Businesses want a computing environment that is dependable and able to handle the workload placed on that environment. Users and applications place different demands on a system, and both require consistent performance with minimal down time. A system also must be able to absorb an increase in workload without a decline in performance. By following the guidelines in this manual, you can configure and tune a dependable, high-performance system that will meet your current and future computing needs.
This chapter introduces you to the process of configuring a system and includes information about the following topics:
Common terms related to performance and availability (Section 1.1)
How to obtain high availability and high performance (Section 1.2 and Section 1.3)
How to plan your configuration (Section 1.4)
Configuration and tuning recommendations (Section 1.5)
The steps to configure and tune systems (Section 1.6)
Later chapters provide detailed information about monitoring systems, identifying performance problems, optimizing applications and the central processing unit (CPU), and configuring and tuning the virtual memory, storage, and network subsystems.
This section introduces the terms and concepts that are used to describe performance and availability.
Your system configuration consists of a combination of hardware and software for a single system or a cluster of systems. For example, CPUs, memory boards, the operating system, and mirrored disks are parts of a configuration. To configure a system, you need to set up a new or modify an existing hardware or software configuration. For example, configuring the I/O subsystem can include setting up mirrored disks.
Systems can be single-CPU systems or multiprocessor systems, which allow two or more processors to share common physical memory. An example of a multiprocessing system is a symmetrical multiprocessing (SMP) system, in which the CPUs execute the same version of the operating system, access common memory, and execute instructions simultaneously.
Certain types of environments, such as large database environments, require multiprocessing systems and large storage configurations to handle the workload. Very-large memory (VLM) systems utilize 64-bit architecture, multiprocessing, and at least 2 GB of memory. Very-large database (VLDB) systems are VLM systems that also use a large and complex storage configuration. The following list describes the components of a typical VLM/VLDB configuration:
An SMP system with two or more high-speed CPUs
More than 4 GB of physical memory
Multiple high-performance host bus adapters
RAID storage configuration for high performance and high availability
The virtual memory subsystem controls the allocation of memory to processes by using a portion of physical memory, disk swap space, and various daemons and algorithms. A page is the smallest portion of physical memory that the system can allocate (8 KB of memory). Virtual memory operation involves paging, reclaiming pages so they can be reused, and swapping, writing a suspended process' modified (dirty) pages to swap space, which frees large amounts of memory.
After a system is configured, you may want to tune the system to improve performance. You can tune a system by changing the values of kernel variables in order to modify the kernel. Kernel variables affect the behavior and performance of the kernel, the virtual memory subsystem, the I/O subsystems, and applications. You can temporarily modify the kernel by changing the kernel variables while the system is running, or you can permanently modify the kernel by changing the values of attributes.
Use attributes to modify the kernel without rebuilding the kernel. In some cases, you can modify the kernel by changing parameter values in the system configuration file; however, you must rebuild the kernel to use the new parameter values. See Section 2.11 for information about viewing and modifying kernel variables, attributes, and parameters.
If tuning a system does not sufficiently improve performance, you may have to reconfigure your system, which can involve adding CPUs or memory, changing the storage configuration, or modifying the software application.
System performance depends on an efficient utilization of system resources, which are the hardware and software components (CPUs, memory, networks, and disk storage) that are available to users or applications. A system must perform well under the normal workload exerted on the system by the applications and the users.
The system workload changes over time. You may add users or run additional applications. You may need to reconfigure your system to handle an increasing workload. Scalability refers to a system's ability to utilize additional resources with a predictable increase in performance, or the ability to absorb an increase in workload without a significant performance degradation.
A performance problem in a specific area of the configuration is called a bottleneck. Potential bottlenecks include the virtual memory subsystem and I/O buses. A bottleneck can occur if the workload demands more from a resource than its capacity, which is the maximum theoretical throughput of a system resource.
Performance is often described in terms of two rates. Bandwidth is the rate at which an I/O subsystem or component can transfer bytes of data. Bandwidth is often called the transfer rate. Bandwidth is especially important for applications that perform large sequential data transfers. Throughput is the rate at which an I/O subsystem or component can perform I/O operations. Throughput is especially important for applications that perform many small I/O operations.
