The best way to move your application from an ULTRIX system to a DIGITAL UNIX system is to migrate your source code to the DIGITAL UNIX system. When you port source code, the result is a native DIGITAL UNIX application that is easy to move to new versions of DIGITAL UNIX and new platforms. In addition, you can take advantage of DIGITAL UNIX features, such as 64-bit data types and addressing and shared libraries.
This chapter describes the tasks you perform to migrate source code
from an ULTRIX to a DIGITAL UNIX system after you have transported the source files
to the DIGITAL UNIX system by using
rcp,
ftp,
or
uucp
commands,
tar
archives, Network
File System (NFS) mounting, or any other appropriate method.
This chapter
also gives information about ULTRIX header files that are not supplied on
a DIGITAL UNIX system, differences in using the C compiler on an ULTRIX and a DIGITAL UNIX
system, and ULTRIX function libraries that are not supplied on a DIGITAL UNIX system.
To allow you to conveniently build your application on a DIGITAL UNIX system, modify your makefile so that it works on the DIGITAL UNIX system. The following list describes differences between DIGITAL UNIX and ULTRIX systems that could affect your makefile:
The
s5make
command is unsupported on the DIGITAL UNIX
system.
Remove references to that command and replace them with the
make
command.
The DIGITAL UNIX directory structure is different from the ULTRIX directory structure. This difference might require you to modify pathnames in your makefile.
Changes in command options could require changes to your makefile. For information about differences between ULTRIX and DIGITAL UNIX command options, see Appendix A.
Differences in how system libraries are organized could require changes to your makefile. For information about differences, see Section 7.6.
Differences between ULTRIX and DIGITAL UNIX header files and routine definitions could require changes to your makefile. For information about these differences, see Section 7.2 and Appendix B.
By default, the DIGITAL UNIX compiler links your application with
shared libraries.
If you want to link your application with static libraries,
specify the
-non_shared
option on the
cc
or
ld
command lines in the makefile.
The
make
command on DIGITAL UNIX systems does not
support retrieving source files automatically from a Source Code Control System
(SCCS) archive.
For information about using
make
on a DIGITAL UNIX system,
see
make(1).
The ULTRIX
make
command is also in the
/usr/opt/ultrix/usr/bin
directory.
To use the ULTRIX
make
command, edit the
.login
file and add the
following line to the end of the file:
source /etc/ultrix_login
This entry modifies your
PATH
variable
to allow access to the ULTRIX
make
command.
For information
about using the ULTRIX
make
command on a DIGITAL UNIX system, see
make(1u).
The set of header files on a DIGITAL UNIX system is slightly different from the set of header files on an ULTRIX system.
The contents of some DIGITAL UNIX header files differ from the contents of the
equivalent ULTRIX header files.
These differences can appear in a number
of ways.
For example, the interface to a service might be slightly different,
structure definitions might be located in different header files, values might
have changed to reflect the 64-bit Alpha architecture, or nearly identical
structures or constants might have different names.
For a list of differences
in
/usr/include
header files, see
Appendix B.
Some of the ULTRIX header files are unavailable. These header files are primarily:
Header files corresponding to features that are unsupported
in the DIGITAL UNIX system; for example,
/usr/include/hesiod.h,
which is not present because the DIGITAL UNIX system does not support the Hesiod service
Header files used by specific ULTRIX system facilities but which are not needed by DIGITAL UNIX utilities
For a list of the unavailable
/usr/include
header
files, see
Table B--3.
The DIGITAL UNIX header files are kept in a directory hierarchy descending from
the
/usr/include
directory.
Table 7-0
lists most of the directories containing standard header files.
| Directory | Description |
/usr/include |
General C header files |
DPS |
Display PostScript System C header files |
DXm |
DIGITAL extensions to Motif C header files |
Mrm |
Motif resource manager C header files |
X11 |
X Toolkit header files |
Xm |
Motif C header files |
dec |
DIGITAL specific interface header files |
lvm |
C header files for Logical Volume Manager (LVM) |
mach |
Mach-specific C include files |
net |
Miscellaneous network C header files |
netimp |
C header files for IMP protocols |
netinet |
C header files for Internet standard protocols |
netns |
C header files for XNS standard protocols |
nfs |
C header files for Network File System (NFS) |
protocols |
C header files for Berkeley service protocols |
rpc |
C header files for remote procedure calls (RPCs) |
servers |
C header files for servers |
sys |
System C header files (kernel data structures) |
tli |
C header files for Transport Layer Interface (TLI) |
ufs |
C header files for UNIX File System (UFS) |
The compiler can help you migrate your application by finding inconsistencies in the application's use of a symbol, function, or declarations in a header file. The DIGITAL UNIX C compiler issues error messages for the following conditions:
Header file not found:
cfe: Error: file.c: 1: Cannot open file cursesX.h for #include
Undefined symbol (a symbol that is not defined before its use)
This message helps you to find references to header-file symbols that have moved or are no longer available:
cfe: Error: file.c, line 8: 'ENOSYSTEM' undefined, reoccurrences will not not be reported
Multiply defined symbol (a local definition that conflicts with a header-file definition):
cfe: Warning: file.c:4: Tried to redefine the macro EDEADLK, this macro keeps the old definition in std/std1 mode, otherwise the macro is redefined.
Redeclared function (a local function declaration that conflicts with a header-file declaration):
cfe: Error: t.c, line 7: redeclaration of 'openlog'; previous declaration at line 120 in file '/usr/include/syslog.h' int openlog(char*, int); ----^
Mismatched function use and prototype (failure of a function usage to supply the number of arguments declared by the prototype declaration):
cfe: Error: file.c, line 12: Number of arguments doesn't agree with number in declaration
Incompatible function arguments (an attempt to supply incompatible arguments to a function) :
cfe: Warning: file.c, line 12: Incompatible pointer type assignment
Because function declarations or prototypes are not required by the C language before a function call, the compiler cannot detect misuse of functions that did not have a preceding prototype declared. You might need to find differences in these cases by first determining which header files your application depends on, generating a list of the function declarations these header files contain, and then using this list of functions to generate a cross-reference for the needed header files on a DIGITAL UNIX system. Then you can cross-check the actual declarations for changes in the function interfaces and modify your source code where necessary. Doing this may require that you build short shell scripts to help search for the appropriate definitions in the list of header files. The compiler has features that might be of some use in these tasks:
To produce a complete list of pathnames for include files a program depends on, use the following command on the ULTRIX system:
% cc -M file_name.c
Be sure to use the same define
( -D ), undefine ( -U ), and include ( -I )
command directives that you would typically use to compile this program.
