Because an AdvFS fileset
can use multiple volumes, the
df
command reflects disk
space usage somewhat differently than UFS.
For example:
#df /usr/var/spool/mqueueFilesystem 512-blocks Used Available Capacity Mounted on /dev/rz13e 2368726 882 2130970 1% /usr/var/spool/mqueue#df /usr/sdeFilesystem 512-blocks Used Available Capacity Mounted on flume_sde#sde 1048576 319642 709904 32% /usr/sde
See
df(1)
for more information.
9.1.2 Checking the namei Cache with the dbx Debugger
The namei cache is used by UNIX File System (UFS), Advanced File System (AdvFS), CD-ROM File System (CDFS), Memory File System (MFS), and Network File System (NFS) to store information about recently used file names, parent directory vnodes, and file vnodes. The number of vnodes determines the number of open files. The namei cache also stores vnode information for files that were referenced but not found. Having this information in the cache substantially reduces the amount of searching that is needed to perform pathname translations.
To check namei cache statistics, use the
dbx print
command and specify a processor number to examine the
nchstats
data structure.
Consider the following example:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)print processor_ptr[0].nchstatsstruct { ncs_goodhits = 47967479 ncs_neghits = 3611935 ncs_badhits = 1828974 ncs_falsehits = 58393 ncs_miss = 4194525 ncs_long = 60 ncs_badtimehits = 406034 ncs_collisions = 149 ncs_unequaldups = 0 ncs_pad = { [0] 0 [1] 0 [2] 0 } } (dbx)
Examine the
ncs_goodhits
(found a match),
ncs_neghits
(found a match that did not exist), and
ncs_miss
(did not find a match) fields to determine the hit rate.
The hit
rate should be above 80 percent (ncs_goodhits
plus
ncs_neghits
divided by the sum of the
ncs_goodhits,
ncs_neghits,
ncs_miss, and
ncs_falsehits
fields).
See
Section 9.2.1
for information
on how to improve the namei cache hit rate and lookup speeds.
If the value in the
ncs_badtimehits
field is more
than 0.1 percent of the
ncs_goodhits
field, then you may
want to delay vnode deallocation.
See
Section 9.2.2
for
more information.
9.2 Tuning File Systems
You may be able to improve I/O performance by modifying some kernel subsystem attributes that affect file system performance. General file system tuning often involves tuning the Virtual File System (VFS), which provides a uniform interface that allows common access to files, regardless of the file system on which the files reside.
To successfully improve file system performance, you must understand how your applications and users perform disk I/O, as described in Section 2.1. Because file systems share memory with processes, you should also understand virtual memory operation, as described in Chapter 6.
Table 9-1
describes the guidelines for general
file system tuning and lists the performance benefits as well as the tradeoffs.
There are also specific guidelines for AdvFS and UFS file systems.
See
Section 9.3
and
Section 9.4
for information.
Table 9-1: General File System Tuning Guidelines
| Guideline | Performance Benefit | Tradeoff |
| Increase the size of the namei cache (Section 9.2.1) | Improves namei cache lookup operations | Consumes memory |
| Delay vnode deallocation (Section 9.2.2) | Improves namei cache lookup operations | Consumes memory |
| Delay vnode recycling (Section 9.2.3) | Improves cache lookup operations | None |
| Increase the memory allocated to the UBC (Section 9.2.4) | Improves file system I/O performance | May cause excessive paging and swapping |
| Decrease the amount of memory borrowed by the UBC (Section 9.2.5) | Improves file system I/O performance | Decreases the memory available for processes, and may decrease system response time |
| Increase the minimum size of the UBC (Section 9.2.6) | Improves file system I/O performance | Decreases the memory available for processes |
| Increase the amount of UBC memory used to cache a large file (Section 9.2.7) | Improves large file performance | May allow a large file to consume all the pages on the free list |
| Disable flushing file read access times (Section 9.2.8) | Improves file system performance for systems that perform mainly read operations | Jeopardizes the integrity of read access time updates and violates POSIX standards |
| Use Prestoserve to cache only file system metadata (Section 9.2.9) | Improves performance for applications that access large amounts of file system metadata | Prestoserve is not supported in a cluster or for nonfile system I/O operations |
The following sections describe these guidelines in detail.
9.2.1 Increasing the Size of the namei Cache
The namei cache is used by UFS, AdvFS, CDFS, and NFS to store information about recently used file names, parent directory vnodes, and file vnodes. The number of vnodes determines the number of open files. The namei cache also stores vnode information for files that were referenced but not found. Having this information in the cache substantially reduces the amount of searching that is needed to perform pathname translations.
The
vfs
subsystem attribute
name_cache_size
specifies the maximum number of elements in the cache.
You can
also control the size of the namei cache with the
maxusers
attribute, as described in
Section 5.1.
Performance Benefit and Tradeoff
You may be able to make lookup operations faster by increasing the size of the namei cache. However, this increases the amount of wired memory.
Note that many benchmarks perform better with a large namei cache.
You cannot modify the
name_cache_size
attribute without
rebooting the system.
When to Tune
Monitor the namei cache by using the
dbx print
command
and specifying a processor number to examine the
nchstats
data structure.
If the miss rate (misses / (good + negative + misses)) is
more than 20 percent, you may want to increase the cache size.
See
Section 9.1.2
for more information.
Recommended Values
The default value of the
vfs
subsystem attribute
name_cache_size
is:
2 * (148 + 10 *
maxusers) * 11 / 10
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.2.2 Delaying vnode Deallocation
File systems use a kernel data structure called a vnode for each open file. The number of vnodes determines the number of open files. By default, Tru64 UNIX uses dynamic vnode allocation, which enables the supply of kernel vnodes to increase and decrease, according to the system demand.
You enable and disable dynamic vnode allocation by using the
vfs
subsystem attribute
vnode_deallocation_enable,
which is set to 1 (enabled), by default.
If you disable dynamic vnode allocation,
the operating system will use a static vnode pool.
For the best performance, Compaq
recommends that you use dynamic vnode allocation.
If you are using dynamic vnode allocation, a vnode is deallocated (removed
from the free list and its memory is returned to the system) when it has not
been accessed through the namei cache for more than the amount of time specified
by the
vfs
subsystem attribute
namei_cache_valid_time.
The default value is 1200 seconds.
Performance Benefit and Tradeoff
Increasing the default value of the
namei_cache_valid_time
attribute delays vnode deallocation, which may improve the cache
hit rate.
However, this will increase the amount of memory consumed by the
vnode pool.
You cannot modify the
namei_cache_valid_time
attribute
without rebooting the system.
When to Tune
The default value of the
namei_cache_valid_time
attribute
(1200 seconds) is appropriate for most workloads.
However, for workloads
with heavy vnode pool activity, you may be able to optimize performance by
modifying the default value.
You can obtain namei cache statistics for the number of cache lookup
failures due to vnode deallocation by examining the
ncs_badtimehits
field in the
dbx nchstats
data structure.
If
the value in the
ncs_badtimehits
field is more than 0.1
percent of the successful cache hits, as specified in the
ncs_goodhits
field, then you may want to increase the default value of the
namei_cache_valid_time
attribute.
See
Section 9.1.2
for more information about monitoring the namei cache.
Recommended Values
To delay the deallocation of vnodes, increase the value of the
vfs
subsystem attribute
namei_cache_valid_time.
The default value is 1200.
Note
Decreasing the value of the
namei_cache_valid_timeattribute accelerates the deallocation of vnodes from the namei cache and reduces the efficiency of the cache.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.2.3 Delaying vnode Recycling
File systems use a kernel data structure called a vnode for each open file. The number of vnodes determines the number of open files. By default, Tru64 UNIX uses dynamic vnode allocation, which enables the supply of kernel vnodes to increase and decrease, according to the system demand.
You enable and disable dynamic vnode allocation by using the
vfs
subsystem attribute
vnode_deallocation_enable,
which is set to 1 (enabled), by default.
If you disable dynamic vnode allocation,
the operating system will use a static vnode pool.
For the best performance, Compaq
recommends that you use dynamic vnode allocation.
Using dynamic vnode allocation, a vnode can be recycled and used to
represent a different file object when it has been on the vnode free list
for more than the amount of time specified by the
vfs
subsystem
attribute
vnode_age.
The default value is 120 seconds.
Performance Benefit and Tradeoff
Increasing the value of the
vnode_age
attribute delays
vnode recycling and increases the chance of a cache hit.
However, delaying
vnode recycling increases the length of the free list and the amount of memory
consumed by the vnode pool.
You can modify the
vnode_age
attribute without rebooting
the system.
When to Tune
The default value of the
vnode_age
attribute is appropriate
for most workloads.
However, for workloads with heavy vnode pool activity,
you may be able to optimize performance by modifying the default value.
Recommended Values
To delay the recycling of vnodes, increase the default value of the
vnode_age
attribute.
The default value is 120 seconds.
Decreasing the value of the
vnode_age
attribute accelerates
vnode recycling, but decreases the chance of a cache hit.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.2.4 Increasing Memory for the UBC
The Unified Buffer Cache (UBC) shares with processes the memory that is not wired. The UBC caches UFS and CDFS file system data for reads and writes, AdvFS metadata and file data, and MFS data. Performance is improved if the cached data is later reused and a disk operation is avoided.
The
vm
subsystem attribute
ubc_maxpercent
specifies the maximum amount of nonwired memory that can be allocated
to the UBC.
See
Section 6.1.2.2
for information about UBC
memory allocation.
Performance Benefit and Tradeoff
If you reuse data, increasing the size of the UBC will improve the chance that data will be found in the cache. An insufficient amount of memory allocated to the UBC can impair file system performance. However, the performance of an application that generates a lot of random I/O will not be improved by a large UBC, because the next access location for random I/O cannot be predetermined.
Be sure that allocating more memory to the UBC does not cause excessive paging and swapping.
You can modify the
ubc_maxpercent
attribute without
rebooting the system.
When to Tune
For most configurations, use the default value of the
ubc_maxpercent
attribute (100 percent).
Recommended Values
To increase the maximum amount of memory allocated to the UBC, you can
increase the value of the
vm
subsystem attribute
ubc_maxpercent.
The default value is 100 percent, which should be
appropriate for most configurations, including Internet servers.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.2.5 Increasing the Borrowed Memory Threshold
The UBC borrows all
physical memory between the value of the
vm
subsystem attribute
ubc_borrowpercent
and the value of the
ubc_maxpercent
attribute.
See
Section 6.1.2.2
for more information about
allocating memory to the UBC.
Performance Benefit and Tradeoff
Increasing the value of the
ubc_borrowpercent
attribute
will reduce the amount of memory that the UBC borrows from processes and
allow more memory to remain in the UBC when page reclamation begins.
This
can increase the UBC cache effectiveness, but it may degrade system response
time when a low-memory condition occurs (for example, a large process working
set).
You can modify the
ubc_borrowpercent
attribute without
rebooting the system.
When to Tune
If
vmstat
output shows excessive paging but few or
no page outs, you may want to increase the borrowing threshold.
Recommended Values
The value of the
ubc_borrowpercent
attribute can
range from 0 to 100.
The default value is 20 percent.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.2.6 Increasing the Minimum Size of the UBC
The minimum amount of memory that can be allocated
to the UBC is specified by the
vm
subsystem attribute
ubc_minpercent.
See
Section 6.1.2.2
for information
about allocating memory to the UBC.
Performance Benefit and Tradeoff
Increasing the minimum size of the UBC will prevent large programs from completely consuming the memory that can be used by the UBC.
Because the UBC and processes share virtual memory, increasing the minimum size of the UBC may cause the system to page.
You can modify the
ubc_minpercent
attribute without
rebooting the system.
When to Tune
For I/O servers, you may want to raise the value of the
vm
subsystem attribute
ubc_minpercent
to ensure
that enough memory is available for the UBC.
To ensure that the value of the
ubc_minpercent
is
appropriate, use the
vmstat
command to examine the page-out
rate.
See
Section 6.3.1
for information.
Recommended Values
The default value of the
ubc_minpercent
is 10 percent.
If the values of the
vm
subsystem attributes
ubc_maxpercent
and
ubc_minpercent
are close together,
you may degrade I/O performance.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.2.7 Improving Large File Caching Performance
If a large file completely
fills the UBC, it may take all of the pages on the free page list, which may
cause the system to page excessively.
The
vm
subsystem
attribute
vm_ubcseqpercent
specifies the maximum amount
of memory allocated to the UBC that can be used to cache a single file.
The
vm
subsystem attribute
vm_ubcseqstartpercent
specifies the size of the UBC as a percentage of physical memory,
at which time the virtual memory subsystem starts stealing the UBC LRU pages
for a file to satisfy the demand for pages.
Performance Benefit and Tradeoff
Increasing the value of the
vm_ubcseqpercent
attribute
will improve the I/O performance of a large single file, but will decrease
the memory available for small files.
You can modify the
vm_ubcseqpercent
and
vm_ubcseqstartpercent
attributes without rebooting the system.
When to Tune
You may want to increase the value of the
vm_ubcseqpercent
attribute if you reuse large files.
Recommended Values
The default value of the
vm_ubcseqpercent
attribute
is 10 percent of memory allocated to the UBC.
To force the system to reuse the pages in the UBC instead of taking pages from the free list, perform the following tasks:
Make the maximum size of the UBC greater than the size of
the UBC as a percentage of memory.
That is, the value of the
vm
subsystem attribute
ubc_maxpercent
(the default is 100
percent) must be greater than the value of the
vm_ubcseqstartpercent
attribute (the default is 50 percent).
Make the value of the
vm_ubcseqpercent
attribute, which specifies the size of a file as a percentage of the UBC,
greater than a referenced file.
The default value of the
vm_ubcseqpercent
attribute is 10 percent.
For example, using the default values, the UBC would have to be larger than 50 percent of all memory and a file would have to be larger than 10 percent of the UBC (that is, the file size would have to be at least 5 percent of all memory) in order for the system to reuse the pages in the UBC.
On large-memory systems that are doing a lot of file system operations,
you may want to decrease the value of the
vm_ubcseqstartpercent
attribute to 30 percent.
Do not specify a lower value unless you decrease
the size of the UBC.