Performance is also measured in terms of latency, which is the amount of time to complete a specific operation. Latency is often called delay. High system performance requires a low latency time. I/O latency is measured in milliseconds; memory latency is measured in nanoseconds. Memory latency depends on the memory bank configuration and the system's memory requirements.
Disk performance is often described in terms of disk access time, which is a combination of the seek time, the amount of time for a disk head to move to a specific disk track, and the rotational latency, which is the amount of time for a disk to rotate to a specific disk sector.
The Unified Buffer Cache (UBC) affects disk I/O performance. The UBC is allocated a portion of physical memory to cache most-recently accessed file system data. By functioning as a layer between the operating system and the storage subsystem, the UBC is able to decrease the number of disk operations.
Disk I/O performance also depends on the characteristics of the workload's I/O operations. Data transfers can be large or small and can involve reading data from a disk or writing data to a disk.
Data transfers also have different access patterns. A sequential access pattern is an access pattern in which data is read from or written to contiguous (adjacent) blocks on a disk. A random access pattern is an access pattern in which data is read from or written to blocks in different (usually nonadjacent) locations on a disk.
In addition, data transfers can consist of file-system data or raw I/O, which is I/O to a disk or disk partition that does not contain a file system. Raw I/O bypasses buffers and caches, and it may provide better performance than file system I/O. Raw I/O is often used by the operating system and by database application software.
Disk I/O performance also is affected by the use of redundant array of independent disks (RAID) technology, which can provide both high disk I/O performance and high data availability. The DIGITAL UNIX operating system provides RAID functionality by using the Logical Storage Manager (LSM) software. DIGITAL UNIX also supports hardware-based RAID products, which provide RAID functionality by using intelligent controllers, caches, and software.
There are four primary RAID levels:
RAID 0--Also known as disk striping, RAID 0 divides data into blocks and distributes the blocks across multiple disks in a array. Distributing the disk I/O load across disks and controllers improves disk I/O performance.
RAID 1--Also known as disk mirroring, RAID 1 maintains identical copies of data on different disks in an array. Duplicating data on different disks provides high data availability and improves disk read performance.
RAID 3--A type of parity RAID, RAID 3 divides data blocks and distributes (stripes) the data across a disk array, providing parallel access to data and increasing bandwidth. RAID 3 also provides high data availability by placing redundant parity information on a separate disk, which is used to regenerate data if a disk in the array fails.
RAID 5--A type of parity RAID, RAID 5 distributes data blocks across disks in an array. RAID 5 allows independent access to data and can handle simultaneous I/O operations, which improves throughput. RAID 5 provides data availability by distributing redundant parity information across the array of disks.
To address your performance and availability needs, you can combine some RAID levels (for example, you can combine RAID 1 with RAID 0 to mirror striped disks). Some hardware-based RAID products support adaptive RAID 3/5 (also called dynamic parity RAID), which improves disk I/O performance for a wide variety of applications by dynamically adjusting, according to workload needs, between data transfer-intensive algorithms and I/O operation-intensive algorithms.
See Section 5.2.1 for more information about RAID and RAID products.
High availability is the ability of a resource to withstand a hardware or software failure. Resources (for example, systems or disk data) can be made highly available by using some form of resource duplication or redundancy.
For example, you can make the data on a disk highly available by mirroring that disk; that is, replicating the data on a different disk. If the original disk fails, the copy is still available to users and applications. If you use parity RAID, the redundant data is stored in the parity information, which is used to regenerate data if a disk failure occurs.
In addition, you can make the network highly available by using redundant network connections. If one connection becomes unavailable, you can still use the other connection for network access. Network availability depends on the application, the network configuration, and the network protocol.
To make a system highly available, you must set up a cluster, which is a loosely coupled group of servers configured as cluster member systems. In a cluster, software applications are capable of running on any member system. Some applications can run on only one member system at a time; others can run on multiple systems simultaneously. Cluster member systems usually share highly available disk data, and some clusters support a high-performance interconnect that enables fast and reliable communications between members.
A cluster utilizes failover to ensure application and system availability. If a member system fails, all cluster-configured applications running on that system fail over to a different member system, which restarts the applications and makes them available to users.