To generate a list of functions that your application needs, and to compile without allowing any library definitions on the command line when building your ULTRIX application, use the following command:
% cc file_name.c -L
Do not include any additional
system
-ldirectory
options.
The
-L
option inhibits
ld
from
searching the standard directories for libraries.
The
ld
command will issue messages identifying any unresolved symbols.
The following
short scripts can help you locate the files containing objects that the compiler
fails to resolve:
Use the following command line to locate references to a particular
string (what to find
in the following example) in all files
contained in the working directory or in subdirectories of the working directory:
% find . -type f -print | xargs grep "what to find" > logfile
Typically, this command is used from the
/usr/include
directory to locate information in header files.
The following script searches every library archive ( *.a ) on the system for the object named as its first command-line
argument:
#! /bin/sh for i in /lib/*.a /usr/lib/*.a; do ar t $i | grep $1 && echo "$1 found in $i" done
Use this script (called
arfind
in
this example) as follows:
% arfind object-to-find
See Section 7.6.1 for more information on libraries.
The 64-bit DIGITAL UNIX system is different from the 32-bit ULTRIX system in the size of addresses, the availability of 64-bit integer types, the data type alignment restrictions, byte and word accessibility, and interoperability between 32-bit and 64-bit systems. These differences affect the following areas in your programs:
Pointers
Constants
Structures
Variables
Library calls
The following sections discuss each of these areas and the changes you must make to your program to take full advantage of the 64-bit environment, and to permit interoperability with 32-bit systems.
This section describes migration
problems that some applications will encounter because they make assignments
based on the assumption that pointers are the same length as
int
variables.
This section also contains information on how to overcome
problems with pointer-to-int
assignments with little or
no recoding.
(Information about other types of pointer assignments that may
require recoding is provided in
Section 7.3.4.2.)
The following table shows the lengths of the data types that are used to hold addresses and that can, in some usage situations, cause problems when migrating an application to a DIGITAL UNIX system:
| ULTRIX | DIGITAL UNIX | |
| Pointer | 32 bits | 64 bits |
| int | 32 bits | 32 bits |
| long | 32 bits | 64 bits |
Many C programs, especially older C programs that do not conform to
currently accepted programming practices, assign pointers to
int
variables.
Such assignments are not recommended, but they do produce
correct results on systems in which pointers and
int
variables
are the same size.
However, on a DIGITAL UNIX system, this practice can produce
incorrect results because the high-order 32 bits of a DIGITAL UNIX address
are lost when a 64-bit pointer is assigned to a 32-bit
int
variable.
The following code fragment shows this problem using DIGITAL UNIX:
{
char *x; /* 64-bit pointer */
int z; /* 32-bit int variable */
.
.
.
x = malloc(1024); /* get memory and store address in 64 bits */
z = x; /* assign low-order 32 bits of 64-bit pointer to
32-bit int variable */
}
Similar problems with the length of pointers occur in applications
that consist of a mix of C and FORTRAN programs in which a pointer in a C
program is declared as an
INTEGER*4
variable in a FORTRAN
program, leaving the conversion implicit and causing the loss of the 32 high-order
bits in the pointer.
The DIGITAL UNIX system has a set of compiler options and pragmas you can use to control pointer size and allocation, thereby allowing ULTRIX applications that may make assumptions about pointers being 32 bits to more easily migrate to a DIGITAL UNIX environment.
The set of options for the
cc
command is known as
the
xtaso
option.
Combined with the
-taso
linker option (which is required when the
xtaso
option is used), the
xtaso
option can prevent problems
with invalid addressing and pointer truncation that could occur when migrating
applications with 32-bit pointers to the DIGITAL UNIX system.
There are limits to
the use of the
xtaso
option.
First, the option should
only be used in end-user application programs, and not in library programs.
Second, the end-user application should be known to have 32-bit dependencies.
This option is most useful for applications that have already been migrated to the DIGITAL UNIX system, but exhibit performance problems due to either memory limitations or the heavy use of dynamic memory allocation.
The elements of the
xtaso
option are:
#pragma pointer_size
specifier
A C language pragma for controlling pointer size allocation that is
recognized by the compiler, but only acted on when the
-xtaso
option is specified.
This pragma is defined in the
Programmer's Guide
manual.
The
-xtaso
and
-xtaso_short
options to the
cc
command
The
-xtaso
option causes the compiler to respond
to the pragmas that control pointer size allocation.
The
-xtaso_short
option forces the compiler to allocate 32-bit pointers by default.
For more information about these compiler options, see
cc(1).
-taso
linker option
The linker option that enables correct
-xtaso
support.
The
-xtaso
option allows you to create pointers
that are only 32 bits.
Because 32-bit pointers cannot represent the entire
range of addresses that are possible in the DIGITAL UNIX system environment, you must
make sure that any programs you compile are linked using the
-taso
option.
For more information, see the following sections.
The most portable way to fix the problem presented by pointer-to-int
assignments in existing source code is to modify the code to
eliminate this type of assignment.
However, in the case of large applications,
this can be time consuming.
(To find pointer-to-int
assignments
in existing source code, use the
lint -Q
command.)
Another
way to overcome this problem is to use the Truncated Address Support Option
(-taso
option).
The
-taso
option makes it unnecessary for the pointer-to-int
assignments
to be modified.
It does this by causing a program's address space to be arranged
so that all locations within the program when it starts execution can be expressed
within the 31 low-order bits of a 64-bit address, including the addresses
of routines and data coming from shared libraries.
The
-taso
option does not affect the sizes
used for any of the data types supported by a DIGITAL UNIX system.
Its only
effect on any of the data types is to limit addresses in pointers to 31 bits
(that is, the size of pointers remains at 64 bits but addresses use only the
low-order 31 bits).
The 31-bit address limit is used to avoid the possibility of setting
the sign bit (bit 31) in 32-bit
int
variables when pointer-to-int
assignments are made.
Allowing the sign bit to be set in an
int
variable by a pointer-to-int
assignment would
create a potential problem with sign extension.
For example:
{
char *x; /* 64-bit pointer */
int z; /* 32-bit int variable */
.
.
.
/* address of named_obj = 0x0000 0000 8000 0000 */
x = &named_obj; /* 0x0000 0000 8000 0000 = original pointer
value */
z = x; /* 0x8000 0000 = value created by pointer-to-int
assignment */
x = z; /* 0xffff ffff 8000 0000 = value created by pointer-
to-int-to-pointer or pointer-to-int-to-long
assignment (32 high-order bits set to ones by
sign extension) */
}
You can specify the
-taso
option on the
cc
or
ld
command lines
used to create an application's object modules.