In this case, do not change the value of the
vm_ubcseqpercent
attribute.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.2.8 Disabling File Read Access Time Flushing
When
a
read
system call is made to a file system's files, the
default behavior is for the file system to update both the in-memory file
access time and the on-disk
stat
structure, which contains
most of the file information that is returned by the
stat
system call.
Performance Benefit and Tradeoff
You can improve file system performance for systems that perform mainly read operations (such as proxy servers) by specifying, at mount time, that the file system update only the in-memory file access time when a read system call is made to a file. The file system will update the on-disk stat structure only if the file is modified.
Updating only the in-memory file access time for reads can improve proxy server response time by decreasing the number of disk I/O operations. However, this behavior jeopardizes the integrity of read access time updates and violates POSIX standards. Do not use this functionality if it will affect utilities that use read access times to perform tasks, such as migrating files to different devices.
When to Perform this Task
You may want to disable file read access time flushing if your system performs mainly read operations.
Recommended Procedure
To disable file read access time flushing, use the
mount
command with the
noatimes
option.
See
read(2)
and
mount(8)
for more information.
9.2.9 Caching Only File System Metadata with Prestoserve
Prestoserve can improve
the overall run-time performance for systems that perform large numbers of
synchronous writes.
The
prmetaonly
attribute controls whether
Prestoserve caches only UFS and AdvFS file system metadata, instead of both
metadata and synchronous write data (the default).
Performance Benefit and Tradeoff
Caching only metadata may improve the performance of applications that access many small files or applications that access a large amount of file-system metadata but do not reread recently written data.
When to Tune
Cache only file system metadata if your applications access many small files or access a large amount of file-system metadata but do not reread recently written data.
Recommended Values
Set the value of the
prmetaonly
attribute to 1 (enabled)
to cache only file system metadata.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.3 Managing Advanced File System Performance
The Advanced File System (AdvFS) provides file system features beyond those of a traditional UFS file system. Unlike the rigid UFS model in which the file system directory hierarchy (tree) is bound tightly to the physical storage, AdvFS consists of two distinct layers: the directory hierarchy layer and the physical storage layer.
The following sections describe:
AdvFS features (Section 9.3.1)
AdvFS I/O queues (Section 9.3.2)
AdvFS access structures (Section 9.3.3)
AdvFS guidelines for high-performance configurations (Section 9.3.4)
Monitoring AdvFS performance (Section 9.3.5)
Tuning AdvFS (Section 9.3.6)
Improving AdvFS performance (Section 9.3.7)
See the
AdvFS Administration
manual for detailed
information about setting up and managing AdvFS.
9.3.1 AdvFS Features
The AdvFS decoupled file system structure enables you to manage the physical storage layer apart from the directory hierarchy layer. You can put multiple volumes (disks, LSM volumes, or RAID storage sets) in a file domain and distribute the filesets and files across the volumes. A file's blocks usually reside together on the same volume, unless the file is striped or the volume is full. Each new file is placed on the successive volume by using round-robin scheduling.
AdvFS enables you to move files between a defined group of disk volumes without changing file pathnames. Because the pathnames remain the same, the action is completely transparent to users.
The AdvFS Utilities product, which is licensed separately from the operating system, extends the capabilities of the AdvFS file system.
AdvFS provides the following basic features that do not require a license:
High-performance file system
AdvFS uses an extent-based file allocation scheme that consolidates data transfers, which increases sequential bandwidth and improves performance for large data transfers. AdvFS performs large reads from disk when it anticipates a need for sequential data. AdvFS also performs large writes by combining adjacent data into a single data transfer.
Fast file system recovery
Rebooting after a system interruption is extremely fast, because AdvFS
uses write-ahead logging, instead of the
fsck
utility,
as a way to check for and repair file system inconsistencies.
The recovery
speed depends on the number of uncommitted records in the log, not the amount
of data in the fileset; therefore, reboots are quick and predictable.
Direct I/O support
AdvFS allows you to enable direct I/O functionality on the files in a fileset or on a specific file. If direct I/O is enabled, file data is synchronously read or written without copying the data into the AdvFS buffer cache. Direct I/O can significantly improve disk I/O throughput for applications that read or write data only once or do not frequently write to previously written pages. See Section 9.3.4.7 for more information.
Smooth sync
Smooth sync functionality improves AdvFS asynchronous I/O performance
by preventing I/O spikes caused by the
update
daemon, increasing
the chance of a buffer cache hit, and improving the consolidation of I/O requests.
See
Section 9.3.6.5
for more information.
Online file domain defragmentation capability
Defragmenting disk data can improve performance by making data more contiguous. AdvFS enables you to perform this task without interrupting data availability.
Disk quotas
AdvFS enables you to track and control the amount of disk storage that each user, group, and fileset consumes.
The optional AdvFS utilities product, which requires a license, provides the following features:
Disk spanning
A file or fileset can span disks within a multi-volume file domain.
Online file system resizing
You can dynamically change the size of a file system by adding or removing disks. AdvFS enables you to perform this task without disrupting users or applications.
Ability to recover deleted files
Users can retrieve their own unintentionally deleted files from predefined trashcan directories, without assistance from system administrators.
I/O load balancing across disks
You can distribute the percentage of used space evenly between volumes in a multi-volume domain.
Online file migration across disks
You can move specific files to different volumes to eliminate bottlenecks caused by heavily used files.
Online backup
You can back up file system contents with limited interruption to users.
Clone filesets
AdvFS enables you to clone a fileset, which produces a read-only snapshot of fileset data structures. Cloning can increase the availability of data by preserving the state of the AdvFS data at a particular time and protecting against accidental file deletion or corruption.
File-level striping
File-level striping may improve I/O bandwidth (transfer rates) by distributing file data across multiple disk volumes.
Graphical user interface
The AdvFS GUI simplifies disk and file system administration, provides status, and alerts you to potential problems.
See the
AdvFS Administration
manual for detailed
information about AdvFS features.
9.3.2 AdvFS I/O Queues
The AdvFS buffer cache is part of the UBC, and acts as a layer between the operating system and disk by storing recently accessed AdvFS file system data. Performance is improved if the cached data is later reused (a buffer cache hit) and a disk operation is avoided.
At boot time, the kernel determines the amount of physical memory that is available for AdvFS buffer cache headers, and allocates a buffer cache header for each possible page. The size of an AdvFS page is 8 KB.
The number of AdvFS buffer cache headers depends on the number of 8-KB
pages that can be obtained from the amount of memory specified by the
advfs
subsystem attribute
AdvfsCacheMaxPercent.
The default value is 7 percent of physical memory.
See
Section 6.1.2.3
for more information about how the system allocates memory to the AdvFS buffer
cache.
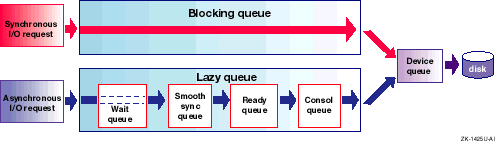
For each AdvFS volume, I/O requests are sent to one of the following queues, which feed I/O requests to the device queue:
Blocking queue
The blocking queue caches synchronous I/O requests. A synchronous I/O request is a read operation or a write that must be flushed to disk before it is considered complete and the application can continue. This ensures data reliability because the data has been written to disk and is not stored only in memory. Therefore, I/O requests on the blocking queue cannot be asynchronously removed, because the I/O must complete.
Lazy queue
The lazy queue caches asynchronous I/O requests. Asynchronous I/O requests are cached in the lazy queue and periodically flushed to disk in portions that are large enough to allow the disk drivers to optimize the order of the write.
Figure 9-1
shows the movement of synchronous
and asynchronous I/O requests through the AdvFS I/O queues.
Figure 9-1: AdvFS I/O Queues
When an asynchronous I/O request enters the lazy queue, it is assigned a time stamp. The lazy queue is a pipeline that contains a sequence of queues through which an I/O request passes: the wait queue (if applicable), the smooth sync queue, the ready queue, and the consol (consolidation) queue. An AdvFS buffer cache hit can occur while an I/O request is in any part of the lazy queue.
Detailed descriptions of the AdvFS queues are as follows:
Wait queue--Asynchronous I/O requests that are waiting for an AdvFS transaction log write to complete first enter the wait queue. Each file domain has a transaction log that tracks fileset activity for all filesets in the file domain, and ensures AdvFS metadata consistency if a crash occurs.
AdvFS uses write-ahead logging, which requires that when metadata is modified, the transaction log write must complete before the actual metadata is written. This ensures that AdvFS can always use the transaction log to create a consistent view of the file system metadata. After the transaction log is written, I/O requests can be moved from the wait queue to the smooth sync queue.
Smooth sync queue--The smooth sync queue improves AdvFS asynchronous
I/O performance by preventing I/O spikes caused by the
update
daemon, increasing the chance of an AdvFS buffer cache hit, and improving
the consolidation of I/O requests.
When smooth sync is not enabled, the
update
daemon
flushes data from memory to disk every 30 seconds, regardless of how long
a buffer has been cached.
However, with smooth sync enabled (the default behavior),
asynchronous I/O requests remain in the smooth sync queue for the amount of
time specified by the value of the
vfs
attribute
smoothsync_age
(the default is 30 seconds).
After this time,
the buffer moves to the ready queue.
The movement of buffers from the smooth
sync queue to the ready queue occurs continuously, based on the age of the
buffer, and reduces the need to flush large numbers of requests every 30 seconds.
See
Section 9.3.6.5
for information about tuning the smooth sync
queue.
Ready queue--Asynchronous I/O requests that are
not waiting for an AdvFS transaction log write to complete enter the ready
queue, where they are sorted and held until the size of the ready queue reaches
the value specified by the
AdvfsReadyQLim
attribute, or
until the
update
daemon flushes the data.
The default value
of the
AdvfsReadyQLim
attribute is 16,384 512-byte blocks
(8 MB).
You can modify the size of the ready queue for all AdvFS volumes by
changing the value of the
AdvfsReadyQLim
attribute.
Alternatively,
you can modify the ready queue limit for a specific AdvFS volume by using
the
chvol -t
command.
See
Section 9.3.6.4
for
information about tuning the ready queue.
Consol queue--I/O requests are moved from the ready queue to the consol queue, which feeds the device queue. The consol queue serves as a holding area that enables the interleaving of I/O requests as they move from the blocking and the consol queues to the device queue, and also prevents flooding the device queue with requests.
Both the consol queue and the blocking queue feed the device queue, where logically contiguous I/O requests are consolidated into larger I/Os before they are sent to the device driver. The size of the device queue affects the amount of time it takes to complete a synchronous (blocking) I/O operation. AdvFS issues several types of blocking I/O operations, including AdvFS metadata and log data operations.
The
AdvfsMaxDevQLen
attribute limits the total number
of I/O requests on the AdvFS device queue.
The default value is 24 requests.
When the number of requests exceeds this value, only synchronous requests
from the blocking queue are accepted onto the device queue.
Although the default value of the
AdvfsMaxDevQLen
attribute is appropriate for most configurations, you may need to modify this
value.
However, increase the default value only if devices are not being kept
busy.
Make sure that increasing the size of the device queue does not cause
a decrease in response time.
See
Section 9.3.6.6
for more information
about tuning the AdvFS device queue.
Use the
advfsstat
command to show the AdvFS queue
statistics.
See
Section 9.3.5.1
for information.
9.3.3 AdvFS Access Structures
AdvFS access structures are in-memory data structures that AdvFS uses to cache low-level information about files that are currently open and files that were opened but are now closed. Caching open file information can enhance AdvFS performance if the open files are later reused. If your users or applications open and then reuse many files, you may be able to improve AdvFS performance by modifying how the system allocates AdvFS access structures.
There are three attributes that control the allocation of AdvFS access structures:
The
AdvfsAccessMaxPercent
attribute controls
the maximum percentage of pageable memory that can be allocated for AdvFS
access structures.
At boot time, the system reserves for AdvFS access structures
a portion of the physical memory that is not wired.
The memory reserved is
either twice the value of the
AdvfsMinFreeAccess
attribute
or the value of the
AdvfsAccessMaxPercent
attribute, whichever
is smaller.
These access structures are then placed on the access structure
free list.
As AdvFS files are opened, access structures are taken from the free
list.
If the number of access structures on the free list falls below the
value of the
AdvfsMinFreeAccess
attribute, AdvFS allocates
additional access structures and places them on the free list, until the number
of access structures on the free list is twice the value of the
AdvfsMinFreeAccess
attribute or the value of the
AdvfsAccessMaxPercent
attribute, whichever is smaller.
At any one time, the access structure free list contains only
a portion of the access structures that the system has allocated.
The
AdvfsMaxFreeAccessPercent
attribute specifies the maximum percentage
of the total allocated access structures that can be on the free list at one
time.
Access structures are deallocated from the free list, and memory is
returned to the pool that is reserved for access structures when the following
occurs:
The number of access structures on the free list exceeds the
value of the
AdvfsMaxFreeAccessPercent
attribute (as a
percentage of the total allocated access structures).
For example, this condition
is satisfied if the value of the
AdvfsMaxFreeAccessPercent
attribute is 80 percent, there are 100 allocated access structures, and the
number of access structures on the free list is more then 80.
The number of access structures on the free list is more than
twice the value of the
AdvfsMinFreeAccess
attribute.
You may be able to improve AdvFS performance by modifying the previous attributes and allocating more memory for AdvFS access structures. However, this will reduce the amount of memory available to processes and may cause excessive paging and swapping. See Section 9.3.6.3 for information.
If you do not use AdvFS or if your workload does not frequently write
to previously-written pages, do not allocate a large amount of memory for
access structures.
If you have a large-memory system, you may want to decrease
the amount of memory reserved for AdvFS access structures.
See
Section 6.4.5
for information.
9.3.4 AdvFS Configuration Guidelines
You will obtain the best performance
if you carefully plan your AdvFS configuration.
Table 9-2
lists AdvFS configuration guidelines and performance benefits as well as tradeoffs.
See the
AdvFS Administration
manual for detailed
information about AdvFS configuration.