To completely protect a configuration from failure, you must eliminate each point of failure. An example of a configuration that has no single point of failure is as follows:
A cluster to protect against a system failure
Two network connections to protect against a network failure
Disks mirrored across different buses to protect against a disk, bus, or adapter failure
For increased availability, you can use multiple layers of redundancy to protect against multiple failures. See Section 1.2 for more information about availability.
Availability is also measured by a resource's reliability, which is the average amount of time that a component will perform before a failure that causes a loss of data. It is often expressed as the mean time to data loss (MTDL), the mean time to first failure (MTTF), and the mean time between failures (MTBF).
A resource that is highly available is resistant to specific hardware and software failures. This is accomplished by duplicating resources (for example, systems, network interfaces, or data), and may also include an automatic failover mechanism that makes the resource failure virtually imperceptible to users.
There are various degrees of high availability, and you must determine how much you need for your environment. A configuration that has no single point of failure is one in which you have duplicated each vital resource. Environments that are not prone to failure or are able to accommodate down time may only require data to be highly available.
Figure 1-1 shows a configuration that is vulnerable to multiple failures, including system, network, disk, and bus failures.
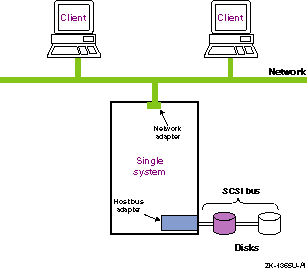
The more levels of resource redundancy, the greater the resource availability. Mission-critical operations and production environments often require that resources be resistant to multiple failures. For example, if you have only two cluster member systems and one fails, you now have a potential point of failure (the remaining system), and your configuration is vulnerable to down time. Therefore, a cluster with three or more member systems has more levels of redundancy and higher availability than a two-system cluster, because it can survive multiple system failures.
However, it is not always possible or practical to protect against every possible failure scenario or to provide multiple levels of redundancy. When planning your configuration, you must determine how much availability you need and the best way to achieve it.
Software-based RAID (LSM) and hardware-based RAID products provide you with various degrees of data availability. In addition, specific configurations can improve data availability. For example, mirroring data across buses protects against disk, bus, and adapter failures.
DIGITAL UNIX TruCluster TM products provide high system and application availability. Brief descriptions of some cluster products are as follows:
TruCluster Available Server Software
Allows you to set up an available server environment (ASE), which consists of systems and disk and tape devices that are connected to shared SCSI buses. Together they provide highly available software and data to client systems. An ASE uses failover to significantly reduce down time due to hardware and software failures.
TruCluster Production Server Software
Provides you with high performance and highly available access to applications and data in a network environment. Production Server significantly reduces down time caused by hardware and software failures, and provides scalability beyond the limits of a single system. A Production Server configuration is similar to an ASE, but it also uses a PCI-based cluster interconnect that enables fast and reliable communications between cluster members.
The following sections describe how to eliminate points of failure, and how to increase resource availability.
When configuring a system for high availability, you must protect the system's resources from failure. The following list describes each potential point of failure and how to eliminate it:
System failure
If users and applications depend on the availability of a single system for CPU, memory, data, and network resources, they will experience down time if a hardware or software failure occurs (for example, a system crashes or an application fails). To obtain protection against a failure on a single system, you must set up a cluster with at least two member systems. If a failure occurs on one member system, the cluster-configured applications running on that system fail over to another member system, which then runs the applications.
However, a two-member cluster is no longer a highly available configuration if one member fails, because the remaining member is now a potential point of failure. To protect against multiple system failures, you must set up a cluster with more than two member systems.
Disk failure
To protect against disk failure, mirror disks or use parity RAID.
Host bus adapter or bus failure
To protect data against a host bus adapter or bus failure, mirror the data across disks located on different buses.
Network connection failure
Network connections may fail because of a failed network interface or a problem in the network itself. To maintain network access if a network connection fails, install more than one network interface in a system and make sure that your applications support this functionality.
Power failure
Systems and storage units are vulnerable to power failures. To protect against a power supply failure, use redundant power supplies from different power sources. You can also protect disks against a power supply failure in a storage cabinet by mirroring the disks across independently powered cabinets.