(If you specifiy it on the
cc
command line, the option is passed to the
ld
linker.) The
-taso
option directs the linker to set
a flag in object modules and this flag directs the loader to load the modules
into 31-bit address space.
The
-taso
option ensures that
text
and
data
segments of an application are loaded
into memory that can be reached by a 31-bit address.
Thus, whenever a pointer
is assigned to an
int
variable, the values of the 64-bit
pointer and the 32-bit
int
variable will always be identical
(except in the special situations described in
Section 7.3.1.4).
Figure 7-1
is an example of a memory diagram of programs
that use the
-taso
and
-call_shared
options (and do not use threads).
(If you invoke the linker (ld) through the
cc
command, the default is
-call_shared.
If you invoke
ld
directly,
the default is
-non_shared.)
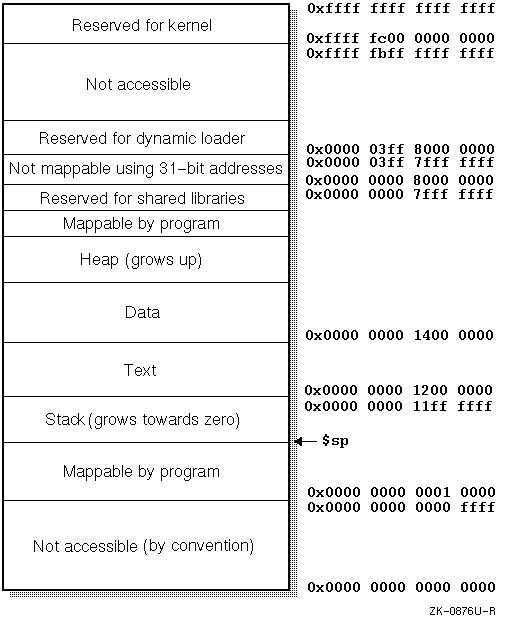
Note that stack and heap addresses will also fit into 31 bits. The stack grows downward from the bottom of the text segment, and the heap grows upward from the top of the data segment.
The
-T
and
-D
options
(linker options that are used to set text and data segment addresses, respectively)
can also be used to ensure that the text and data segments of an application
are loaded into low memory.
The
-taso
option, however,
in addition to setting default addresses for text and data segments, also
causes shared libraries linked outside the 31-bit address space to be appropriately
relocated by the loader.
The default addresses used for the text and data segments are determined
by the options that you specify on the
cc
command line:
Specifying the
-non_shared
or
-call_shared
option with the
-taso
option results in the following defaults:
Specifying the
-shared
option with
the
-taso
option results in the following defaults:
Using these default values produces sufficient amounts of space for
text and data segments for most applications (see the
Assembly
Language Programmer's Guide
for details on the contents of text
and data segments).
The default values also allow an application to allocate
a large amount of
mmap
space.
If you specify the
-taso
option and also specify text and data segment address
values with
-T
and
-D, the
values specified override the
-taso
default addresses.
You can use the
odump
utility to check whether a program was built successfully
within a 31-bit address space.
To display the start addresses of the text,
data, and bss segments, enter the following command:
% odump -ov obj_file_x.o
None of the addresses should have any bits set in bits 31 to 63; only bits 0 to 30 should ever be set.
Shared objects built with the
-taso
option cannot be linked with shared objects that were not built
with the
-taso
option.
If you attempt to link shared
objects that way, the following error message is displayed:
Cannot mix 32 and 64 bit shared objects without the -taso
option.
The
-taso
option does not prevent a program
from mapping addresses outside the 31-bit limit, and it does not issue warning
messages if this is done.
Such addresses could be established using any one
of the following mechanisms:
As previously noted, if the
-T
and
-D
options are used with the
-taso
option, the values that you specify for them will override the
-taso
option's default values.
Therefore, to avoid defeating the purpose
of the
-taso
option, you must select addresses for
the
-T
and
-D
options that
are within the address range observed by the
-taso
option.
To avoid problems with addressing when you use
malloc
in a
taso
application that does not use threads, you must
ensure that the combination of the default data-size resource limit and the
starting address of the data segment do not exceed the maximum 31-bit address
(0x7fff ffff).
Applications that use threads are unlikely to encounter this
problem because memory allocations for thread applications start in a much
lower address space than that used for nonthread applications.
The data-size resource limit is the maximum amount of data space that
can be used by a process.
This limit can be adjusted using the
limit
(C shell) or
ulimit
(Korn shell) commands.
As
previously noted, you can adjust the starting address of the data segment
by using the
-D
option on the
cc
command.
Applications that use the
mmap
system call must use
a jacket routine to
mmap
to ensure that mapping addresses
do not exceed a 31-bit range.
This entails taking the following steps:
To prevent
mmap
from allocating space outside
31-bit address space, specify the following compilation option on the
cc
command line for all modules (or at least all modules that refer
to
mmap):
-Dmmap=_mmap_32_
This option
equates the name of the
mmap
function with the name of
a jacket routine (_mmap_32_).
As a result, the jacket routine
is invoked whenever references are made to the
mmap
function
in the source program.
If the
mmap
function is invoked in only
one of the source modules, either include the jacket routine in that module
or create an
mmap_32c.o
object module and specify it on
the
cc
command line.
(The file specification for the jacket
routine is
/usr/opt/alt/usr/lib/support/mmap_32.c.)
If the
mmap
function is invoked from more than one
source file, you must use the method of creating an
mmap_32c.o
object module and specifying it on a
cc
command line because
including the jacket routine in more than one module would generate linker
errors.
Check the use of constants in your program, particularly if you are going to exchange data between 32-bit and 64-bit systems. Some constants might have different values between 32-bit and 64-bit systems, which might change the behavior of some operators. For example, hexadecimal constants are more likely to become long on DIGITAL UNIX systems. The following table lists some constants and their values:
| C Constant | Value | Value (32-Bit) | Value (64-Bit) |
| 0xFFFFFFFF | 232 -1 | -1 | 4,294,967,295 |
| 4294967296 | 232 | 0 | 4,294,967,296 |
| 0x100000000 | 232 | 0 | 4,294,967,296 |
| 0xFFFFFFFFFFFFFFFF | 264 -1 | -1 | -1 |
In C, an integer
constant is specified as 543210.
To specify a
long int
constant, use the letter suffix L or l.
To specify an unsigned
long, you use the UL or ul suffix.