Table 9-2: AdvFS Configuration Guidelines
| Guideline | Performance Benefit | Tradeoff |
| Use a few file domains instead of a single large domain (Section 9.3.4.1) | Facilitates administration | None |
| Use a multi-volume file domains, instead of single-volume domains (Section 9.3.4.1) | Improves throughput | Multi-volumes increase the chance of domain failure |
| Configure one fileset for each domain (Section 9.3.4.2) | Facilitates administration | None |
| Keep filesets less than 50 GB in size (Section 9.3.4.2) | Facilitates administration | None |
| Distribute the I/O load over multiple disks (Section 9.3.4.3) | Improves throughput | Requires multiple disks |
| Place the transaction log on fast or uncongested volume (Section 9.3.4.4) | Prevents the log from becoming a bottleneck | None |
| Log only file structures (Section 9.3.4.4) | Maintains high performance | Increases the possibility of inconsistent data after a crash |
| Force all AdvFS file writes to be synchronous (Section 9.3.4.5) | Ensures that data is successfully written to disk | May degrade file system performance |
| Prevent partial writes (Section 9.3.4.6) | Ensures that system crashes do not cause partial disk writes | May degrade asynchronous write performance |
| Enable direct I/O (Section 9.3.4.7) | Improves disk I/O throughput for database applications that read or write data only once | Degrades I/O performance for applications that repeatedly access the same data |
| Use AdvFS for the root file system (Section 9.3.4.8) | Provides fast startup after a crash | None |
| Stripe files across different disks and, if possible, different buses (Section 9.3.4.9) | Improves sequential read and write performance | Increases chance of domain failure |
| Use quotas (Section 9.3.4.10) | Tracks and controls the amount of disk storage that each user, group, or fileset consumes | None |
| Consolidate I/O transfers (Section 9.3.4.11) | Improves AdvFS performance | None |
| Allocate sufficient swap space (Section 2.3.2.3) | Facilitates the use of the
verify
command |
Requires additional disk space |
The following sections describe these AdvFS configuration guidelines
in detail.
9.3.4.1 Configuring File Domains
To facilitate AdvFS administration and improve performance, configure a few file domains with multiple volumes instead of many file domains or a single large file domain. Using a few file domains with multiple volumes provides better control over physical resources, improves a fileset's total throughput, and decreases the administration time.
Each file domain uses a transaction log on one of the volumes. If you configure only a single large multi-volume file domain, the log may become a bottleneck. In contrast, if you configure many file domains, you spread the overhead associated with managing the logs for the file domains.
Multi-volume file domains improve performance because AdvFS generates parallel streams of output using multiple device consolidation queues. A file domain with three volumes on different disks is more efficient than a file domain consisting of a single disk because the latter has only one I/O path.
However, a single volume failure within a file domain will render the entire domain inaccessible, so the more volumes that you have in a file domain, the greater the risk that the domain will fail. To reduce the risk of file domain failure, limit the number of volumes in a file domain to eight or mirror the file domain with LSM or hardware RAID.
In addition, follow these guidelines for configuring file domains:
For the best efficiency, spread a file domain across several of the same type of disks with the same speed.
Use an entire disk in a file domain.
For example, do not use
partition
a
in one file domain and partition
b
in another file domain.
Use a single disk partition to add a disk to a file domain
(for example, partition
c), instead of using multiple partitions.
Make sure that busy files are not located on the same volume.
Use the
migrate
command to move files across volumes.
If you are using LSM, use multiple, small LSM volumes in a file domain, instead of a single, large concatenated or striped volume. This enables AdvFS to balance I/O across volumes.
9.3.4.2 Configuring Filesets for High Performance
Configuring many filesets in a file domain can adversely affect performance and AdvFS administration. If possible, configure only one fileset for each file domain.
In addition, the recommended maximum size of a fileset is 50 GB. Once a fileset reaches 30 GB, consider creating another file domain and fileset. You may want to establish a monitoring routine that alerts you to a large fileset size.
Use the
showfsets
command to display the number of
filesets in a domain and the size of a fileset.
See
showfsets(8)
for more
information.
9.3.4.3 Distribute the AdvFS I/O Load
Distribute the AdvFS I/O load over multiple disks to improve throughput. Use multiple file domains and spread filesets across the domains.
The number of filesets depends on your storage needs. Each fileset can be managed and backed up independently, and can be assigned quotas. Be sure that heavily used filesets are located on different file domains, so that a single transaction log does not become a bottleneck.
See
Section 8.1
for more information about distributing
the disk I/O load.
9.3.4.4 Improving the Transaction Log Performance
Each file domain has a transaction log that tracks fileset activity for all filesets in the file domain, and ensures AdvFS metadata consistency if a crash occurs. The AdvFS file domain transaction log may become a bottleneck if the log resides on a congested disk or bus, or if the file domain contains many filesets.
To prevent the log from becoming a bottleneck, put the log on a fast, uncongested volume. You may want to put the log on a disk that contains only the log. See Section 9.3.7.3 for information on moving an existing transaction log.
To make the transaction log highly available, use LSM or hardware RAID to mirror the log.
You can also divide a large multi-volume file domain into smaller file domains to distribute transaction log I/O.
By default, AdvFS logs only file structures.
However, you can also log
file data to ensure that a file is internally consistent if a crash occurs.
However, data logging can degrade performance.
See
Section 9.3.4.6
for information about atomic write data logging.
9.3.4.5 Forcing Synchronous Writes
By default, asynchronous
write requests are cached in the AdvFS buffer cache, and the
write
system call then returns a success value.
The data is written to
disk at a later time (asynchronously).
Use the
chfile -l on
command to force all write requests
to a specified AdvFS file to be synchronous.
If you enable forced synchronous
writes on a file, data must be successfully written to disk before the
write
system call will return a success value.
This behavior is
similar to the behavior associated with a file that has been opened with the
O_SYNC
option; however, forcing synchronous writes persists across
open
calls.
Forcing all writes to a file to be synchronous ensures that the write
has completed when the
write
system call returns a success
value.
However, it may degrade write performance.
A file cannot have both forced synchronous writes enabled and atomic write data logging enabled. See Section 9.3.4.6 for more information.
Use the
chfile
command to determine whether forced
synchronous writes or atomic write data logging is enabled.
Use the
chfile -l off
command to disable forced synchronous writes (the
default).
9.3.4.6 Preventing Partial Data Writes
AdvFS writes data to disk in 8-KB chunks. By default, and in accordance with POSIX standards, AdvFS does not guarantee that all or part of the data will actually be written to disk if a crash occurs during or immediately after the write. For example, if the system crashes during a write that consists of two 8-KB chunks of data, only a portion (anywhere from 0 to 16 KB) of the total write may have succeeded. This can result in partial data writes and inconsistent data.
To prevent partial writes if a system crash occurs, use the
chfile -L on
command to enable atomic write data logging for a specified
file.
By default, each file domain has a transaction log file that tracks fileset activity and ensures that AdvFS can maintain a consistent view of the file system metadata if a crash occurs. If you enable atomic write data logging on a file, data from a write call will be written to the transaction log file before it is written to disk. If a system crash occurs during or immediately after the write call, upon recovery, the data in the log file can be used to reconstruct the write. This guarantees that each 8-KB chunk of a write either is completely written to disk or is not written to disk.
For example, if atomic write data logging is enabled and a crash occurs during a write that consists of two 8-KB chunks of data, the write can have three possible states: none of the data is written, 8 KB of the data is written, or 16 KB of data is written.
Atomic write data logging may degrade AdvFS write performance because
of the extra write to the transaction log file.
In addition, a file that has
atomic write data logging enabled cannot be memory mapped by using the
mmap
system call, and it cannot have direct I/O enabled (see
Section 9.3.4.7).
A file cannot have both forced synchronous writes enabled (see
Section 9.3.4.5) and atomic write data logging enabled.
However,
you can enable atomic write data logging on a file and also open the file
with an
O_SYNC
option.
This ensures that the write is synchronous,
but also prevents partial writes if a crash occurs before the
write
system call returns.
Use the
chfile
command to determine if forced synchronous
writes or atomic write data logging is enabled.
Use the
chfile -L
off
command to disable atomic write data logging (the default).
To enable atomic write data logging on AdvFS files that are NFS mounted,
the NFS property list daemon,
proplistd, must be running
on the NFS client and the fileset must be mounted on the client by using the
mount
command's
proplist
option.
If atomic write data logging is enabled and you are writing to a file that has been NFS mounted, the offset into the file must be on an 8-KB page boundary, because NFS performs I/O on 8-KB page boundaries.
You can also activate and deactivate atomic data logging by using the
fcntl
system call.
In addition, both the
chfile
command and
fcntl
can be used on an NFS client to activate
or deactivate this feature on a file that resides on the NFS server.
9.3.4.7 Enabling Direct I/O
You can use direct I/O to read and write data from a file without copying the data into the AdvFS buffer cache. If you enable direct I/O, read and write requests are executed to and from disk through direct memory access, bypassing the AdvFS buffer cache.
Direct I/O can significantly improve disk I/O throughput for database applications that read or write data only once (or for applications that do not frequently write to previously written pages). However, direct I/O can degrade disk I/O performance for applications that access data multiple times, because data is not cached. As soon as you specify direct I/O, any data already in the buffer cache is automatically flushed to disk.
If you enable direct I/O, by default, reads and writes to a file will
be done synchronously.
However, you can use the asynchronous I/O (AIO) functions
(aio_read
and
aio_write) to enable an
application to achieve an asynchronous-like behavior by issuing one or more
synchronous direct I/O requests without waiting for their completion.
See
the
Programmer's Guide
for more information.
Although direct I/O will handle I/O requests of any byte size, the best performance will occur when the requested byte size is aligned on file page boundaries and is evenly divisible into 8-KB pages. Direct transfer from the user buffer to the disk is optimized in this case.
To enable direct I/O for a specific file, use the
open
system call and set the
O_DIRECTIO
file access flag.
Once a file is opened for direct I/O, this mode is in effect until all users
close the file.
Note that you cannot enable direct I/O for a file if it is already opened
for data-logging or if it is memory mapped.
Use the
fcntl
system call with the
F_GETCACHEPOLICY
argument to determine
if an open file has direct I/O enabled.
See
fcntl(2),
open(2),
AdvFS Administration,
and the
Programmer's Guide
for more information.
9.3.4.8 Configuring an AdvFS root File system
There are several advantages to configuring an AdvFS root file system:
Quick restart after a crash, because you do not run the
fsck
utility after a crash.
One set of tools to manage all local file systems.
All features
of AdvFS except
addvol
and
rmvol
are
available to manage the root file system.
Use AdvFS with LSM to mirror the root file system. This allows your root file system to remain viable even if there is a disk failure.
You can configure an AdvFS root file system during the initial base-system
installation, or you can convert your existing root file system after installation.
See the
AdvFS Administration
manual for more information.
9.3.4.9 Striping Files
You may be able to use the AdvFS
stripe
utility
to improve the sequential read and write performance of an individual file
by spreading file data evenly across different disks in a file domain.
For
the maximum performance benefit, stripe files across disks on different I/O
buses.
Striping files, instead of striping entire disks with RAID 0, is useful if an application continually accesses only a few specific files. Do not stripe both a file and the disk on which it resides. For information about striping entire disks, see Chapter 8.
The
stripe
utility distributes a zero-length file
(a file with no data written to it yet) evenly across a specified number of
volumes.
As data is appended to the file, the data is spread across the volumes.
The size of each data segment (also called the stripe or chunk size) is fixed
at 64 KB (65,536 bytes).
AdvFS alternates the placement of the segments on
the disks in a sequential pattern.
For example, the first 64 KB of the file
is written to the first volume, the second 64 KB is written to the next volume,
and so on.
If an application's I/O transfer read or write size is more than 64 KB, striping files may improve application performance by enabling parallel I/O operations on multiple controllers or volumes, because AdvFS file striping uses a fixed 64 KB stripe width.
Note
Distributing data across multiple volumes decreases data availability, because one volume failure makes the entire file domain unavailable. To make striped files highly available, you can use RAID 1 to mirror the disks across which the file is striped. For information about mirroring, see Chapter 8.
See
stripe(8)
for more information.
9.3.4.10 Using AdvFS Quotas
AdvFS quotas allow you to track and control the amount of physical storage that a user, group, or fileset consumes. In addition, AdvFS quota information is always maintained, but quota enforcement can be activated and deactivated.
You can set quota values on the amount of disk storage and on the number of files. Quotas that apply to users and groups are similar to UFS quotas. You can set a separate quota for each user or each group of users for each fileset.
In addition, you can restrict the space that a fileset itself can use. Fileset quotas are useful when a file domain contains multiple filesets. Without fileset quotas, any fileset can consume all of the disk space in the file domain.
All quotas can have two types of limits: hard and soft. A hard limit cannot be exceeded; space cannot be allocated and files cannot be created. A soft limit permits a period of time during which the limit can be exceeded as long as the hard limit has not been exceeded.
For information about AdvFS quotas, see the
AdvFS Administration
manual.
9.3.4.11 Consolidating I/O Transfers
By default, AdvFS
consolidates a number of I/O transfers into a single, large I/O transfer,
which can improve AdvFS performance.
To enable the consolidation of I/O transfers,
use the
chvol
command with the
-c on
option.
It is recommended that you not disable the consolidation of I/O transfers.
See
chvol(8)
for more information.
9.3.5 Gathering AdvFS Information
Table 9-3
describes the tools you can use to obtain information about AdvFS.
Table 9-3: AdvFS Monitoring Tools
| Name | Use | Description |
Displays AdvFS performance statistics (Section 9.3.5.1) |
Allows you to obtain extensive AdvFS performance information, including buffer cache, fileset, volume, and bitfile metadata table (BMT) statistics, for a specific interval of time. |
|
|
Identifies disks in a file domain (Section 9.3.5.2) |
Locates pieces of AdvFS file domains on disk partitions and in LSM disk groups. |
|
Displays detailed information about AdvFS file domains and volumes (Section 9.3.5.3) |
Allows you to determine if file data
is evenly distributed across AdvFS volumes.
The
For multivolume domains, the utility also displays the total volume size, the total number of free blocks, and the total percentage of volume space currently allocated. |
Displays information about files in an AdvFS fileset (Section 9.3.5.4) |
Displays detailed information about
files (and directories) in an AdvFS fileset.
The
The
|
|
|
Displays AdvFS fileset information for a file domain (Section 9.3.5.5) |
Displays information about the filesets
in a file domain, including the fileset names, the total number of files,
the number of used blocks, the quota status, and the clone status.