Use an uninterruptible power system (UPS) to protect against a total power failure (for example, the power in a building fails). A UPS depends on a viable battery source and monitoring software.
Cluster interconnect failure
If a cluster supports high-performance cluster interconnects, you can connect each member system to redundant (two) interconnects. If one cluster interconnect fails, the cluster members can still communicate over the remaining interconnect.
Figure 1-2 shows a fully redundant cluster configuration with no single point of failure for the server systems.
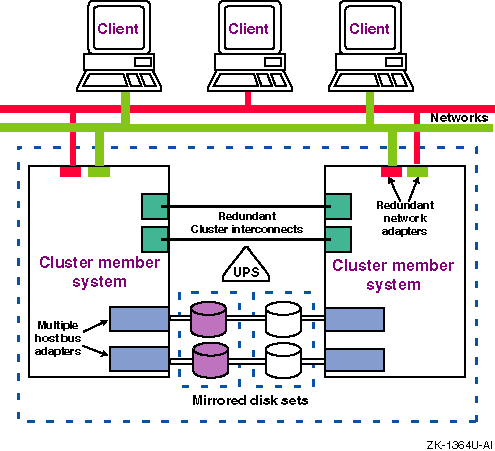
Because you can never eliminate the possibility that multiple failures will make a resource or component unavailable, you must repair or replace a failed component as soon as possible to maintain some form of redundancy. This will help to ensure that you do not experience down time.
You must decide how much system availability you need and where a system is most vulnerable to failure. Table 1-1 describes how to increase the system availability by eliminating single points of failure, as well as the tradeoffs.
| To protect against: | You can: | Tradeoff: |
| Single system failure | Set up a cluster with at least two members | Cost of additional hardware and software, increased management complexity |
| Use the lastest versions of hardware, firmware, and operating system | Possible down time during upgrade | |
| Multiple system failures | Set up a cluster with more than two members | Cost of additional hardware and software, increased management complexity |
| Network connection failure | Configure multiple network connections | Cost of additional hardware, requires I/O slots |
| Cluster interconnect failure | Set up a second cluster interconnect | Cost of additional hardware, uses a PCI slot |
| Total power failure | Use a battery-backed uninterruptible power system (UPS) | Cost of UPS hardware |
| Cabinet power supply failure | Use redundant power supplies or mirror disks across cabinets with independent power supplies | Cost of additional hardware and decrease in write performance on mirrored disks |
Not only is it important for users and applications to be able to access data easily and quickly, data needs to be available. Table 1-2 describes how to increase the availability of data by addressing points of failure, as well as the tradeoffs.
| To protect against: | You can: | Tradeoff: |
| Disk failure | Mirror disks | Cost of additional disks and decrease in write performance |
| Use parity RAID | Cost of additional hardware and software, increase in management complexity, and performance impact under write loads | |
| Host bus adapter or bus failure | Mirror data across disks on different buses | Cost of additional hardware and requires additional I/O bus slots |
| System failure | Set up a cluster | Cost of additional hardware and software, increase in management complexity |
| Total power failure | Use a battery-backed uninterruptible power system (UPS) | Cost of UPS hardware |
| Cabinet power supply failure | Use redundant power supplies or mirror disks across cabinets with independent power supplies | Cost of additional hardware and decrease in write performance on mirrored disks |
Configuring a system for high availability can affect performance, depending on your configuration and the characteristics of your workload. Table 1-3 shows how high-availability solutions affect system performance.
| Availability Solution | Performance Impact |
| Mirroring disks | Can improve disk read performance, but may cause a degradation in write performance (you can mirror striped disks to combine the performance benefits of striping with high availability) |
| Mirroring disks across different buses | Prevents a single bus from becoming an I/O bottleneck |
| Parity RAID | Improves disk I/O performance only if all member disks are available; performance degrades as disks fail |
| Redundant network connections | Improves network performance and increases client access |
| Cluster | Improves overall performance by spreading workload across member systems, which provides applications and users with more CPU and memory resources |
A system must have a dependable level of performance to meet the needs of users and applications. You must configure your system so that it can rapidly respond to the demands of a normal workload and maintain an adequate level of performance if the workload increases.