(L is preferred since lowercase
l is easily confused with the number one.) Note the example where three different
constants are passed to the function,
labs():
labs(543210) labs(543210L) labs(543210UL)
On an Alpha system, 543210 is treated as a
4-byte constant, and 543210L (or 543210UL) is treated as an 8-byte constant.
If the
labs()
function expects a
long
argument, each of these invocations would work as expected since the
int
constants would be converted to
long.
If
the
labs()
function expects type
int,
the
long
constant would be truncated to an integer constant.
This truncation would result in the loss of significant digits if the constant
was greater than the maximum integer constant (INT_MAX) of +2147483647, or
less than the minimum integer constant (INT_MIN) of -2147483648, or
for unsigned constants greater than the maximum unsigned integer constant
(UINT_MAX) of 4294967295.
This problem would also be present in an assignment
expression where a
long
integer constant was assigned to
a variable of type
int.
In these cases, explicitly use
the L or UL suffix and make sure the function arguments or variables being
assigned to are of the appropriate
long
type.
When you need to pass zero to a pointer argument and no function prototype
is visible, always use NULL (defined in the
stdio.h
file).
Using zero will result in using a 4-byte zero instead of a 8-byte zero (0L).
In a comparison, an assignment, or a function call where the correct function
prototype is in scope, standard C promotion rules will be in effect and the
correct value will be assigned.
To minimize assignment and argument errors in your code, use function prototypes because the number and type arguments are checked.
A bit shift
operation on an integer constant will yield a 32-bit constant.
If you need
a result of type
long, then you need to use the L or UL
suffix for
long
integer constants.
The following example
results in
value
being assigned a 32-bit constant:
long value; value = 10 << 2;
The top 32 bits of
value
will depend on the type of the value shifted.
Signed values are sign extended;
unsigned values are zero extended.
If you want a 64-bit constant, be sure
to use the L or the UL suffix.
(Note that only the left operand of a shift
operator determines the result type.
The type of shift count operand is irrelevant.)
The 64-bit data size of the
long
and
pointer
types affects the size, member alignment, alignment, and bit fields
of structures.
The size of structures
and unions on DIGITAL UNIX systems can be different from those on 32-bit systems.
For example, the following structure,
TextNode, doubles
in size on a 64-bit system because the
pointer
types are
double in size (from 4 bytes to 8 bytes):
struct TextNode{
char *text;
struct TextNode *left;
struct TextNode *right;
};
If you are sharing data defined in structures between 32-bit and 64-bit
systems, be careful about using the
long
and
pointer
data types as members in shared structures.
These data types
introduce sizes that are not available on 32-bit systems.
To increase your application's portability, do the following in your application:
Use
typedef
types in structures and set
up the types as appropriate for the system.
You can automatically do this
by using information in the
limits.h
header file.
Be careful when building unions between the
int
and
pointer
data types, because they are not the same size.
Members of structures and unions are
said to be aligned on their natural boundaries.
That is,
char
is aligned on a byte boundary,
short
on a word boundary,
int
on a longword boundary, and
long
and
pointer
on quadword boundaries.
This means that additional space can be used for padding member alignment
in structures and unions.
For example, on 32-bit systems the size of the following
structure is 16 bytes.
On 64-bit systems, the size of the structure is 32
bytes: 8 bytes for each pointer and 4 bytes of padding after the member,
size, for the alignment of the pointer,
left.
struct TextCountNode {
char *text;
int size,
struct TextCountNode *left;
struct TextCountNode *right;
};
In the 64-bit environment, structures are aligned according to the strictest aligned member. This aids in aligning other structure members on their required boundaries. Structures are also padded to ensure proper alignment. Padding can be added within the structure or at the end of the structure, to terminate the structure on the same alignment boundary on which it started. Therefore, observe the following alignment guidelines when working with structures in a 64-bit environment:
Always use the
sizeof
operator to determine
the size of a structure.
Do not assume the size of a structure is the accumulated
size of all of the objects defined in it.
Additional space might be needed
for padding the member alignment.
Minimize the amount of padding needed in a structure by reordering the members.
In the following example, the size of
CountedString
is 16 bytes (*text
= 8 bytes,
count
= 4 bytes, tail padding = 4 bytes).
This structure is aligned on a quadword
boundary because the pointer requires quadword alignment.
No additional padding
(beyond 4 bytes of tail padding) is necessary because
CountedString
will naturally align on a quadword boundary.
struct {
char *text;
int count;
}CountedString;
In the following example, the inclusion of
CountedString
as a member in the definition forces the alignment of the beginning of the
structure to be on a quadword boundary.
Additional padding might be introduced
(depending upon the value of
MAX_LINE) to ensure proper
quadword alignment for the structure member,
string.
Additional
padding might also be introduced at the end of the structure, to ensure proper
structure alignment for arrays of these structures.
CountedString CsArray[10]
struct {
char line[MAX_LINE];
struct CountedString string;
}TextAndString;
In the following example, the structure has a size of 24 bytes:
struct s{
int count;
struct s *next;
int total;
}
If this structure is reordered, the structure now has a size of 16 bytes.:
struct s{
struct s *next;
int count;
int total;
}
Bit fields are allowed on any integral type on Alpha systems.
(ANSI C only requires bit fields with
int, signed
int, and unsigned
int
types.) In a C declaration,
if one bit field immediately follows another in a structure declaration, the
second bit field will be packed into adjacent bits of the former unit.
Since
long
is 64 bits in length on Alpha systems, adjacent declarations
of bit fields of type
long
might contain multiple bit field
definitions in cases that previously did not on RISC or VAX systems.
This
change might cause different results in operations on these bit fields.
To ensure the same behavior in operations on bit fields, change bit
field definitions of type
long
to
int.
The 64-bit DIGITAL UNIX environment also changes assumptions about how you declare your variables, and how you use them in assignments and in function arguments.
To enable your application to work on both 32-bit and
64-bit systems, check your
int
and
long
declarations.
If you have specific variables that need to be 32 bits in size
on both ULTRIX MIPS and Alpha systems, define the type to be
int.
If the variable should be 32 bits on ULTRIX MIPS systems and 64
bits on Alpha systems, define the variable to be
long.
Remember, if the type specifier is missing from a declaration, it defaults
to
int
type.
For example, here are six declarations that
declare the variables to be of size
int
and the function
to be returning type
int:
extern e; register n; static x; unsigned i; const c; function ();
Since
pointer,
int, and
long
are no longer
the same size in the 64-bit DIGITAL UNIX environment, problems may arise depending
on how the variables are assigned and used in your application.