The
|
|
Displays disk usage and quota limits |
Displays
the block usage, number of files, and quotas for a user or group.
You can
choose to display quota information for users or groups, for all filesets
with usage over quota, or for all mounted filesets regardless of whether quotas
are activated.
See
|
|
Clarifies the relationship between file domain and fileset disk usage |
Reformats output
from the
|
|
Displays a formatted page of the BMT (Section 9.3.5.6) |
The
|
The following sections describe some of these commands in detail.
9.3.5.1 Monitoring AdvFS Performance Statistics by Using the advfsstat Command
The
advfsstat
command displays various AdvFS performance statistics and monitors
the performance of AdvFS domains and filesets.
Use this command to obtain
detailed information, especially if the
iostat
command
output indicates a disk bottleneck (see
Section 8.2).
The
advfsstat
command displays detailed information
about a file domain, including information about the AdvFS buffer cache, fileset
vnode operations, locks, the namei cache, and volume I/O performance.
The
command reports information in units of one disk block (512 bytes).
By default,
the command displays one sample.
You can use the
-i
option
to output information at specific time intervals.
The following example of the
advfsstat -v 2
command
shows the current I/O queue statistics for the specified file domain:
#/usr/sbin/advfsstat -v 2 test_domainvol1 rd wr rg arg wg awg blk wlz sms rlz con dev 54 0 48 128 0 0 0 1 0 0 0 65
The previous example shows the following fields:
Read and write requests--Compare the number of read requests
(rd) to the number of write requests (wr).
Read requests are blocked until the read completes, but write requests will
not block the calling thread, which increases the throughput of multiple threads.
Consolidated reads and writes--You may be able to improve
performance by consolidating reads and writes.
The consolidated read values
(rg
and
arg) and write values (wg
and
awg) indicate the number of disparate
reads and writes that were consolidated into a single I/O to the device driver.
If the number of consolidated reads and writes decreases compared to the number
of reads and writes, AdvFS may not be consolidating I/O.
I/O queue values--The
blk,
wlz,
sms,
rlz,
con, and
dev
fields can indicate potential performance
issues.
The
sms
value specifies the number of requests
on the smooth sync queue.
The
con
value specifies the number
of entries on the consolidate queue.
These entries are ready to be consolidated
and moved to the device queue.
The device queue value (dev)
shows the number of I/O requests that have been issued to the device controller.
The system must wait for these requests to complete.
If the number of I/O requests on the device queue increases continually and you experience poor performance, applications may be I/O bound on this device. You may be able to eliminate the problem by adding more disks to the domain or by striping with LSM or hardware RAID.
You can monitor the type of requests that applications are issuing by
using the
advfsstat
command's
-f
option
to display fileset vnode operations.
You can display the number of file creates,
reads, and writes and other operations for a specified domain or fileset.
For example:
#/usr/sbin/advfsstat -i 3 -f 2 scratch_domain fset1lkup crt geta read writ fsnc dsnc rm mv rdir mkd rmd link 0 0 0 0 0 0 0 0 0 0 0 0 0 4 0 10 0 0 0 0 2 0 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 24 8 51 0 9 0 0 3 0 0 4 0 0 1201 324 2985 0 601 0 0 300 0 0 0 0 0 1275 296 3225 0 655 0 0 281 0 0 0 0 0 1217 305 3014 0 596 0 0 317 0 0 0 0 0 1249 304 3166 0 643 0 0 292 0 0 0 0 0 1175 289 2985 0 601 0 0 299 0 0 0 0 0 779 148 1743 0 260 0 0 182 0 47 0 4 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
See
advfsstat(8)
for more information.
Note that it is difficult to link performance problems to some statistics
such as buffer cache statistics.
In addition, lock performance that is related
to lock statistics cannot be tuned.
9.3.5.2 Identifying Disks in an AdvFS File Domain by Using the advscan Command
The
advscan
command locates pieces of AdvFS domains on disk partitions and in LSM disk
groups.
Use the
advscan
command when you have moved disks
to a new system, have moved disks in a way that has changed device numbers,
or have lost track of where the domains are.
You can specify a list of volumes or disk groups with the
advscan
command to search all partitions and volumes.
The command
determines which partitions on a disk are part of an AdvFS file domain.
You can also use the
advscan
command for repair purposes
if you deleted the
/etc/fdmns
directory, deleted a directory
domain under
/etc/fdmns, or deleted some links from a domain
directory under
/etc/fdmns.
Use the
advscan
command to rebuild all or part of
your
/etc/fdmns
directory, or you can manually rebuild
it by supplying the names of the partitions in a domain.
The following example scans two disks for AdvFS partitions:
#/usr/advfs/advscan dsk0 dsk5Scanning disks dsk0 dsk5 Found domains: usr_domain Domain Id 2e09be37.0002eb40 Created Thu Jun 26 09:54:15 1998 Domain volumes 2 /etc/fdmns links 2 Actual partitions found: dsk0c dsk5c
For the following example, the
dsk6
file domains
were removed from
/etc/fdmns.
The
advscan
command scans device
dsk6
and re-creates the missing domains.
#/usr/advfs/advscan -r dsk6Scanning disks dsk6 Found domains: *unknown* Domain Id 2f2421ba.0008c1c0 Created Mon Jan 20 13:38:02 1998 Domain volumes 1 /etc/fdmns links 0 Actual partitions found: dsk6a* *unknown* Domain Id 2f535f8c.000b6860 Created Tue Feb 25 09:38:20 1998 Domain volumes 1 /etc/fdmns links 0 Actual partitions found: dsk6b* Creating /etc/fdmns/domain_dsk6a/ linking dsk6a Creating /etc/fdmns/domain_dsk6b/ linking dsk6b
See
advscan(8)
for more information.
9.3.5.3 Checking AdvFS File Domains by Using the showfdmn Command
The
showfdmn
command displays the attributes of an AdvFS file domain
and detailed information about each volume in the file domain.
The following example of the
showfdmn
command displays
domain information for the
root_domain
file domain:
%/sbin/showfdmn root_domainId Date Created LogPgs Version Domain Name 34f0ce64.0004f2e0 Wed Mar 17 15:19:48 1999 512 4 root_domain Vol 512-Blks Free % Used Cmode Rblks Wblks Vol Name 1L 262144 94896 64% on 256 256 /dev/disk/dsk0a
See
showfdmn(8)
for more information about the output of the
command.
9.3.5.4 Displaying AdvFS File Information by Using the showfile Command
The
showfile
command displays the full storage allocation map (extent
map) for one or more files in an AdvFS fileset.
An extent is a contiguous
area of disk space that AdvFS allocates to a file.
The following example of the
showfile
command displays
the AdvFS characteristics for all of the files in the current working directory:
#/usr/sbin/showfile *Id Vol PgSz Pages XtntType Segs SegSz I/O Perf File 23c1.8001 1 16 1 simple ** ** ftx 100% OV 58ba.8004 1 16 1 simple ** ** ftx 100% TT_DB ** ** ** ** symlink ** ** ** ** adm 239f.8001 1 16 1 simple ** ** ftx 100% advfs ** ** ** ** symlink ** ** ** ** archive 9.8001 1 16 2 simple ** ** ftx 100% bin (index) ** ** ** ** symlink ** ** ** ** bsd ** ** ** ** symlink ** ** ** ** dict 288.8001 1 16 1 simple ** ** ftx 100% doc 28a.8001 1 16 1 simple ** ** ftx 100% dt ** ** ** ** symlink ** ** ** ** man 5ad4.8001 1 16 1 simple ** ** ftx 100% net ** ** ** ** symlink ** ** ** ** news 3e1.8001 1 16 1 simple ** ** ftx 100% opt ** ** ** ** symlink ** ** ** ** preserve ** ** ** ** advfs ** ** ** ** quota.group ** ** ** ** advfs ** ** ** ** quota.user b.8001 1 16 2 simple ** ** ftx 100% sbin (index) ** ** ** ** symlink ** ** ** ** sde 61d.8001 1 16 1 simple ** ** ftx 100% tcb ** ** ** ** symlink ** ** ** ** tmp ** ** ** ** symlink ** ** ** ** ucb 6df8.8001 1 16 1 simple ** ** ftx 100% users
The
I/O
column specifies whether write operations
are forced to be synchronous.
See
Section 9.3.4.5
for information.
The following example of the
showfile
command shows
the characteristics and extent information for the
tutorial
file, which is a simple file:
#/usr/sbin/showfile -x tutorialId Vol PgSz Pages XtntType Segs SegSz I/O Perf File 4198.800d 2 16 27 simple ** ** async 66% tutorial extentMap: 1 pageOff pageCnt vol volBlock blockCnt 0 5 2 781552 80 5 12 2 785776 192 17 10 2 786800 160 extentCnt: 3
The
Perf
entry shows the efficiency of the file-extent
allocation, expressed as a percentage of the optimal extent layout.
A high
value, such as 100 percent, indicates that the AdvFS I/O subsystem is highly
efficient.
A low value indicates that files may be fragmented.
See
showfile(8)
for more information about the command output.
9.3.5.5 Displaying the AdvFS Filesets in a File Domain by Using the showfsets Command
The
showfsets
command displays the AdvFS filesets (or clone filesets) and their characteristics
in a specified domain.
The following is an example of the
showfsets
command
shows that the
dmn1
file domain has one fileset and one
clone fileset:
#/sbin/showfsets dmn1mnt Id : 2c73e2f9.000f143a.1.8001 Clone is : mnt_clone Files : 7456, SLim= 60000, HLim=80000 Blocks (1k) : 388698, SLim= 6000, HLim=8000 Quota Status : user=on group=on mnt_clone Id : 2c73e2f9.000f143a.2.8001 Clone of : mnt Revision : 2
See
showfsets(8)
for information about the options and output
of the command.
9.3.5.6 Monitoring the Bitmap Metadata Table
The AdvFS fileset data structure (metadata) is stored in a file called the bitfile metadata table (BMT). Each volume in a domain has a BMT that describes the file extents on the volume. If a domain has multiple volumes of the same size, files will be distributed evenly among the volumes.
The BMT is the equivalent of the UFS inode table. However, the UFS inode table is statically allocated, while the BMT expands as more files are added to the domain. Each time AdvFS needs additional metadata, the BMT grows by a fixed size (the default is 128 pages). As a volume becomes increasingly fragmented, the size by which the BMT grows may be described by several extents.
To monitor the BMT, use the
vbmtpg
command and examine
the number of mcells (freeMcellCnt).
The value of
freeMcellCnt
can range from 0 to 22.
A volume with 1 free mcell
has very little space in which to grow the BMT.
See
vbmtpg(8)
for more information.
You can also invoke the
showfile
command and specify
mount_point/.tags/M-10
to examine the BMT
extents on the first domain volume that contains the fileset mounted on the
specified mount point.
To examine the extents of the other volumes in the
domain, specify
M-16,
M-24, and so on.
If the extents at the end of the BMT are smaller than the extents at the beginning
of the file, the BMT is becoming fragmented.
See
showfile(8)
for more information.
9.3.6 Tuning AdvFS
After you configure AdvFS, as described in Section 9.3.4, you may be able to tune it to improve performance. To successfully improve performance, you must understand how your applications and user perform file system I/O, as described in Section 2.1.
Table 9-4
lists AdvFS tuning guidelines and performance
benefits as well as tradeoffs.
The guidelines described in
Table 9-1
also apply to AdvFS configurations.
Table 9-4: AdvFS Tuning Guidelines
| Guideline | Performance Benefit | Tradeoff |
| Decrease the size of the metadata buffer cache to 1 percent (Section 6.4.6) | Improves performance for systems that use only AdvFS | None |
| Increase the percentage of memory allocated for the AdvFS buffer cache (Section 9.3.6.1) | Improves AdvFS performance if data reuse is high | Consumes memory |
| Increase the size of the AdvFS buffer cache hash table (Section 9.3.6.2) | Speeds lookup operations and decreases CPU usage | Consumes memory |
| Increase the memory reserved for AdvFS access structures (Section 9.3.6.3) | Improves AdvFS performance for systems that open and reuse files | Consumes memory |
| Increase the amount of data cached in the ready queue (Section 9.3.6.4) | Improves AdvFS performance for systems that open and reuse files | May cause I/O spikes or increase the number of lost buffers if a crash occurs |
| Increase the smooth sync caching threshold for asynchronous I/O requests (Section 9.3.6.5) | Improves performance of AdvFS asynchronous I/O | Increases the chance that data may be lost if a system crash occurs |
| Increase the maximum number of I/O requests on the device queue (Section 9.3.6.6) | Keeps devices busy | May degrade response time |
Disable the flushing of dirty pages mapped
with the
mmap
function during a
sync
call (Section 9.3.6.7) |
May improve performance for applications that manage their own flushing | None |
The following sections describe the AdvFS tuning guidelines in detail.
9.3.6.1 Increasing the Size of the AdvFS Buffer Cache
The
advfs
subsystem attribute
AdvfsCacheMaxPercent
specifies the
maximum percentage of physical memory that can be used to cache AdvFS file
data.
Caching AdvFS data improves I/O performance only if the cached data
is reused.
Performance Benefit and Tradeoff
If data reuse is high, you may be able to improve AdvFS performance by increasing the percentage of memory allocated to the AdvFS buffer cache. However, this will decrease the amount of memory available for processes.
You also may need to increase the number of AdvFS buffer cache hash chains to increase the size of the AdvFS buffer cache. See Section 9.3.6.2 for information.
You cannot modify the
AdvfsCacheMaxPercent
attribute
without rebooting the system.
When to Tune
You may need to increase the size of the AdvFS buffer cache if data reuse is high and if pages are being rapidly recycled. Increasing the size of the buffer cache will enable pages to remain in the cache for a longer period of time. This increases the chance that a cache hit will occur.
Use the
advfsstat -b
command to determine if pages
are being recycled too quickly.
If the command output shows that the ratio
of total hits (hit) to total counts (cnt),
for both
pin
and
ref, is less than 85
percent, pages are being rapidly recycled.
Recommended Values
The default value of the
AdvfsCacheMaxPercent
attribute
is 7 percent of memory.
The minimum value is 1 percent; the maximum value
is 30 percent.