Some environments require that a system be scalable. A scalable system allows you to add hardware (for example, CPUs) to improve performance or to absorb an increase in the workload.
You must understand the characteristics of your workload to determine the level of performance you require, and which configuration will meet your performance needs. Although some environments require the highest possible performance, this level of performance may not be necessary or cost effective.
System performance depends on the interaction between the hardware and software configuration and the workload. A system that performs well must use CPU, memory, and I/O resources efficiently. If a resource reaches its capacity, it becomes a bottleneck and can degrade performance. Bottlenecks are often interrelated; for example, insufficient memory can cause excessive paging and swapping, which may result in a bottleneck in the disk I/O subsystem.
To plan a configuration that will meet your performance needs, you must identify which resources will have the biggest impact on performance. For example, if your applications are CPU-intensive, you may want to consider a system with multiple CPUs and sufficient memory bandwidth. If the applications require a lot of memory, you must configure sufficient memory for the system. An inadequate amount of memory will degrade the overall system performance.
If your applications perform a large number of disk I/O operations, configure your storage subsystem to prevent disk and bus bottlenecks. If your system is an Internet server, you must be sure it can handle many network requests. In addition, if you require both high availability and high performance, you must determine how a high-availability configuration impacts system performance.
After you plan and set up your configuration, you may be able to improve performance by tuning the system. However, tuning may provide only marginal performance improvements, so make sure that your configuration is appropriate for your workload.
Performance problems can have various sources, including the following:
Incorrect values for kernel variables
Depending on your configuration and workload, you may need to modify some kernel variable values to obtain optimal performance.
Incorrect configuration for the workload
If tuning the system does not improve performance, your configuration may not be suitable for your workload. In addition, your resources may be inadequate for the workload. For example, you may need to increase your CPU or memory resources, upgrade to high-performance hardware, or add disks.
Fragmented disks
Disk fragmentation, in which file data is not contiguously located on a disk, can degrade read and write performance because multiple I/O operations are required to access a file.
Poorly written or nonoptimized applications
If an application is the source of a performance problem, you must rewrite or optimize the application.
The commands described in Chapter 2 can help you identify the source of a performance problem.
To plan your DIGITAL UNIX configuration, follow these steps:
Understand your workload and the characteristics of the users and applications.
Determine your performance and availability requirements.
Choose which hardware and software configuration will satisfy your performance and availability needs.
The following sections describe these steps in detail.
Before choosing a configuration to meet your needs, you must determine the impact of your workload on the system. To do this, you must understand the characteristics of your applications and users and how they utilize the software and hardware (for example, how they perform disk I/O).
Use Table 1-4 to help you understand application behavior. You may want to duplicate and fill out this table for each application.
| Application Name: | |
| Describe the application objectives. | |
| Describe the performance requirements. | |
| Is the application CPU-intensive? | |
| What are the application's memory needs? | |
| How much disk storage does the application require? | |
| Does the application require high bandwidth or throughput? | |
| Does the application perform large sequential data transfers? | |
| Does the application perform many small data transfers? | |
| What is the size of the average data transfer? | |
| What percentage of the data transfers are reads? | |
| What percentage of the data transfers are writes? | |
| Does the application perform many network operations? | |
| What are your system availability requirements? | |
| What are your data availability requirements? | |
| What are your network availability requirements? |
Use Table 1-5 to help you understand user behavior. Different users may place different demands on the system. For example, some users may be performing data processing, while others may be compiling code. You may want to duplicate and fill out this table for each type of user.
| User Type: | |
| Describe the type of user. | |
| Specify the number of users. | |
| Describe the objectives of the users. | |
| Describe the tasks that the users perform. | |
| List the applications run by the users. | |
| What are the data storage requirements for the users? |
After you understand how your applications and users use the hardware and software, you can determine the performance and availability goals for your environment.
Before you configure a system, you must determine the goals for the environment in terms of the following criteria:
Performance
You must determine an acceptable level of performance for the applications and users. For example, may want a real-time environment that responds immediately to user input, or you may want an environment that has high throughput.