Use the following
guidelines:
Do not use
int
and
long
interchangeably because of the possible truncation of significant digits.
For example, avoid assignments similar to the following:
int i; long l; i = l;
Use the
lint -Q
command to
help you find these potential problems.
See
Section 7.5
and
lint(1)
for more information on the
lint
command.
Do not pass arguments of type
long
to
functions expecting type
int.
For example, avoid assignments
similar to the following:
int toascii(int); int i; long l; i= toascii(l)
Do not freely exchange pointers and integers.
Assigning a
pointer to an
int, assigning back to a pointer, and dereferencing
the pointer may result in a segmentation fault.
For example, avoid assignments
similar to the following:
int i ; char *buffer; buffer = (char *)malloc(MAX_LINE) i = (int)buffer; buffer = (char*)i;
Use the
lint -Q
command to find these pointer-to-int
assignments.
If special steps are taken, pointer-to-int
assignments
can be retained without causing addressing problems.
See
Section 7.3.1
for information on how this is done.
Do not pass a pointer to a function expecting an
int
as this will result in lost information.
For example, avoid
assignments similar to the following:
void f(); char *cp; f(cp);
This nonportable function declaration will produce a compiler warning if you use ANSI C prototypes such as the following:
void f(int); char *cp; f(cp);
Use the
lint -Q
command to find
these pointer-to-int
assignments.
Use
void *type
if you need to use a generic
pointer type.
This is preferable to converting a pointer to a type
long.
Beware of the use of aliasing (different multiple definitions of the same object). For example, the following two structures refer to the same object in different ways:
struct node {
int src_addr,dst_addr;
char *name;
} ;
struct node {
struct node *src, *dst;
char *name;
}
Replace this coding with a union declaration. Be thorough when migrating this type of code to a 64-bit system, because the interdependencies and incompatibilities between these two structures might be difficult to find.
Examine all assignments of a
long
to a
double
as this can result in a loss in accuracy.
On a 32-bit system, code can assume that a
double
contains an exact representation of any value stored in a
long
(or a pointer).
By default, a
long
is 32 bits and a
double
is 64 bits with 48 bits of mantissa.
On a 64-bit DIGITAL UNIX system, this is no longer a valid assumption. For example, the following code executes differently on a 32-bit and 64-bit machine:
#include <stdio.h>
long l = 7777777777777777777L;
long l2;
double d;
main()
{
d = l;
l2 = d;
if(l == l2)
printf("On a 32-bit machine\n");
else
printf("On a 64-bit machine\n");
return(0);
}
The result of the
sizeof
operator
is of type
size_t,
which is an
unsigned long
on Alpha systems.
The length of the integer required to hold the difference
between two pointers to members of the same array,
ptrdiff_t
(
stddef.h
), is a
signed long
on Alpha
systems.
When
writing a routine that receives a variable (context-dependent) number of arguments,
you must use the
stdargs
(stdarg.h)
or
varargs
(varargs.h) mechanism.
See
varargs(3)
for more information on the use of these macros.
Programs written using
varargs
that expect the
va_list
type to be a pointer, or that make assumptions about the
stack layout of a routine's arguments, are nonportable.
Such programs must
be modified to correctly use the
varargs(3)
mechanism.
Failure to do so will
give compile-time errors, or incorrect run-time results.
See
varargs(3)
for more information.
The 64-bit data types also affect the following library calls:
printf
and
scanf
functions
malloc
and
calloc
functions
lseek
system call
fsetpos
and
fgetpos
functions
The following sections describe how these functions are affected.
When using the
printf
function for long types, you use the length modifier l (lowercase
letter L) with the
d,
u,
o, and
x
conversion characters to specify assignment
of type
long
or
unsigned long.
For example,
when printing a
long
as a signed decimal, use %ld instead
of %d.
When printing a
long
as a unsigned decimal, use
%lu instead of %u.
If the length modifier is not used, the type is assumed
to be
int, or
unsigned int, depending
upon the conversion character.
In this case, the
long
types
will be converted to the smaller
int
types and information
might be lost.
When printing a pointer, use %p.
If you want to print the pointer as
a specific representation, the pointer should be cast to an appropriate integer
type
long
before using the desired format specifier.
For
example, to print a pointer as a
long
unsigned decimal
number, use %lu:
char *p; printf ( "%p %lu\n", (void *)p, (long)p );
As a rule, to print an integer of arbitrary size, cast the integer to
long
or
unsigned long, and use the %ld (
unsigned long) conversion character.
For example:
printf ("%ld\n", (long) num ));
Memory allocation library functions
such as
malloc()
guarantee to return data aligned to the
maximum alignment of any object.
In the 64-bit DIGITAL UNIX environment,
malloc()
returns a pointer to memory that is at least quadword aligned.
When
calling the
lseek()
system call to set the current position
in a file, use the
off_t
type defined in
types.h
for the file offset.
Passing an
int
or
long
constant might work, but it is not portable and is not guaranteed
to continue to work.
The following example shows correct uses of
lseek():
lseek function: #include <unistd.h> off_t offset, pos; pos = lseek( fd, offset, SEEK_SET ); pos = lseek( fd, (off_t)0, SEEK_CUR);
When
setting or getting the file postions for a file with the ANSI C functions
of
fsetpos()
or
fgetpos(), respectively,
the file position is specified by a value of type
fpos_t.
This type is defined as a
long
in the 64-bit DIGITAL UNIX environment.
The C compiler on the DIGITAL UNIX system is different from the C compilers on the ULTRIX system. Because of differences in the compilers, you might encounter C syntax errors on DIGITAL UNIX systems that you did not encounter on ULTRIX systems. This section contains information to help you find and correct these errors. In particular, it includes a list of the DIGITAL UNIX predefined symbol names and their meanings. This section also provides information about using DIGITAL UNIX compiler options to get maximum compatibility with ULTRIX compilers, and information about differences between DIGITAL UNIX and ULTRIX C syntax for each of the ULTRIX compilers.
Both the DIGITAL UNIX and ULTRIX systems supply predefined symbols for the
cc
command.
You use these symbols to write conditional code for
different hardware platforms, different operating systems, and different programming
environments.
On DIGITAL UNIX systems, the
_ _STDC_ _
symbol is defined as follows:
When you use the
-std0
option, the
_ _STDC_ _
symbol
is undefined.
(The
-std0
option compiles code as
defined by Kernighan and Ritchie (K&R) C.)
When you use the
-std
option, the
_ _STDC_ _
symbol is 0.
(The
std
option compiles code as specified by the ANSI C standard.