Increase the value of the
AdvfsCacheMaxPercent
attribute
only by small increments to optimize file system performance without wasting
memory.
If you increase the value of the
AdvfsCacheMaxPercent
attribute and experience no performance benefit, return to the original value.
Use the
vmstat
command to check virtual memory statistics,
as described in
Section 6.3.1.
Make sure that increasing the
size of the AdvFS buffer cache does not cause excessive paging and swapping.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.3.6.2 Increasing the Number of AdvFS Buffer Hash Chains
The buffer cache
hash table for the AdvFS buffer cache is used to locate pages of AdvFS file
data in memory.
The table contains a number of hash chains, which contain
elements that point to pages of file system data that have already been read
into memory.
When a
read
or
write
system
call is done for a particular offset within an AdvFS file, the system sequentially
searches the appropriate hash chain to determine if the file data is already
in memory.
The value of the
advfs
subsystem attribute
AdvfsCacheHashSize
specifies the number of hash chains (entries)
on the AdvFS buffer cache hash table.
Performance Benefit and Tradeoff
Increasing the number of hash chains on the buffer cache hash table will result in shorter hash chains. Short hash chains contain less elements to search, which increases search speeds and decreases CPU usage.
Increasing the size of the AdvFS buffer cache hash table will increase the amount of wired memory.
You cannot modify the
AdvfsCacheHashSize
attribute
without rebooting the system.
When to Tune
If you have more than 4 GB of memory, you may want to increase the value
of the
AdvfsCacheHashSize
attribute, which will increase
the number of hash chains on the table.
To determine if your system performance may benefit from increasing
the size of the buffer hash table, divide the number of AdvFS buffers by the
current value of the
AdvfsCacheHashSize
attribute.
Use
the
sysconfig -q advfs AdvfsCacheHashSize
to determine
the current value of the attribute.
To obtain the number of AdvFS buffers,
examine the AdvFS system initialization message that reports this value and
the total amount of memory being used.
The result of the previous calculation will show the average number of buffers for each buffer hash table chain. A small number means fewer potential buffers that AdvFS must search. This assumes that buffers are evenly distributed across the AdvFS buffer cache hash table. If the average number of buffers for each chain is greater that 100, you may want to increase the size of the hash chain table.
Recommended Values
The default value of the
AdvfsCacheHashSize
attribute
is either 8192 KB or 10 percent of the size of the AdvFS buffer cache (rounded
up to the next power of 2), whichever is the smallest value.
The minimum value
is 1024 KB.
The maximum value is either 65536 or the size of the AdvFS buffer
cache, whichever is the smallest value.
The
AdvfsCacheMaxPercent
attribute specifies the size of the AdvFS buffer cache (see
Section 9.3.6.1).
You may want to double the default value of the
AdvfsCacheHashSize
attribute if the system is experiencing high CPU system time (see
Section 6.3.1), or if a kernel profile shows high percentage of CPU
usage in the
find_page
routine.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.3.6.3 Increasing the Memory for Access Structures
AdvFS access structures are in-memory data structures that AdvFS uses to cache low-level information about files that are currently open and files that were opened but are now closed. Caching open file information can enhance AdvFS performance if the open files are later reused.
At boot time, the system reserves for AdvFS access structures a portion of physical memory that is not wired. Access structures are placed on the access structure free list, and are allocated and deallocated according to the kernel configuration and workload demands.
There are three attributes that control the allocation of AdvFS access structures:
The
AdvfsAccessMaxPercent
attribute controls
the maximum percentage of pageable memory that can be allocated for AdvFS
access structures.
At boot time, and when the number of access structures on
the free list is less than the value of the
AdvfsMinFreeAccess
attribute, AdvFS allocates additional access structures, until the number
of access structures on the free list is twice the value of the
AdvfsMinFreeAccess
attribute or the value of the
AdvfsAccessMaxPercent
attribute, whichever is smaller.
The
AdvfsMaxFreeAccessPercent
attribute
controls when access structures are deallocated from the free list.
When the
percentage of access structures on the free list is more than the value of
the
AdvfsMaxFreeAccessPercent
attribute, and the number
of access structures on the free list is more than twice the value of the
AdvfsMinFreeAccess
attribute, AdvFS deallocates access structures.
See Section 9.3.3 for information about access structures and attributes.
Performance Benefit and Tradeoff
Increasing the value of the
AdvfsAccessMaxPercent
attribute allows you to allocate more memory resources for access structures,
which may improve AdvFS performance on systems that open and reuse many files.
However, this increases memory consumption.
If you increase the value of the
AdvfsMinFreeAccess
attribute, you will retain more access structures on the free list and delay
access structure deallocation, which may improve AdvFS performance for systems
that open and reuse many files.
However, this increases memory consumption.
If you increase the value of the
AdvfsMaxFreeAccessPercent
attribute, the system will retain access structures on the free
list for a longer time, which may improve AdvFS performance for systems that
open and reuse many files.
You can modify the
AdvfsAccessMaxPercent,
AdvfsMinFreeAccess, and
AdvfsMaxFreeAccessPercent
attributes without rebooting the system.
When to Tune
If your users or applications open and then reuse many AdvFS files (for example, if you have a proxy server), you may be able to improve AdvFS performance by increasing memory resources for access structures.
If you do not use AdvFS, if your workload does not frequently write to previously written pages, or if you have a large-memory system, you may want to decrease the memory allocated for access structures. See Section 6.4.5 for information.
Recommended Values
The default value of the
AdvfsAccessMaxPercent
attribute
is 25 percent of pageable memory.
The minimum value is 5 percent; the maximum
value is 95 percent.
The default value of the
AdvfsMinFreeAccess
attribute
is 128.
The minimum value is 1; the maximum value is 100,000.
The default value of the
AdvfsMaxFreeAccessPercent
attribute is 80 percent.
The minimum value is 5 percent; the maximum value
is 95 percent.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.3.6.4 Increasing Data Cached in the Ready Queue
AdvFS caches asynchronous I/O requests in the AdvFS buffer cache. If the cached data is later reused, pages can be retrieved from memory and a disk operation is avoided.
Asynchronous I/O requests are sorted in the ready queue and remain there
until the size of the queue reaches the value specified by the
AdvfsReadyQLim
attribute or, if smooth sync is not enabled, until the
update
daemon flushes the data.
See
Section 9.3.2
for more information about AdvFS queues.
See
Section 9.3.6.5
for information about using smooth sync to control asynchronous I/O request
caching.
Performance Benefit and Tradeoff
Increasing the size of the ready queue can improve AdvFS performance if data is reused by increasing the time that a buffer will stay on the I/O queue and not be flushed to disk.
You can modify the
AdvfsReadyQLim
attribute without
rebooting the system.
When to Tune
If you have high data reuse (data is repeatedly read and written), you may want to increase the size of the ready queue. This can increase the number of AdvFS buffer cache hits. If you have low data reuse, it is recommended that you use the default value.
Recommended Values
You can modify the size of the ready queue for all AdvFS volumes by
changing the value of the
AdvfsReadyQLim
attribute.
The
default value of the
AdvfsReadyQLim
attribute is 16,384
512-byte blocks (8 MB).
You can modify the size for a specific AdvFS volume by using the
chvol -t
command.
See
chvol(8)
for more information.
If you change the size of the ready queue and performance does not improve, return to the original value.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.3.6.5 Increasing the AdvFS Smooth Sync Cache Timeout Value
Smooth
sync functionality improves AdvFS asynchronous I/O performance by preventing
I/O spikes caused by the
update
daemon, increasing the
chance of an AdvFS buffer cache hit, and improving the consolidation of I/O
requests.
By default, smooth sync is enabled on your system.
AdvFS uses I/O request queues to cache asynchronous I/O requests before
they are handed to the device driver.
Without smooth sync enabled, every 30
seconds, the
update
daemon flushes data from memory to
disk, regardless of how long a buffer has been cached.
However, with smooth
sync enabled (the default), the
update
daemon will not
automatically flush the AdvFS ready queue buffers.
Instead, asynchronous I/O
requests remain in the smooth sync queue for the amount of time specified
by the value of the
vfs
attribute
smoothsync_age
(the default is 30 seconds).
After this time, the buffer moves
to the ready queue.
You enable smooth sync functionality (the default) by using the
smoothsync_age
attribute.
However, you do not specify a value for
smoothsync_age
in the
/etc/sysconfigtab
file.
Instead, the
/etc/inittab
file is used to enable smooth
sync when the system boots to multiuser mode, and to disable smooth sync when
the system goes from multiuser mode to single-user mode.
This procedure is
necessary to reflect the behavior of the
update
daemon,
which operates only in multiuser mode.
To enable smooth sync, the following lines must be included in the
/etc/inittab
file and the time limit for caching buffers in the
smooth sync queue must be specified (the default is 30 seconds):
smsync:23:wait:/sbin/sysconfig -r vfs smoothsync_age=30 > /dev/null 2>&1 smsyncS:Ss:wait:/sbin/sysconfig -r vfs smoothsync_age=0 > /dev/null 2>&1
Performance Benefit and Tradeoff
Increasing the amount of time an asynchronous I/O request remains in the smooth sync queue increases the chance that a buffer cache hit will occur, which improves AdvFS performance if data is reused. However, this also increases the chance that data may be lost if a system crash occurs.
Decreasing the value of the
smoothsync_age
attribute
will speed the flushing of buffers.
When to Tune
You may want to increase the amount of time an asynchronous I/O request remains in the smooth sync queue if you reuse AdvFS data.
Recommended Values
Thirty seconds is the default smooth sync queue timeout limit.
If you
increase the value of the
smoothsync_age
attribute in the
/etc/inittab
file, you may improve the chance of a buffer cache
hit by retaining buffers on the smooth sync queue for a longer period of time.
Use the
advfsstat -S
command to show the AdvFS smooth sync
queue statistics.
To disable smooth sync, specify a value of 0 (zero) for the
smoothsync_age
attribute.
9.3.6.6 Specifying the Maximum Number of I/O Requests on the Device Queue
Small, logically contiguous AdvFS I/O requests are consolidated into larger I/O requests and put on the device queue, before they are sent to the device driver. See Section 9.3.2 for more information about AdvFS queues.
The
AdvfsMaxDevQLen
attribute controls the maximum
number of I/O requests on the device queue.
When the number of requests on
the queue exceeds this value, only synchronous requests are accepted onto
the device queue.
Performance Benefit and Tradeoff
Increasing the size of the device queue can keep devices busy, but may degrade response time.
Decreasing the size of the device queue decreases the amount of time it takes to complete a synchronous (blocking) I/O operation and can improve response time.
You can modify the
AdvfsMaxDevQLen
attribute without
rebooting the system.
When to Tune
Although the default value of the
AdvfsMaxDevQLen
attribute is appropriate for many configurations, you may need to modify this
value.
Increase the default value of the
AdvfsMaxDevQLen
attribute only if devices are not being kept busy.
Recommended Values
The default value of the
AdvfsMaxDevQLen
attribute
is 24 requests.
The minimum value is 0; the maximum value is 65536.
A guideline
is to specify a value for the
AdvfsMaxDevQLen
attribute
that is less than or equal to the average number of I/O operations that can
be performed in 0.5 seconds.
Make sure that increasing the size of the device queue does not cause
a decrease in response time.
To calculate response time, multiply the value
of the
AdvfsMaxDevQLen
attribute by the average I/O latency
time for your disks.
If you do not want to limit the number of requests on the device queue,
set the value of the
AdvfsMaxDevQLen
attribute to 0 (zero),
although this is not recommended.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.3.6.7 Disabling the Flushing of Modified mmapped Pages
The AdvFS buffer cache can contain modified data due to a
write
system call or a memory write reference after an
mmap
system call.
The
update
daemon runs every
30 seconds and issues a
sync
call for every fileset mounted
with read and write access.
However, if smooth sync is enabled (the default),
the
update
daemon will not flush the ready queue.
Instead,
asynchronous I/O requests remain in the smooth sync queue for the amount of
time specified by the value of the
vfs
attribute
smoothsync_age
(the default is 30 seconds).
See
Section 9.3.6.5
for information about the smooth sync queue.
The
AdvfsSyncMmapPages
attribute controls whether
modified (dirty) mmapped pages are flushed to disk during a
sync
system call.
If the
AdvfsSyncMmapPages
attribute
is set to 1 (the default), the modified mmapped pages are asynchronously written
to disk.
If the
AdvfsSyncMmapPages
attribute is set to
0, modified mmapped pages are not written to disk during a
sync
system call.
Performance Benefit
Disabling the flushing of modified mmapped pages may improve performance
of applications that manage their own
mmap
page flushing.
You can modify the
AdvfsSyncMmapPages
attribute without
rebooting the system.
When to Tune
Disable flushing mmapped pages only if your applications manage their
own
mmap
page flushing.
Recommended Values
If your applications manage their own
mmap
page flushing,
set the value of the
AdvfsSyncMmapPages
attribute to zero.
See
mmap(2)
and
msync(2)
for more information.
See
Section 3.6
for information about modifying kernel subsystem attributes.
9.3.7 Improving AdvFS Performance
After you configure AdvFS, as described in Section 9.3.4, you may be able to improve performance by performing some administrative tasks.
Table 9-4
lists AdvFS performance improvement
guidelines and performance benefits as well as tradeoffs.
Table 9-5: AdvFS Performance Improvement Guidelines
| Guideline | Performance Benefit | Tradeoff |
| Defragment file domains (Section 9.3.7.1) | Improves read and write performance | Procedure is time-consuming |
| Decrease the I/O transfer read-ahead size (Section 9.3.7.2) | Improves performance for
mmap
page faulting |
None |
| Move the transaction log to a fast or uncongested volume (Section 9.3.7.3) | Prevents log from becoming a bottleneck | None |
| Balance files across volumes in a file domain (Section 9.3.7.4) | Improves performance and evens the future distribution of files | None |
| Migrate frequently used or large files to different file domains (Section 9.3.7.5) | Improves I/O performance | None |
The following sections describe the AdvFS performance improvement
guidelines in detail.
9.3.7.1 Defragmenting a File Domain
An extent is a contiguous area of disk space that AdvFS allocates to a file. Extents consist of one or more 8-KB pages. When storage is added to a file, it is grouped in extents. If all data in a file is stored in contiguous blocks, the file has one file extent. However, as files grow, contiguous blocks on the disk may not be available to accommodate the new data, so the file must be spread over discontiguous blocks and multiple file extents.