Availability
You must determine how much availability is needed. Some environments require only highly available data. Other environments require you to eliminate all single points of failure.
Cost
You must determine the cost limitations for the environment. For example, solid-state disks provide high throughput and high bandwidth, but at a high cost.
Scalability
You must determine how future expansion will affect performance. Be sure to include in your plans any potential workload increases and, if necessary, choose a configuration that is scalable or can absorb an increase in workload.
After you determine the goals for your environment, you can choose the configuration that will meet the needs of the applications and users and address your environment goals.
After you understand the needs of your applications and users and determine your performance and availability goals, choose the hardware and software configuration that meets your needs.
You must choose a system that will provide the necessary CPU and memory resources, and that will support your network and storage configuration. Because systems have different characteristics and features, the type of system you choose determines whether you can install additional CPU or memory boards, connect multiple I/O buses, or use the system in a cluster. Systems also vary in their scalability, which will determine whether you can improve system performance by adding resources, such as CPUs.
A primary consideration for choosing a system is its CPU and memory capabilities. Some systems support multiple CPUs. Another consideration is the number of I/O bus slots in the system.
For detailed information about features for systems, network adapters, host bus adapters, RAID controllers, and disks, see the DIGITAL Systems & Options Catalog. For information about operating system hardware support, see the DIGITAL UNIX Software Product Description.
When choosing a system that will meet your needs, you must determine your requirements for the following hardware and functionality:
Number and speed of CPUs
Only certain types of systems support multiprocessing. If your environment is CPU-intensive or if your applications can benefit from multiprocessing, you may want a system that supports multiple CPUs.
Depending on the type of multiprocessing system, you can install two or more CPUs. You must determine the number of CPUs that you need, and then choose a system that supports that number of CPUs and has enough backplane slots available for the CPU boards.
CPUs have different processing speeds. If your environment is CPU-intensive, you may want to choose a system that supports CPUs with fast speeds. CPUs also have different sizes for on-chip caches, which provide high performance. Some systems have secondary caches that reside on the main processor board and some have tertiary caches.
See Chapter 3 for information about CPU configuration.
Amount of memory and the number of memory boards
You must determine the total amount of memory that you need to handle your workload. Insufficient memory resources will cause performance problems. In addition, your memory bank configuration will affect performance. You must choose a system that provides the necessary amount of memory.
See Chapter 4 for information about memory requirements and configuration.
Cluster support
There are various cluster products that can provide you with high system availability. However, you can use only specific systems, adapters, controllers, and disks with the cluster products.
In addition, some cluster products use high-performance cluster interconnects that are connected to PCI bus slots. You must ensure that a cluster system has enough PCI slots for the cluster interconnects.
See a specific cluster product's Software Product Description for information about the systems and other hardware that can be used with that product.
Number and type of network adapters
Systems support a variety of network adapters that you use to connect to a network. Adapters have different performance features. In addition, you can use multiple network connections to improve network availability. You must choose a system that supports the network adapters that you require, and that has enough I/O slots available for the adapters.
See Chapter 6 and the Network Administration manual for information about network configuration.
Number and type of host bus adapters
Systems use buses to communicate with devices. Host bus adapters are used to communicate between buses. Host bus adapters are installed in I/O bus slots, so you must choose a system that has enough I/O slots available for the adapters.
See Chapter 5 for information about storage configurations.
Number and type of RAID controllers
You can connect only a limited number of devices to a SCSI bus. The SCSI-2 specification allows 8 devices on each SCSI bus, and the SCSI-3 specification allows 16 devices on a bus. A RAID controller allows you to increase the number of SCSI buses that can be accessed through a single I/O bus slot.
Some RAID controllers are installed directly in I/O bus slots, while others are connected to systems through a host bus adapter installed in an I/O bus slot. You must choose a system that supports RAID controllers and has a sufficient number of I/O bus slots available for the controllers.
See Chapter 5 for information about hardware RAID configurations.