This option also
allows some extensions to the ANSI C standard.)
When you use the
-std1
option, the
_ _STDC_ _
symbol is 1.
(The
-std1
option compiles code strictly according to the ANSI C standard.)
The predefined symbols on DIGITAL UNIX systems have different names from their equivalents on ULTRIX systems. Table 7--2 compares the DIGITAL UNIX and ULTRIX predefined symbols. If you use these symbols in your application, you must modify the symbol name in your source file before you recompile your application.
| Name for -std and -std1 Modes | Name for -std0 Mode | Name for ULTRIX on RISC Systems | Name for ULTRIX on VAX Systems |
| String containing the host hardware name: | |||
_ _alpha |
_ _alpha |
_ _host_mips_ _ |
vax |
| String containing the target hardware name: | |||
_ _alpha |
_ _alpha |
mips |
vax |
| String containing the operating system name: | |||
_ _osf_ _ |
_ _osf_ _ |
unix |
unix |
_ _unix_ _ |
_ _unix_ _ |
ultrix |
ultrix |
unix |
bsd4_2 |
bsd4_2 |
|
| String indicating that the host is a BSD system: | |||
_SYSTYPE_BSD |
_SYSTYPE_BSD |
SYSTYPE_BSD |
Not applicable |
SYSTYPE_BSD |
|
||
| String indicating that the application is written in C: | |||
_ _LANGUAGE_C_ _ |
_ _LANGUAGE_C_ _ |
LANGUAGE_C |
Not applicable |
LANGUAGE_C |
|
||
| String indicating that double floating-point format is used: | |||
| Not applicable | Not applicable | Not applicable | GFLOAT |
Note
This section describes the behavior of ULTRIX C on Versions 4.3 and earlier RISC ULTRIX systems, and not the behavior of ULTRIX C on Versions 4.3A or later systems. The reason is that Versions 4.3A and later systems employ the MIPS Version 3.0 compiler environment, which is more completely similar to the DIGITAL UNIX C compiler environment than the MIPS Version 2.10 compiler environment on earlier ULTRIX RISC systems, which is described here.
When you compile your ULTRIX application on a DIGITAL UNIX system, you may notice some differences in how the compilers operate. For example, the DIGITAL UNIX compiler might issue errors or warnings in cases for which the ULTRIX compiler does not. To minimize the effect of these differences, use the DIGITAL UNIX compiler option that provides the most compatibility, as shown in Table 7--2.
| If You Use This ULTRIX Option | Use This DIGITAL UNIX Option |
| Default -- K&R C with ANSI extensions. | Default (-std0)--K&R
C with ANSI extensions.
Some ANSI extensions are implemented differently.
|
-std |
-std
(Issues a warning
message for certain non-ANSI syntax.
This mode is stricter on a DIGITAL UNIX system,
so you receive more warnings than you do on an ULTRIX system.) |
Although the DIGITAL UNIX compiler options offer compatibility with the ULTRIX
C for RISC compiler, some differences between the two compilers exist.
The
ULTRIX and DIGITAL UNIX compilers operate differently in some respects regardless
of which DIGITAL UNIX compiler mode you use.
Other differences occur only when you
use the
-std0
or the
-std1
option.
The rest of this section describes these differences.
The following list describes compilation differences between ULTRIX C on RISC systems and DIGITAL UNIX C. You might notice the following differences regardless of the compilation mode you use:
The DIGITAL UNIX C compiler issues a warning if constants are longer
than the maximum allowed by
ULONG_MAX.
A similar warning
occurs if octal and hexadecimal character escape sequences exceed the value
of
UCHAR_MAX.
The ULTRIX C compiler issues no warnings
in these situations.
If a signed multicharacter constant is converted to an integer, the value of the integer might differ between DIGITAL UNIX systems and ULTRIX systems. This situation is true if the constant contains a negative value.
As required by the ANSI C standard, the DIGITAL UNIX C compiler strips
a backslash ( \ ) followed by a carriage
return ( ^M ) during the preprocessing stage.
On ULTRIX systems, these characters are stripped during the later translation
phase.
Programs containing such constructs might not work properly when input
to the DIGITAL UNIX C compiler.
The DIGITAL UNIX C compiler does not allow you to modify a type you
create with the
typedef
statement.
For example, the following
statement is invalid on DIGITAL UNIX systems:
typedef int account;
.
.
.
account monthly; unsigned account display_account;
To achieve this effect on DIGITAL UNIX systems, you must create both a signed and unsigned type, as shown:
typedef int account; typedef unsigned int display_variable;
.
.
.
account monthly; display_variable display_account;
On DIGITAL UNIX systems, you cannot declare or define a type within a function prototype. The ULTRIX compiler allows this, although doing so causes the parameter to be incompatible with any other type.
For example, suppose the structure
S
shown in the
following declaration has not been declared previously.
Any further type matching
of the parameter list results in an error.
At the end of the prototype, the
scope ends, which means that
S
is no longer available:
int convert_array (struct S *p);
On DIGITAL UNIX systems,
you must declare the structure
S
outside of the function
prototype, as shown:
struct S *p; int convert_array(struct S);
If you include a directory specification as an option to the
#line
directive, the DIGITAL UNIX C preprocessor uses the directory as the
local directory for all subsequent
#include
directives.
The ULTRIX C preprocessor did not process the
#line
directives
in this manner.
To force the compiler to search locally instead of using
the
#line
directive information, use the
-I
option to the
cc
command and specify the local
directory (the period character), as follows:
cc -g -O0 -I. -c sample_module.c
Since
various C code generators (for example,
lex
and
yacc) insert a
#line
directive into the generated
C code, you might encounter this error inadvertently.
The DIGITAL UNIX C compiler does not allow you to specify
#if
directives within a macro call.
Move
#if
directives outside of macro calls.
The DIGITAL UNIX C compiler requires you to use braces ( { } ) in initializers more precisely than the ULTRIX C compiler.
For example, the following initialization is valid on ULTRIX systems:
struct S {char i[10]; int j} y = {{"aeiou", 1}};
The DIGITAL UNIX C compiler issues an error message in response to the preceding initialization. To achieve the same effect on DIGITAL UNIX systems, use the following initialization statement:
struct S {char i[10]; int j} y = {"aeiou", 1};
In this example, the initialization of
y
contains only one set of braces.
On DIGITAL UNIX systems, you cannot declare a single type name (using
typedef) more than once except within an inner block.
The DIGITAL UNIX C compiler allows you to specify hexadecimal escape sequences in character strings and constants. On ULTRIX systems, the escape sequence is translated; for example, \x is interpreted as x on ULTRIX systems.