File I/O is most efficient when there are few extents. If a file consists of many small extents, AdvFS requires more I/O processing to read or write the file. Disk fragmentation can result in many extents and may degrade read and write performance because many disk addresses must be examined to access a file. In addition, if a domain has a large number of small files, you may prematurely run out of disk space due to fragmentation.
Use the
defragment
utility to reduce the amount of
file fragmentation in a file domain by attempting to make the files more contiguous,
which reduces the number of file extents.
The utility does not affect data
availability and is transparent to users and applications.
Striped files are
not defragmented.
Performance Benefit and Tradeoff
Defragmenting improves AdvFS performance by making AdvFS disk I/O more efficient. However, the defragment process can be time-consuming and requires disk space in order to run.
When to Perform this Task
Compaq recommends that you run
defragment
only if you experience problems because of excessive fragmentation and only
when there is low file system activity.
In addition, there is little performance
benefit from defragmenting in the following circumstances:
A file domain contains primarily files that are smaller than 8 KB.
A file domain is used in a mail server.
A file domain is read-only.
To determine if a file domain is fragmented, use the
defragment
utility with the
-v
and
-n
options to show the amount of file fragmentation.
Ideally, you
want few extents for each file.
For example:
#defragment -vn staff_dmndefragment: Gathering data for 'staff_dmn' Current domain data: Extents: 263675 Files w/ extents: 152693 Avg exts per file w/exts: 1.73 Aggregate I/O perf: 70% Free space fragments: 85574 <100K <1M <10M >10M Free space: 34% 45% 19% 2% Fragments: 76197 8930 440 7
You can also use the
showfile
command to check a
file's fragmentation.
See
Section 9.3.5.4
for information.
Recommended Procedure
You can improve the efficiency of the defragmenting process by deleting
any unneeded files in the file domain before running the
defragment
utility.
See
defragment(8)
for more information.
9.3.7.2 Decreasing the I/O Transfer Size
AdvFS reads and writes data by a fixed number of 512-byte blocks. The default value depends on the disk driver's reported preferred transfer size. For example, a common default value is either 128 blocks or 256 blocks.
If you use the
addvol
or
mkfdmn
command on a Logical Storage Manager (LSM) volume, the preferred transfer
size may be larger than if LSM was not used.
The value depends on how you
configured the LSM volume.
Performance Benefit
You may be able to improve performance for
mmap
page
faulting and reduce read-ahead paging and cache dilution by decreasing the
read-ahead size.
When to Perform this Task
You may want to decrease the I/O transfer size if you experience performance problems with AdvFS I/O throughput.
Recommended Procedure
To display the range of I/O transfer sizes, use the
chvol -l
command.
Use the
chvol -r
command to modify
the read I/O transfer size (the amount of data read for each I/O request).
Use the
chvol -w
command to modify the write I/O transfer
size (the amount of data written for each I/O request).
You can decrease the read-ahead size by using the
chvol -r
command.
You can decrease the amount of data written for each I/O request by
using the
chvol -w
command.
In general, you want to maximize
the amount of data written for each I/O by using the default write I/O transfer
size or a larger value.
However, in some cases (for example, if you are using LSM volumes), you may need to reduce the AdvFS write-consolidation size. If your AdvFS domains are using LSM, the default preferred transfer size is high, and I/O throughput is not optimal, reduce the write I/O transfer size.
See
chvol(8)
for more information.
9.3.7.3 Moving the Transaction Log
The AdvFS transaction log should be located on a fast or uncongested disk and bus; otherwise, performance may be degraded.
Performance Benefit
Locating the transaction log on a fast or uncongested bus improves performance.
When to Tune
Use the
showfdmn
command to determine the current
location of the transaction log.
In the
showfdmn
command
display, the letter
L
displays next to the volume that
contains the log.
Move the transaction log if the volume on which it resides
is busy and the transaction log is a bottleneck.
See
showfdmn(8)
for more information.
Recommended Procedure
Use the
switchlog
command to relocate the transaction
log of the specified file domain to a faster or less congested volume in the
same domain.
See
switchlog(8)
for more information.
In addition, you can divide a large multi-volume file domain into several
smaller file domains.
This will distribute the transaction log I/O across
multiple logs.
9.3.7.4 Balancing a Multivolume File Domain
If the files in a multivolume
domain are not evenly distributed, performance may be degraded.
Use the
balance
utility to distribute the percentage of used space evenly
across volumes in a multivolume file domain.
This improves performance and
the distribution of future file allocations.
Files are moved from one volume
to another until the percentage of used space on each volume in the domain
is as equal as possible.
The
balance
utility does not affect data availability
and is transparent to users and applications.
If possible, use the
defragment
utility before you balance files.
The
balance
utility does not generally split files.
Therefore, file domains with very large files may not balance as evenly as
file domains with smaller files.
Performance Benefit
Balancing files across the volumes in a file domain improves the distribution of disk I/O.
When to Perform this Task
You may want to balance a file domain if the files are not evenly distributed across the domain.
To determine if you need to balance your files across volumes, use the
showfdmn
command to display information about the volumes in a domain.
The
% Used
field shows the percentage of volume space that
is currently allocated to files or metadata (fileset data structure).
In the
following example, the
usr_domain
file domain is not balanced.
Volume 1 has 63% used space while volume 2 has 0% used space (it has just
been added).
# showfdmn usr_domain
Id Date Created LogPgs Version Domain Name
3437d34d.000ca710 Sun Oct 5 10:50:05 1997 512 3 usr_domain
Vol 512-Blks Free % Used Cmode Rblks Wblks Vol Name
1L 1488716 549232 63% on 128 128 /dev/disk/dsk0g
2 262144 262000 0% on 128 128 /dev/disk/dsk4a
--------- ------- ------
1750860 811232 54%
See
showfdmn(8)
for more information.
Recommended Procedure
Use the
balance
utility to distribute the percentage
of used space evenly across volumes in a multivolume file domain.
See
balance(8)
for more information.
9.3.7.5 Migrating Files Within a File Domain
Performance may degrade if too many frequently accessed or large files reside on the same volume in a multivolume file domain. You can improve I/O performance by altering the way files are mapped on the disk.
Use the
migrate
utility to move frequently accessed
or large files to different volumes in the file domain.
You can specify the
volume where a file is to be moved, or allow the system to pick the best space
in the file domain.
You can migrate either an entire file or specific pages
to a different volume.
In addition, the
migrate
command enables you to defragment
a specific file and make the file more contiguous, which improves performance.
Performance Benefit
Distributing the I/O load across the volumes in a file domain improves AdvFS performance.
When to Perform this Task
To determine which files to move, use the
showfile -x
command to look at the extent map and the performance percentage of a file.
A low performance percentage (less than 80%) indicates that the file is fragmented
on the disk.
The extent map shows whether the entire file or a portion of
the file is fragmented.
The following example displays the extent map of a file called
src.
The file, which resides in a two-volume file domain, shows
an 18% performance efficiency in the
Perf
field.
# showfile -x src
Id Vol PgSz Pages XtntType Segs SegSz I/O Perf File
8.8002 1 16 11 simple ** ** async 18% src
extentMap: 1
pageOff pageCnt vol volBlock blockCnt
0 1 1 187296 16
1 1 1 187328 16
2 1 1 187264 16
3 1 1 187184 16
4 1 1 187216 16
5 1 1 187312 16
6 1 1 187280 16
7 1 1 187248 16
8 1 1 187344 16
9 1 1 187200 16
10 1 1 187232 16
extentCnt: 11
The file
src
consists of 11 file extents.
This file
would be a good candidate to move to another volume to reduce the number of
file extents.
See Section 8.2 for information about using commands to determine if file system I/O is evenly distributed.
Recommended Procedure
Use the
migrate
utility to move frequently accessed
or large files to different volumes in the file domain.
Note that using the
balance
utility after migrating files may cause the files to move
to a different volume.
See
migrate(8)
and
balance(8)
for more information.
9.4 Managing UFS Performance
The UNIX File System (UFS) can provide you with high-performance file system operations, especially for critical applications. For example, UFS file reads from striped disks can be 50 percent faster than if you are using AdvFS, and will consume only 20 percent of the CPU power that AdvFS requires.
However, unlike AdvFS, the UFS file system directory hierarchy is bound tightly to a single disk partition.
The following sections describe:
Using the UFS guidelines to set up a high-performance configuration (Section 9.4.1)
Obtaining information about UFS performance (Section 9.4.2)
Tuning UFS in order to improve performance (Section 9.4.3)
9.4.1 UFS Configuration Guidelines
There are a number of parameters
that can improve the UFS performance.
You can set all of the parameters when
you use the
newfs
command to create a file system.
For
existing file systems, you can modify some parameters by using the
tunefs
command.
See
newfs(8)
and
tunefs(8)
for more information.
Table 9-6
describes UFS configuration guidelines
and performance benefits as well as tradeoffs.
Table 9-6: UFS Configuration Guidelines
| Guideline | Performance Benefit | Tradeoff |
| Make the file system fragment size equal to the block size (Section 9.4.1.1) | Improves performance for large files | Wastes disk space for small files |
| Use the default file system fragment size of 1 KB (Section 9.4.1.1) | Uses disk space efficiently | Increases the overhead for large files |
| Reduce the density of inodes on a file system (Section 9.4.1.2) | Frees disk space for file data and improves large file performance | Reduces the number of files that can be created on the file system |
| Allocate blocks sequentially (Section 9.4.1.3) | Improves performance for disks that do not have a read-ahead cache | Reduces the total available disk space |
| Increase the number of blocks combined for a cluster (Section 9.4.1.4) | May decrease number of disk I/O operations | May require more memory to buffer data |
| Use a Memory File System (MFS) (Section 9.4.1.5) | Improves I/O performance | Does not ensure data integrity because of cache volatility |
| Use disk quotas (Section 9.4.1.6) | Controls disk space utilization | UFS quotas may result in a slight increase in reboot time |
| Increase the maximum number of UFS and MFS mounts (Section 9.4.1.7) | Allows more mounted file systems | Requires additional memory resources |
The following sections describe the UFS configuration guidelines in
detail.
9.4.1.1 Modifying the File System Fragment and Block Sizes
The UFS file system block size is 8 KB.
The default fragment size
is 1 KB.
You can use the
newfs
command to modify the fragment
size so that it is 25, 50, 75, or 100 percent of the block size.
The
UFS file system block size can be 8 KB (the default), 16 KB, 32 KB, or 64
KB.
The default fragment size is 1 KB.
You can modify the fragment size so
that it is 25, 50, 75, or 100 percent of the block size.
Use the
newfs
command to modify block and fragment sizes.
Although the default fragment size uses disk space efficiently, it increases the overhead for large files. If the average file in a file system is larger than 16 KB but less than 96 KB, you may be able to improve disk access time and decrease system overhead by making the file system fragment size equal to the default block size (8 KB).
See
newfs(8)
for more information.
9.4.1.2 Reducing the Density of inodes
An inode describes an individual file in the file system. The maximum number of files in a file system depends on the number of inodes and the size of the file system. The system creates an inode for each 4 KB (4096 bytes) of data space in a file system.
If a file system will contain many large files and you are sure that you will not create a file for each 4 KB of space, you can reduce the density of inodes on the file system. This will free disk space for file data, but will reduce the number of files that can be created.
To do this, use the
newfs -i
command to specify
the amount of data space allocated for each inode.
See
newfs(8)
for more information.
9.4.1.3 Allocating Blocks Sequentially
The UFS
rotdelay
parameter specifies
the time, in milliseconds, to service a transfer completion interrupt and
initiate a new transfer on the same disk.
You can set the
rotdelay
parameter to 0 (the default) to allocate blocks sequentially.
This
is useful for disks that do not have a read-ahead cache.
However, it will
reduce the total amount of available disk space.
Use either the
tunefs
command or the
newfs
command to modify the
rotdelay
value.
See
newfs(8)
and
tunefs(8)
for more information.
9.4.1.4 Increasing the Number of Blocks Combined for a Cluster
The value of the UFS
maxcontig
parameter specifies the number of blocks that can be combined into a single
cluster (or file-block group).
The default value of
maxcontig
is 8.
The file system attempts I/O operations in a size that is determined
by the value of
maxcontig
multiplied by the block size
(8 KB).
Device drivers that can chain several buffers together in a single transfer
should use a
maxcontig
value that is equal to the maximum
chain length.
This may reduce the number of disk I/O operations.
However,
more memory will be needed to cache data.
Use the
tunefs
command or the
newfs
command to change the value of
maxcontig.
See
newfs(8)
and
tunefs(8)
for more information.
9.4.1.5 Using MFS
The Memory File System (MFS) is a UFS file system that resides only in memory. No permanent data or file structures are written to disk. An MFS can improve read/write performance, but it is a volatile cache. The contents of an MFS are lost after a reboot, unmount operation, or power failure.
Because no data is written to disk, an MFS is a very fast file system and can be used to store temporary files or read-only files that are loaded into the file system after it is created. For example, if you are performing a software build that would have to be restarted if it failed, use an MFS to cache the temporary files that are created during the build and reduce the build time.
See
mfs(8)
for information.
9.4.1.6 Using UFS Disk Quotas
You can specify UFS file system limits for user accounts and for groups by setting up UFS disk quotas, also known as UFS file system quotas. You can apply quotas to file systems to establish a limit on the number of blocks and inodes (or files) that a user account or a group of users can allocate. You can set a separate quota for each user or group of users on each file system.
You may want to set quotas on file systems that contain home directories,
because the sizes of these file systems can increase more significantly than
other file systems.
Do not set quotas on the
/tmp
file
system.
Note that, unlike AdvFS quotas, UFS quotas may cause a slight increase
in reboot time.
For information about AdvFS quotas, see
Section 9.3.4.10.
For information about UFS quotas, see the
System Administration
manual.
9.4.1.7 Increasing the Number of UFS and MFS Mounts
Mount structures
are dynamically allocated when a mount request is made and subsequently deallocated
when an unmount request is made.
The
vfs
subsystem attribute
max_ufs_mounts
specifies the maximum number of UFS and MFS mounts
on the system.