Table 1-6 can help you identify the characteristics of a system that will meet your needs.
| If you require: | You need a system that: |
| Multiprocessing support | Supports multiprocessing and the number of CPUs that you want. |
| Fast processing time | Supports CPUs with fast speeds and fast memory. |
| Additional memory boards | Has backplane slots available for memory boards. |
| Cluster support | Supports the cluster product that you want to use. |
| Network adapters | Supports the network adapters that you want to use, and has an I/O slot available for each adapter. |
| Host bus adapters | Supports the host bus adapters that you want to use, and has an I/O slot available for each adapter. |
| RAID controllers | Supports the RAID controllers that you want to use, and has an I/O bus slot available for each controller. |
| Cluster interconnects | Has a PCI slot available for each interconnect. |
Fill in the requirements listed in Table 1-7 to get a profile of the system that will meet your needs.
| Feature: | Requirement: |
| Number of CPU boards: | |
| CPU processing speed: | |
| Total amount of memory: | |
| Number of memory boards: | |
| Cluster support: | |
| Type and number of network adapters: | |
| Type and number of host bus adapters: | |
| Type and number of backplane RAID controllers: | |
| Number of cluster interconnects: |
This manual describes many configuration and tuning tasks that you can use to improve system performance. Some of the recommendations can greatly improve performance. However, many of the recommendations provide only marginal improvement and should be used with caution.
To help you configure and tune your system,
there are recommendations to follow that will provide you with the best
performance improvement for most configurations.
Many of these recommendations
are used by the
sys_check
utility, which gathers
performance information and outputs this information in an easy-to-read
format.
The
sys_check
utility uses some
of the tools described in
Chapter 2
to check your
configuration and
kernel variable settings and provides warnings and tuning recommendations
if necessary.
To obtain the
sys_check
utility, access
the following location or call your customer service representative:
ftp://ftp.digital.com/pub/DEC/IAS/sys_check
The following list describes the primary tuning recommendations. If these recommendations do not solve your performance problem, use the other recommendations described in this manual.
Operating system and kernel recommendations
Ensure that you are using the latest patches for the operating system. Examine the system startup messages or use the DECevent utility to show the operating system revision.
Ensure that you are using the latest firmware for your system, adapters, controllers, and disks. Examine the system startup messages or use the DECevent utility to show firmware revisions.
Ensure that important applications have high priority.
Use
the
nice
command or the Class Scheduler to assign CPU
priorities.
See
Chapter 3.
Apply any kernel variable modifications that are recommended for your type of configuration (for example, an Internet server). See Appendix A.
Ensure that you have sufficient memory for your configuration. See Section 4.6.1.
Ensure that your system has sufficient swap space and distribute swap space across different disks and buses. See Section 4.6.2.
Increase the address space available to processes. See Section 4.7.3.
Increase the system resources available to processes. See Section 4.7.4, Section 4.7.5, Section 4.7.6, Section 4.7.7, Section 4.7.8 and Section 5.3.3.1.
Reduce application memory requirements. See Section 4.7.10.
If your system does few disk I/O operations, reduce the amount of memory allocated to the Unified Buffer Cache (UBC). See Section 4.8.
Modify the rate of swapping. See Section 4.7.12.
Modify the rate of dirty page prewriting. See Section 4.7.13.
General disk and I/O recommendations
Use high-performance hardware. See Section 5.3.1.
Distribute disk I/O and file systems across different disks and multiple buses. See Section 5.3.2.2 and and Section 5.3.2.3. You can distribute disk and file system I/O by striping data across multiple disks. See Section 5.2.1.
Defragment file systems. See Section 5.6.2.2 and Section 5.7.2.1.
If your applications are disk I/O-intensive, increase the amount of memory allocated to the UBC. See Section 5.3.3.4.
Increase the maximum number of open files. See Section 5.3.3.1.
Increase the size of the namei cache. See Section 5.3.3.2.
Advanced File System (AdvFS) recommendations
Use multiple-volume file domains. See Section 5.6.1.1.
Increase the amount of memory allocated to the AdvFS buffer cache. See Section 5.6.2.1.
Increase the dirty data caching threshold. See Section 5.6.2.3.
Decrease the I/O transfer read-ahead size. See Section 5.6.2.4.
Disable the flushing of dirty pages mapped with the
mmap
function during a
sync
call.
See
Section 5.6.2.5.