The default DIGITAL UNIX C compilation mode (specified by the
-std0
option) differs from ULTRIX C in the following ways that can affect
migrating C source code from ULTRIX C:
To comply with the ANSI C standard, the DIGITAL UNIX C compiler replaces comments with one space character during preprocessing. Therefore, you cannot use a comment as a concatenation character on DIGITAL UNIX systems.
On ULTRIX systems, comments within C statements are deleted with no spaces. This action allows you to use a comment as a concatenation character.
On DIGITAL UNIX systems, replace a comment that you use as a concatenation
character with the ANSI-defined concatenation characters ( ## ).
The DIGITAL UNIX compiler uses the ANSI definition of a string for C programs. ANSI defines a string in the C language as a contiguous sequence of characters terminated by, and including, the first null character. As a result, a partial string is not a valid processing token, so you cannot use a partial string in the replacement list of a macro definition.
The ULTRIX compiler allows you to use a partial string in a macro definition, as shown:
#define abc "123
You
can use this definition in a
printf
statement, as follows:
printf(abc 456");
The output from this
printf
statement is the following:
123 456
To get the same effect on a DIGITAL UNIX system,
use the following definition and
printf
statement:
#define abc "123" printf(abc " 456");
On DIGITAL UNIX systems, you can use recursive macro definitions when
you specify the
-std0
option.
On ULTRIX systems,
you cannot define macros recursively.
The strict ANSI C DIGITAL UNIX compilation mode (specified by the
-std1
option) differs from ULTRIX C in the following ways
that can affect migrating C source code from ULTRIX C:
On DIGITAL UNIX systems, declaring a local and external variable of the same name causes an error. You must use unique identifier names for each scope.
On ULTRIX systems, you can declare a local variable of the same name as an external variable. The local variable has precedence.
On DIGITAL UNIX systems, you must not use a trailing comma in an enumerator list. ULTRIX systems allow the trailing comma as shown:
enum protocols { TCP, SNMP, OSI, };
The trailing comma causes an error on DIGITAL UNIX systems, so you must remove it.
On DIGITAL UNIX systems, you cannot specify an empty declaration such as the following one:
main
{
;
.
.
.
}
Remove all empty declarations from your program.
You cannot cast the left-hand side of an assignment statement on DIGITAL UNIX systems. You must remove any such casts.
On ULTRIX systems, you can cast the left-hand side of an assignment statement, so long as the result of the left-hand side is the same size as the result of the right-hand side.
On DIGITAL UNIX systems, each identifier declaration must contain either a type or a storage class. On ULTRIX systems, you can declare an identifier without specifying a storage class or a type, as shown:
account; float profit;
In the preceding example, the ULTRIX C compiler
assumes that the account identifier is of type
extern int.
The DIGITAL UNIX C compiler issues a warning message if you omit the ending semicolon in a structure declaration list, as shown:
struct {int a,b} a;
The following shows the correct syntax to use for a structure declaration list on DIGITAL UNIX:
struct {int a,b;} a;
The DIGITAL UNIX C compiler allows you to use a special
struct
declaration to declare two structures that reference each
other.
On ULTRIX systems, to declare two structures that reference each other within a block, you use a declaration similar to the following:
struct x { struct y *p; /* ... */ };
struct y { struct x *q; /* ... */ };
If
struct y
is declared in an outer block, the first field of
struct
x
refers to the declaration of
struct y
in the
outer block.
In some cases, you might want the first field of
struct x
to refer to the declaration of
struct y
that follows
struct x.
To allow this type of declaration, the DIGITAL UNIX C compiler
defines the following special declaration:
struct y;
struct x { struct y *p; /* ... */ };
struct y { struct x *q; /* ... */ };
The partial declaration,
struct y;
supersedes the declaration of
struct y
in the outer block.
The compiler uses the next declaration of
struct
y
it encounters to define the first field of
struct x.
When you compile an application on a DIGITAL UNIX system that is compiled with DEC C on an ULTRIX system, you should notice few differences in how the program is compiled. Both compilers comply with the ANSI C language definition. However, you might notice some differences that result from implementation-specific features, standards-compatible extensions, or differences in interpretations of the ANSI standard.
To minimize the effect of any differences, use the DIGITAL UNIX C compiler option that offers the most compatibility, as shown in Table 7--2.
| If You Use This ULTRIX Option | Use This DIGITAL UNIX Option |
| Default (ANSI C with a few compatible extensions) | -std
(ANSI C with
a few compatible extensions.
Some differences exist between this mode and
the
c89
default mode.) |
-std
(Strict ANSI) |
-std1
(Strict ANSI.) |
-common
(K&R
C) |
Default (-std0,
which is K&R C with a few ANSI extensions.) |
-vaxc |
No equivalent.
For information
about migrating applications written in the VAX C programming language on
ULTRIX, see
Section 7.4.5.
|
The following list describes some differences you might notice between the DIGITAL UNIX C compiler and the DEC C compiler:
The DIGITAL UNIX C compiler supports function inlining when you use
the
-O3
option.
Function inlining eliminates the
overhead associated with calling a procedure and allows the compiler to apply
general optimization methods across functions.
The DEC C compiler also supports function inlining; however, that compiler uses a heuristic approach to performing the inline expansion of function calls.
Because of this implementation difference, the
-noinline
option has a different effect on DIGITAL UNIX and ULTRIX systems.
The
option has no meaning on a DIGITAL UNIX system, unless you also specify the
-O3
option.
With DEC C, the option applies any time you use
it.
The DIGITAL UNIX C compiler does not support using
#pragma
directives to control function inlining; that is, the compiler
does not support the following DEC C syntax:
#pragma inline
(function_name [ [, function_name...] ] )
#pragma noinline
(function_name [ [, function_name...] ] )
The DIGITAL UNIX C compiler supports only predefined macros that begin
with two underscore characters ( _ _ )
when you use the
-std
option.
Macro names that do
not begin with two underscore characters are valid when you use the default
compilation mode of the DEC C compiler.
The DIGITAL UNIX C compiler does not support the VAX C (vcc) compatibility mode keywords, language interpretations, or extensions.
See
Section 7.4.5
for information about differences between the
(vcc) compiler and the DIGITAL UNIX
cc
compiler.
The DIGITAL UNIX C compiler does not support the
-check
option for checking code similar to the way the
lint
command checks it.
To check your DIGITAL UNIX C code, use the
lint
command as described in
lint(1).
The DIGITAL UNIX C compiler does not support the
-source_listing
or
-show
options for displaying source
code listing and intermediate and final macro expansions.