Performance Benefit and Tradeoff
Increasing the maximum number of UFS and MFS mounts enables you to mount more file systems. However, increasing the maximum number mounts requires memory resources for the additional mounts.
You can modify the
max_ufs_mounts
attribute without
rebooting the system.
When to Tune
Increase the maximum number of UFS and MFS mounts if your system will have more than the default limit of 1000 mounts.
Recommended Values
The default value of the
max_ufs_mounts
attribute
is 1000.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.4.2 Gathering UFS Information
Table 9-7
describes the tools you can use to obtain information about UFS.
Table 9-7: UFS Monitoring Tools
| Name | Use | Description |
|
Displays UFS information (Section 9.4.2.1) |
Displays detailed information about a UFS file system or a special device, including information about the file system fragment size, the percentage of free space, super blocks, and the cylinder groups. |
Reports UFS clustering statistics (Section 9.4.2.2) |
Reports statistics on how the system is performing cluster read and write transfers. |
|
Reports UFS metadata buffer cache statistics (Section 9.4.2.3) |
Reports statistics on the metadata buffer cache, including superblocks, inodes, indirect blocks, directory blocks, and cylinder group summaries. |
The following sections describe these commands in detail.
9.4.2.1 Displaying UFS Information by Using the dumpfs Command
The
dumpfs
command displays
UFS information, including super block and cylinder group information, for
a specified file system.
Use this command to obtain information about the
file system fragment size and the minimum free space percentage.
The following
example shows part of the output of the
dumpfs
command:
#/usr/sbin/dumpfs /devices/disk/dsk0g | moremagic 11954 format dynamic time Tue Sep 14 15:46:52 1998 nbfree 21490 ndir 9 nifree 99541 nffree 60 ncg 65 ncyl 1027 size 409600 blocks 396062 bsize 8192 shift 13 mask 0xffffe000 fsize 1024 shift 10 mask 0xfffffc00 frag 8 shift 3 fsbtodb 1 cpg 16 bpg 798 fpg 6384 ipg 1536 minfree 10% optim time maxcontig 8 maxbpg 2048 rotdelay 0ms headswitch 0us trackseek 0us rps 60
The information contained in the first lines are relevant for tuning. Of specific interest are the following fields:
bsize
-- The block size of the file
system, in bytes (8 KB).
fsize
-- The fragment size of the
file system, in bytes.
For the optimum I/O performance, you can modify the
fragment size.
minfree
-- The percentage of space
that cannot be used by normal users (the minimum free space threshold).
maxcontig
-- The maximum number of
contiguous blocks that will be laid out before forcing a rotational delay;
that is, the number of blocks that are combined into a single read request.
maxbpg
-- The maximum number of blocks
any single file can allocate out of a cylinder group before it is forced to
begin allocating blocks from another cylinder group.
A large value for
maxbpg
can improve performance for large files.
rotdelay
-- The expected time (in
milliseconds) to service a transfer completion interrupt and initiate a new
transfer on the same disk.
It is used to decide how much rotational spacing
to place between successive blocks in a file.
If
rotdelay
is zero, then blocks are allocated contiguously.
9.4.2.2 Monitoring UFS Clustering by Using the dbx Debugger
To determine how efficiently the system is performing cluster
read and write transfers, use the
dbx print
command to
examine the
ufs_clusterstats
data structure.
The following example shows a system that is not clustering efficiently:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)print ufs_clusterstatsstruct { full_cluster_transfers = 3130 part_cluster_transfers = 9786 non_cluster_transfers = 16833 sum_cluster_transfers = { [0] 0 [1] 24644 [2] 1128 [3] 463 [4] 202 [5] 55 [6] 117 [7] 36 [8] 123 [9] 0 } } (dbx)
The preceding example shows 24644 single-block transfers and no 9-block transfers. A single block is 8 KB. The trend of the data shown in the example is the reverse of what you want to see. It shows a large number of single-block transfers and a declining number of multiblock (1-9) transfers. However, if the files are all small, this may be the best blocking that you can achieve.
You can examine the cluster reads and writes separately with the
ufs_clusterstats_read
and
ufs_clusterstats_write
data structures.
See
Section 9.4.3
for information on tuning UFS.
9.4.2.3 Checking the Metadata Buffer Cache by Using the dbx Debugger
The
metadata buffer cache contains UFS file metadata--superblocks, inodes,
indirect blocks, directory blocks, and cylinder group summaries.
To check
the metadata buffer cache, use the
dbx print
command to
examine the
bio_stats
data structure.
Consider the following example:
#/usr/ucb/dbx -k /vmunix /dev/mem(dbx)print bio_statsstruct { getblk_hits = 4590388 getblk_misses = 17569 getblk_research = 0 getblk_dupbuf = 0 getnewbuf_calls = 17590 getnewbuf_buflocked = 0 vflushbuf_lockskips = 0 mntflushbuf_misses = 0 mntinvalbuf_misses = 0 vinvalbuf_misses = 0 allocbuf_buflocked = 0 ufssync_misses = 0 } (dbx)
If the miss rate is high,
you may want to raise the value of the
bufcache
attribute.
The number of block misses (getblk_misses) divided by the
sum of block misses and block hits (getblk_hits) should
not be more than 3 percent.
See
Section 9.4.3.1
for information on how to tune the
metadata buffer cache.
9.4.3 Tuning UFS
After you configure your UFS file systems, you may be able to improve UFS performance. To successfully improve performance, you must understand how your applications and users perform file system I/O, as described in Section 2.1.
Table 9-8
describes UFS tuning guidelines and performance
benefits as well as tradeoffs.
The guidelines described in
Table 9-1
also apply to UFS configurations.
Table 9-8: UFS Tuning Guidelines
| Guideline | Performance Benefit | Tradeoff |
| Increase the size of metadata buffer cache to more than 3 percent of main memory (Section 9.4.3.1) | Increases cache hit rate and improves UFS performance | Requires additional memory resources |
| Increase the size of the metadata hash chain table (Section 9.4.3.2) | Improves UFS lookup speed | Increases wired memory |
| Increase the smooth sync caching threshold for asynchronous UFS I/O requests (Section 9.4.3.3) | Improves performance of AdvFS asynchronous I/O | Increases the chance that data may be lost if a system crash occurs |
| Delay flushing UFS clusters to disk (Section 9.4.3.4) | Frees CPU cycles and reduces number of I/O operations | May degrade real-time workload performance when buffers are flushed |
| Increase number of blocks combined for read ahead (Section 9.4.3.5) | May reduce disk I/O operations | May require more memory to buffer data |
| Increase number of blocks combined for a cluster (Section 9.4.3.6) | May decrease disk I/O operations | Reduces available disk space |
| Defragment the file system (Section 9.4.3.7) | Improves read and write performance | Requires down time |
The following sections describe how to tune UFS in detail.
9.4.3.1 Increasing the Size of the Metadata Buffer Cache
At boot time,
the kernel wires a percentage of physical memory for the metadata buffer cache,
which temporarily holds recently accessed UFS and CD-ROM File System (CDFS)
metadata.
The
vfs
subsystem attribute
bufcache
specifies the size of the metadata buffer cache as a percentage
of physical memory.
See
Section 6.1.2.1
for information about
how memory is allocated to the metadata buffer cache.
Performance Benefit and Tradeoff
Allocating additional memory to the metadata buffer cache may improve UFS performance if you reuse files, but it will reduce the amount of memory available to processes and the UBC.
You cannot modify the
bufcache
attribute without
rebooting the system.
When to Tune
Usually, you do not have to increase the size of the metadata buffer cache.
However, you may want to increase the size of the cache if you reuse
data and have a high cache miss rate (low hit rate).
To determine whether to increase the size of the metadata buffer
cache, use the
dbx print
command to examine the
bio_stats
data structure.
If the miss rate (block misses divided
by the sum of the block misses and block hits) is more than 3 percent, you
may want to increase the cache size.
See
Section 9.4.2.3
for more information.
Recommended Values
The default value of the
bufcache
attribute is 3
percent.
If you have a general-purpose timesharing system, do not increase the
value of the
bufcache
attribute to more than 10 percent.
If you have an NFS server that does not perform timesharing, do not increase
the value of the
bufcache
attribute to more than 35 percent.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.4.3.2 Increasing the Size of the Metadata Hash Chain Table
The
hash chain table for the metadata buffer cache stores the heads of the hashed
buffer queues.
The
vfs
subsystem attribute
buffer_hash_size
specifies the size of the hash chain table, in table entries, for
the metadata buffer cache.
Performance Benefit and Tradeoff
Increasing the size of the hash chain table distributes the buffers, which makes the average chain lengths short. This can improve lookup speeds. However, increasing the size of the hash chain table increases wired memory.
You cannot modify the
buffer_hash_size
attribute
without rebooting the system.
When to Tune
Usually, you do not have to modify the size of the hash chain table.
Recommended Values
The minimum size of the
buffer_hash_size
attribute
is 16; the maximum size is 524287.
The default value is 512.
You can modify the value of the
buffer_hash_size
attribute so that each hash chain has 3 or 4 buffers.
To determine a value
for the
buffer_hash_size
attribute, use the
dbx
print
command to examine the value of the
nbuf
kernel variable, then divide the value by 3 or 4, and finally round the result
to a power of 2.
For example, if
nbuf
has a value of 360,
dividing 360 by 3 gives you a value of 120.
Based on this calculation, specify
128 (2 to the power of 7) as the value of the
buffer_hash_size
attribute.
See
Section 3.6
for information about modifying
kernel attributes.
9.4.3.3 Increasing the UFS Smooth Sync Cache Timeout Value
Smooth sync functionality improves
UFS I/O performance by preventing I/O spikes caused by the
update
daemon, and by increasing the UBC hit rate, which decreases the
total number of disk operations.
Smooth sync also helps to efficiently distribute
I/O requests over the sync interval, which decreases the length of the disk
queue and reduces the latency that results from waiting for a busy page to
be freed.
By default, smooth sync is enabled on your system.
UFS caches asynchronous I/O requests in the dirty-block queue and in
the UBC object dirty-page list queue before they are handed to the device
driver.
With smooth sync enabled (the default), the
update daemon
will not flush buffers from the dirty page lists and dirty wired page lists.
Instead, the buffers get moved to the device queue only after the amount of
time specified by the value of the
vfs
attribute
smoothsync_age
(the default is 30 seconds).
After this time,
the buffer moves to the device queue.
If smooth sync is disabled, every 30 seconds the
update
daemon flushes data from memory to disk, regardless of how long a buffer has
been cached.
Smooth sync functionality is controlled by the
smoothsync_age
attribute.
However, you do not specify a value for
smoothsync_age
in the
/etc/sysconfigtab
file.
Instead, the
/etc/inittab
file is used to enable smooth sync when the system
boots to multiuser mode and to disable smooth sync when the system goes from
multiuser mode to single-user mode.
This procedure is necessary to reflect
the behavior of the
update
daemon, which operates only
in multiuser mode.
To enable smooth sync, the following lines must be included in the
/etc/inittab
file and the time limit for caching buffers in the
smooth sync queue must be specified (default is 30 seconds):
smsync:23:wait:/sbin/sysconfig -r vfs smoothsync_age=30 > /dev/null 2>&1 smsyncS:Ss:wait:/sbin/sysconfig -r vfs smoothsync_age=0 > /dev/null 2>&1
Performance Benefit and Tradeoff
Increasing the amount of time that an asynchronous I/O request ages
before being placed on the device queue (increasing the value of the
smoothsync_age
attribute) will increase the chance that a buffer
cache hit will occur, which improves UFS performance if the data is reused.
However, this increases the chance that data may be lost if a system crash
occurs.
Decreasing the value of the
smoothsync_age
attribute
will speed the flushing of buffers.
When to Tune
Usually, you do not have to modify the smooth sync queue timeout limit.
Recommended Values
Thirty seconds is the default smooth sync queue timeout limit.
If you
increase the value of the
smoothsync_age
attribute in the
/etc/inittab
file, you will increase the chance that a buffer cache
hit will occur.
To disable smooth sync, specify a value of 0 (zero) for the
smoothsync_age
attribute.
See
Section 3.6
for information about modifying
kernel subsystem attributes.
9.4.3.4 Delaying UFS Cluster Flushing
By default, clusters of UFS
pages are written asynchronously (the write must be completed).
Enabling the
delay_wbuffers
kernel variable causes these clusters to be written
synchronously (delayed), as other dirty data and metadata pages are written.
However, if the percentage of UBC dirty pages reaches the value of the
delay_wbuffers_percent
kernel variable, the clusters will be written
asynchronously, regardless of the setting of the
delay_wbuffers
kernel variable.
Performance Benefit and Tradeoff
Delaying full write buffer flushing can free CPU cycles. However, it may adversely affect real-time workload performance, because the system will experience a heavy I/O load at sync time.
You can modify the
delay_wbuffers
kernel variable
without rebooting the system.
When to Tune
Delay cluster flushing if your applications frequently write to previously written pages. This can result in a net decrease in the total number of I/O requests.
Recommended Values
To delay cluster flushing, use the
dbx patch
command
to set the value of the
delay_wbuffers
kernel variable
to 1 (enabled).
The default value of
delay_wbuffers
is
0 (disabled).
See
Section 3.6.7
for information on using
dbx.
9.4.3.5 Increasing the Number of Blocks Combined for Read-Ahead
You can increase the number of blocks that are combined for a read-ahead operation.
Performance Benefit and Tradeoff
Increase the number of blocks combined for read-ahead if your applications can use a large read-ahead size.
When to Tune
Usually, you do not have to increase the number of blocks combined for read-ahead.
Recommended Values
To increase the number of blocks combined for read-ahead, use the
dbx patch
command to set the value of the
cluster_consec_init
kernel variable equal to the value of the
cluster_max_read_ahead
kernel variable (the default is 8), which specifies the maximum
number of read-ahead clusters that the kernel can schedule.
In
addition, you must make sure that cluster read operations are enabled on nonread-ahead
and read-ahead blocks.
To do this, use
dbx
to set the value
of the
cluster_read_all
kernel variable to 1, which is
the default value.
See
Section 3.6.7
for information on using
dbx.
9.4.3.6 Increasing the Number of Blocks Combined for a Cluster
You
can increase the number of blocks combined for a cluster.