Modify the AdvFS device queue limit. See Section 5.6.2.6.
UNIX File System (UFS) recommendations
Modify the file system fragment size. See Section 5.7.1.1.
Increase the size of metadata buffer cache. See Section 4.9.1.
Delay flushing full write buffers to disk. See Section 5.7.2.2.
Network recommendations (Internet servers)
Increase the size of the hash table that the kernel uses to look up TCP control blocks. See Section 6.1.1.
Increase the limits for partial TCP connections on the socket listen queue. See Section 6.1.2.
Increase the maximum number of concurrent nonreserved, dynamically allocated ports. See Section 6.1.3.
Enable TCP keepalive functionality. See Section 6.1.4.
Network File System (NFS) recommendations
Ensure that you have a sufficient number of
nfsd
daemons running on the server.
See
Section 6.2.2.
Ensure that you have a sufficient number of
nfsiod
daemons running on the client.
See
Section 6.2.3.
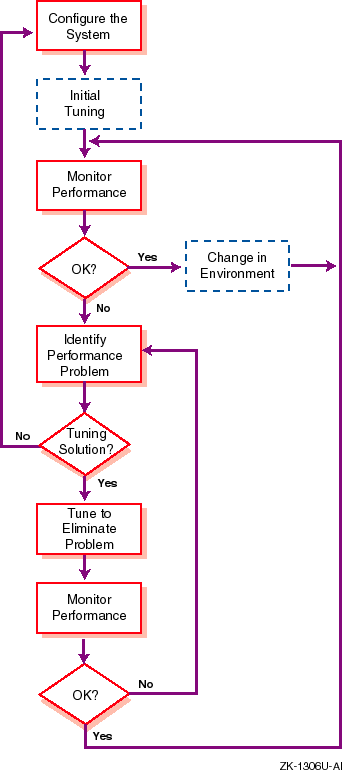
Setting up and maintaining a high-performance or high-availability system requires a number of steps. The process is as follows:
Configure the system.
To configure (or reconfigure) a system, you must determine the requirements of your environment and choose a configuration to meet your needs. Then, you can set up the hardware, operating system, layered products, and applications.
Perform any recommended initial tuning tasks.
For some configurations, you may have to perform some tuning tasks immediately after you configure your system. For example, if your system is used as an Internet server, follow the recommendations to modify the default values of system parameters and attributes.
Monitor system performance.
You must carefully monitor the performance of your system, as described in Chapter 2.
If system performance is acceptable, you must continue to monitor the system on a consistent basis, because performance may degrade if resources reach their capacity or if there is a significant change in the environment (for example, you increase the workload or you reconfigure the system).
If system performance is not acceptable, you must determine the source of the problem.
Identify the source of the performance problem.
Use the tools described in Chapter 2 to locate the source of the problem. The DIGITAL Systems & Options Catalog contains information about the capacity of hardware resources.
Determine if there is a tuning solution that will eliminate the performance problem.
If there is no tuning solution or if you have exhausted all possible tuning solutions, you may have to reconfigure the system to eliminate the performance problem.
Eliminate the performance problem.
To eliminate a performance problem, first try simple, no-cost solutions, such as running applications at offpeak hours or restricting disk access. Then, you can try more complex and expensive solutions, such as tuning the system or adding more hardware. Section 1.5 includes a list of the primary tuning tasks that may help you to improve performance.
If you are sure your CPU and applications are optimized, tuning the virtual memory subsystem provides the best performance benefit and should be the primary area of focus. If tuning memory does not eliminate the problem, tune the I/O subsystem. Tuning usually requires modifying kernel attributes. However, you may be able to improve system performance by performing some administrative tasks, such as defragmenting file systems or modifying stripe widths.
Monitor system performance.
After you tune the system, you must carefully monitor the system to ensure that the performance problem has been eliminated. If a tuning recommendation does not eliminate the problem, try another recommendation. If you cannot reduce or eliminate a performance problem by tuning the system, you must reconfigure the system.
The flowchart shown in Figure 1-3 describes the configuration and tuning process. Detailed information about diagnosing performance problems and information about configuring and tuning the CPU, virtual memory, storage, and networks is discussed in later chapters.