The
cluster_maxcontig
kernel variable specifies the number of blocks that are combined
into a single I/O operation.
Contiguous writes are done in a unit size that
is determined by the file system block size (8 KB) multiplied by the value
of the
cluster_maxcontig
parameter.
Performance Benefit and Tradeoff
Increase the number of blocks combined for a cluster if your applications can use a large cluster size.
When to Tune
Usually, you do not have to increase the number of blocks combined for a cluster.
Recommended Values
The default value of
cluster_maxcontig
kernel variable
is 8.
See
Section 3.6.7
for information about using
dbx.
9.4.3.7 Defragmenting a File System
When a file consists of noncontiguous file extents, the file is considered fragmented. A very fragmented file decreases UFS read and write performance, because it requires more I/O operations to access the file.
Performance Benefit and Tradeoff
Defragmenting a UFS file system improves file system performance. However, it is a time-consuming process.
When to Perform This Task
You can determine whether the files in a file system are fragmented
by determining how effectively the system is clustering.
You can do this by
using the
dbx print
command to examine the
ufs_clusterstats
data structure.
See
Section 9.4.2.2
for information.
UFS block clustering is usually efficient. If the numbers from the UFS clustering kernel structures show that clustering is not effective, the files in the file system may be very fragmented.
Recommended Procedure
To defragment a UFS file system, follow these steps:
Back up the file system onto tape or another partition.
Create a new file system either on the same partition or a different partition.
Restore the file system.
See the
System Administration
manual for information about backing up and
restoring data and creating UFS file systems.
9.5 Managing NFS Performance
The Network File System (NFS) shares the Unified Buffer Cache (UBC) with the virtual memory subsystem and local file systems. NFS can put an extreme load on the network. Poor NFS performance is almost always a problem with the network infrastructure. Look for high counts of retransmitted messages on the NFS clients, network I/O errors, and routers that cannot maintain the load.
Lost packets on the network can severely degrade NFS performance. Lost packets can be caused by a congested server, the corruption of packets during transmission (which can be caused by bad electrical connections, noisy environments, or noisy Ethernet interfaces), and routers that abandon forwarding attempts too quickly.
You can monitor NFS by using the
nfsstat
and other
commands.
When evaluating NFS performance, remember that NFS does not perform
well if any file-locking mechanisms are in use on an NFS file.
The locks prevent
the file from being cached on the client.
See
nfsstat(8)
for more information.
The following sections describe how to perform the following tasks:
Gather NFS performance information (Section 9.5.1)
Improving NFS performance (Section 9.5.2)
9.5.1 Gathering NFS Information
Table 9-9
describes
the commands you can use to obtain information about NFS operations.
Table 9-9: NFS Monitoring Tools
| Name | Use | Description |
Displays network and NFS statistics (Section 9.5.1.1) |
Displays NFS and RPC statistics for
clients and servers, including the number of packets that had to be retransmitted
( |
|
|
Monitors all incoming network traffic
to an NFS server and divides it into several categories, including NFS reads
and writes, NIS requests, and RPC authorizations.
Your kernel must be configured
with the
|
|
Displays information about idle threads (Section 9.5.1.2) |
Displays information about idle threads on a client system. |
|
Displays active NFS server threads (Section 3.6.7) |
Displays a histogram of the number of active NFS server threads. |
|
Displays the hit rate (Section 9.1.2) |
Displays the namei cache hit rate. |
|
Displays metadata buffer cache information (Section 9.4.2.3) |
Reports statistics on the metadata buffer cache hit rate. |
|
Reports UBC statistics (Section 6.3.4) |
Reports the UBC hit rate. |
The following sections describe how to use some of these tools.
9.5.1.1 Displaying NFS Information by Using the nfsstat Command
The
nfsstat
command displays statistical information about NFS and Remote
Procedure Call (RPC) interfaces in the kernel.
You can also use this command
to reinitialize the statistics.
An example of the
nfsstat
command is as follows:
#/usr/ucb/nfsstatServer rpc: calls badcalls nullrecv badlen xdrcall 38903 0 0 0 0 Server nfs: calls badcalls 38903 0 Server nfs V2: null getattr setattr root lookup readlink read 5 0% 3345 8% 61 0% 0 0% 5902 15% 250 0% 1497 3% wrcache write create remove rename link symlink 0 0% 1400 3% 549 1% 1049 2% 352 0% 250 0% 250 0% mkdir rmdir readdir statfs 171 0% 172 0% 689 1% 1751 4% Server nfs V3: null getattr setattr lookup access readlink read 0 0% 1333 3% 1019 2% 5196 13% 238 0% 400 1% 2816 7% write create mkdir symlink mknod remove rmdir 2560 6% 752 1% 140 0% 400 1% 0 0% 1352 3% 140 0% rename link readdir readdir+ fsstat fsinfo pathconf 200 0% 200 0% 936 2% 0 0% 3504 9% 3 0% 0 0% commit 21 0% Client rpc: calls badcalls retrans badxid timeout wait newcred 27989 1 0 0 1 0 0 badverfs timers 0 4 Client nfs: calls badcalls nclget nclsleep 27988 0 27988 0 Client nfs V2: null getattr setattr root lookup readlink read 0 0% 3414 12% 61 0% 0 0% 5973 21% 257 0% 1503 5% wrcache write create remove rename link symlink 0 0% 1400 5% 549 1% 1049 3% 352 1% 250 0% 250 0% mkdir rmdir readdir statfs 171 0% 171 0% 713 2% 1756 6% Client nfs V3: null getattr setattr lookup access readlink read 0 0% 666 2% 9 0% 2598 9% 137 0% 200 0% 1408 5% write create mkdir symlink mknod remove rmdir 1280 4% 376 1% 70 0% 200 0% 0 0% 676 2% 70 0% rename link readdir readdir+ fsstat fsinfo pathconf 100 0% 100 0% 468 1% 0 0% 1750 6% 1 0% 0 0% commit 10 0%#
The ratio of timeouts to calls (which should not exceed 1 percent) is the most important thing to look for in the NFS statistics. A timeout-to-call ratio greater than 1 percent can have a significant negative impact on performance. See Chapter 10 for information on how to tune your system to avoid timeouts.
Use the
nfsstat -s -i 10
command to display NFS and
RPC information at ten-second intervals.
If you are attempting to monitor an experimental situation with
nfsstat, reset the NFS counters to 0 before you begin the experiment.
Use the
nfsstat -z
command to clear the counters.
See
nfsstat(8)
for more information about command options and
output.
9.5.1.2 Displaying Idle Thread Information by Using the ps Command
On a client system, the
nfsiod
daemon spawns
several I/O threads to service asynchronous I/O requests to the server.
The
I/O threads improve the performance of both NFS reads and writes.
The optimum
number of I/O threads depends on many variables, such as how quickly the client
will be writing, how many files will be accessed simultaneously, and the characteristics
of the NFS server.
For most clients, seven threads are sufficient.
The following example uses the
ps axlmp
command to
display idle I/O threads on a client system:
#/usr/ucb/ps axlmp 0 | grep nfs0 42 0 nfsiod_ S 0:00.52 0 42 0 nfsiod_ S 0:01.18 0 42 0 nfsiod_ S 0:00.36 0 44 0 nfsiod_ S 0:00.87 0 42 0 nfsiod_ S 0:00.52 0 42 0 nfsiod_ S 0:00.45 0 42 0 nfsiod_ S 0:00.74#
The previous output shows a sufficient number of sleeping threads and
42 server threads that were started by
nfsd, where
nfsiod_
has been replaced by
nfs_tcp
or
nfs_udp.
If your output shows that few threads are sleeping, you may be able
to improve NFS performance by increasing the number of threads.
See
Section 9.5.2.2,
Section 9.5.2.3,
nfsiod(8), and
nfsd(8)
for more information.
9.5.2 Improving NFS Performance
Improving performance on a system that is used only for serving NFS differs from tuning a system that is used for general timesharing, because an NFS server runs only a few small user-level programs, which consume few system resources. There is minimal paging and swapping activity, so memory resources should be focused on caching file system data.
File system tuning is important for NFS because processing NFS requests consumes the majority of CPU and wall clock time. Ideally, the UBC hit rate should be high. Increasing the UBC hit rate can require additional memory or a reduction in the size of other file system caches. In general, file system tuning will improve the performance of I/O-intensive user applications.
In addition, a vnode must exist to keep file data in the UBC. If you are using AdvFS, an access structure is also required to keep file data in the UBC.
If you are running NFS over TCP, tuning TCP may improve performance if there are many active clients. See Section 10.2 for more information. However, if you are running NFS over UDP, no network tuning is needed.
Table 9-10
lists NFS tuning and performance-improvement
guidelines and the benefits as well as tradeoffs.
Table 9-10: NFS Performance Guidelines
| Guideline | Performance Benefit | Tradeoff |
Set the value of the
maxusers
attribute to the number of server NFS operations that are expected to occur
each second (Section 5.1) |
Provides the appropriate level of system resources | Consumes memory |
| Increase the size of the namei cache (Section 9.2.1) | Improves file system performance | Consumes memory |
| Increase the number of AdvFS access structures, if you are using AdvFS (Section 9.3.6.3) | Improves AdvFS performance | Consumes memory |
| Increase the size of the metadata buffer cache, if you are using UFS (Section 9.4.3.1) | Improves UFS performance | Consumes wired memory |
| Use Prestoserve (Section 9.5.2.1) | Improves synchronous write performance for NFS servers | Cost |
| Configure the appropriate number of threads on an NFS server (Section 9.5.2.2) | Enables efficient I/O blocking operations | None |
| Configure the appropriate number of threads on the client system (Section 9.5.2.3) | Enables efficient I/O blocking operations | None |
| Modify cache timeout limits on the client system (Section 9.5.2.4) | May improve network performance for read-only file systems and enable clients to quickly detect changes | Increases network traffic to server |
| Decrease network timeouts on the client system (Section 9.5.2.5) | May improve performance for slow or congested networks | Reduces the theoretical performance |
| Use NFS Protocol Version 3 on the client system (Section 9.5.2.6) | Improves network performance | Decreases the performance benefit of Prestoserve |
The following sections describe some of these guidelines.
9.5.2.1 Using Prestoserve to Improve NFS Server Performance
You can improve NFS performance by installing Prestoserve on the server. Prestoserve greatly improves synchronous write performance for servers that are using NFS Version 2. Prestoserve enables an NFS Version 2 server to write client data to a nonvolatile (battery-backed) cache, instead of writing the data to disk.
Prestoserve may improve write performance for NFS Version 3 servers, but not as much as with NFS Version 2, because NFS Version 3 servers can reliably write data to volatile storage without risking loss of data in the event of failure. NFS Version 3 clients can detect server failures and resend any write data that the server may have lost in volatile storage.
See the
Guide to Prestoserve
for more information.
9.5.2.2 Configuring Server Threads
The
nfsd
daemon runs on NFS servers to service NFS requests from client
machines.
The daemon spawns a number of server threads that process NFS requests
from client machines.
At least one server thread must be running for a machine
to operate as a server.
The number of threads determines the number of parallel
operations and must be a multiple of 8.
To improve performance on frequently used NFS servers, configure either
16 or 32 threads, which provides the most efficient blocking for I/O operations.
See
nfsd(8)
for more information.
9.5.2.3 Configuring Client Threads
Client systems
use the
nfsiod
daemon to service asynchronous I/O operations,
such as buffer cache read-ahead and delayed write operations.
The
nfsiod
daemon spawns several I/O threads to service asynchronous
I/O requests to its server.
The I/O threads improve performance of both NFS
reads and writes.
The optimal number of I/O threads to run depends on many variables, such as how quickly the client is writing data, how many files will be accessed simultaneously, and the behavior of the NFS server. The number of threads must be a multiple of 8 minus 1 (for example, 7 or 15 is optimal).
NFS servers attempt to gather writes into complete UFS clusters
before initiating I/O, and the number of threads (plus 1) is the number of
writes that a client can have outstanding at any one time.
Having exactly
7 or 15 threads produces the most efficient blocking for I/O operations.
If
write gathering is enabled, and the client does not have any threads, you
may experience a performance degradation.
To disable write gathering, use
the
dbx patch
command to set the
nfs_write_gather
kernel variable to zero.
See
Section 3.6.7
for information.
Use the
ps axlmp 0 | grep nfs
command to display
idle I/O threads on the client.
If few threads are sleeping, you may be able
to improve NFS performance by increasing the number of threads.
See
nfsiod(8)
for more information.
9.5.2.4 Modifying Cache Timeout Limits
For read-only file systems and slow network links, performance may be improved by changing the cache timeout limits on NFS client systems. These timeouts affect how quickly you see updates to a file or directory that has been modified by another host. If you are not sharing files with users on other hosts, including the server system, increasing these values will slightly improve performance and will reduce the amount of network traffic that you generate.
See
mount(8)
and the descriptions of the
acregmin,
acregmax,
acdirmin,
acdirmax,
actimeo
options for more information.
9.5.2.5 Decreasing Network Timeouts
NFS does not perform well if it is used over slow network links,
congested networks, or wide area networks (WANs).
In particular, network timeouts
on client systems can severely degrade NFS performance.
This condition can
be identified by using the
nfsstat
command and determining
the ratio of timeouts to calls.
If timeouts are more than 1 percent of the
total calls, NFS performance may be severely degraded.
See
Section 9.5.1.1
for sample
nfsstat
output of timeout and call statistics.
You can also use the
netstat -s
command to verify
the existence of a timeout problem.
A nonzero value in the
fragments
dropped after timeout
field in the
ip
section
of the
netstat
output may indicate that the problem exists.
See
Section 10.1.1
for sample
netstat
command output.
If fragment drops are a problem on a client system, use the
mount
command with the
-rsize=1024
and
-wsize=1024
options to set the size of the NFS read and write buffers
to 1 KB.
9.5.2.6 Using NFS Protocol Version 3
NFS Protocol Version 3 provides NFS client-side asynchronous write support, which improves the cache consistency protocol and requires less network load than Version 2. These performance improvements slightly decrease the performance benefit that Prestoserve provided for NFS Version 2. However, with Protocol Version 3, Prestoserve still speeds file creation and deletion.