If you compile an application you
wrote for the
cc
compiler on VAX ULTRIX systems with the DIGITAL UNIX
C compiler, you might notice some differences in the language definitions
the compilers accept.
Some of these differences are hardware specific, others
are differences in how the compilers are implemented.
To minimize the effect of these differences, use the DIGITAL UNIX C compiler option that offers the most compatibility, as shown in Table 7--2.
| If You Use This ULTRIX Option | Use This DIGITAL UNIX Option |
| Default (K&R C) | Default (-std0)--K&R
C with ANSI extensions.
Some differences exist due to differences between
VAX and RISC systems and differences between the compilers. |
The following list details the differences between the DIGITAL UNIX C compiler
when you use the
-std0
option and the
cc
command on a VAX machine:
The pointers on RISC systems are unsigned; on VAX systems they are signed.
On RISC systems, you cannot dereference NULL pointers, including
arguments to the
strlen
function.
The
varargs
function on RISC systems is
different from that function on VAX systems.
Your application will fail if
it walks an argument list by incrementing the address of an argument, particularly
if the arguments are double-precision values.
Use the macros in
varargs.h
when you use functions that have a variable number of
arguments.
Compiling with the
-varargs
option on
RISC systems causes the compiler to detect nonportable code.
The
setjmp/longjmp
buffer is larger on RISC systems than on VAX systems.
Applications with a
hard-coded, 10-word buffer fail; applications that include
setjmp.h
and declare a variable of type
jmp_buf
work
correctly.
RISC systems define a macro (for example, LANGUAGE_C) for the preprocessor that makes it possible to write multilingual include files.
The
-Md
or
-Mg
option is not needed when on RISC systems.
The software supports only one
double-precision format.
The DIGITAL UNIX C compiler does not allow the following obsolete form of initialization:
int i 0;
The
preceding example works on a VAX system, but the VAX
cc
compiler issues a warning.
The DIGITAL UNIX C compiler issues an error message.
The DIGITAL UNIX C compiler has boundary alignment rules. The only effect this difference should have on your application is that its performance might be slower than on a VAX system. This performance change could occur because the kernel corrects alignment errors. Where possible, align double words, words, and half words on natural boundaries.
The DIGITAL UNIX C compiler does not allow you to use a global data item as if it is a code location. For example, the compiler does not allow you to use a data structure that has the same name as a system call. If you use a global data item as a code location, the DIGITAL UNIX C compiler displays an error message similar to the following one at load time:
/lib/libc.a(gethostent.o): jump relocation out-of-range, bad object file produced, can't jump from 0x4197a0 to 0x10008198 (stat)
If you see this message, change the name of the
data structure.
(In this example, it was named
stat.)
The DIGITAL UNIX C compiler does not allow the same
.c
or
.o
file to be listed twice in a command line.
The compiler
generates errors that indicate that symbols are defined more than once.
The
cc
compiler on VAX systems allows you to specify the same source
or object file twice.
By default, the DIGITAL UNIX C compiler links your application with
shared libraries, instead of archive libraries.
If you want your application
to be linked with archive libraries, use the
-non_shared
option.
For more information, see
Section 8.1.
The DIGITAL UNIX
cc
command uses a different syntax
for the
asm
pseudofunction call.
On DIGITAL UNIX systems, the
-L
option to
the
cc
command operates only on the
-l
options that follow it.
On VAX systems, the
cc
-L
option affects all
-l
options.
If you want the
-L
option to affect all
-l
options on the command line when you use the DIGITAL UNIX C compiler,
specify the
-L
option first.
The DIGITAL UNIX C compiler does not support the
-R
option (read-only text).
The DIGITAL UNIX Version 2.0 and earlier systems support two levels
of profiling that you use by running the postprocessor
pixie
utility.
Profiling on VAX systems has two levels that you select with the
-p
and
-pg
options.
The DIGITAL UNIX Version
3.0 system supports these levels of profiling, as well as the
pixie
utility.
The DIGITAL UNIX C compiler supports five levels of optimization,
which are controlled using the
-O
option.
The C compiler
on VAX systems supports only one level of optimization, which is disabled
by default and enabled with the
-O
option.
By default, the DIGITAL UNIX C compiler optimizes as if you specified the
-O1
option.
The optimization that the compiler performs is
similar to the optimizations performed by the
cc
command
on a VAX system.
You disable optimizations by specifying the
-O0
option when you use the DIGITAL UNIX C compiler.
The DIGITAL UNIX C compiler offers four levels for debugging information
(controlled by the
-g
option).
The C compiler on
VAX systems has only two (on and off).
Both the DIGITAL UNIX C compiler and VAX
cc
command
support the
-t
and
-B
options
for specifying passes and paths.
However, the DIGITAL UNIX C compiler has more pass
names.
In addition, the DIGITAL UNIX C compiler option
-h
is equivalent to the VAX
cc
compiler option
-B.
The
-B
option to the DIGITAL UNIX C compiler
specifies a suffix for the pass name.
If you compile
an application you wrote for the
cc
compiler on VAX ULTRIX
systems with the DIGITAL UNIX C compiler, you might notice some differences in how
the compilers operate.
Some of these differences are hardware specific, others
are differences in how the compilers are implemented.
To minimize the effect of these differences, use the DIGITAL UNIX C compiler option that offers the most compatibility, as shown in Table 7--2.
| If You Use This ULTRIX Option | Use This DIGITAL UNIX Option |
| Default (VAX C on ULTRIX) | Default (-std0)--K&R
C with ANSI extensions.
Some differences exist due to differences between
VAX and RISC systems and differences between the compilers. |
The following list details the differences between the DIGITAL UNIX C compiler
when you use the
-std0
option and the
vcc
command:
The pointers on RISC systems are unsigned; on VAX systems they are signed.
On RISC systems, you cannot dereference NULL pointers, including
arguments to the
strlen
function.
The
varargs
function on RISC systems is
different from that function on VAX systems.
Your application will fail if
it walks an argument list by incrementing the address of an argument, particularly
if the arguments are double-precision values.
Use the macros in
varargs.h
when you use functions that have a variable number of
arguments.
Compiling with the
-varargs
option on
RISC systems causes the compiler to detect nonportable code.
The
setjmp/longjmp
buffer is larger on RISC systems than on VAX systems.
Programs with a hard-coded,
10-word buffer fail; applications that include
setjmp.h
and declare a variable of type
jmp_buf
work correctly.
RISC systems define a macro (for example, LANGUAGE_C) for the preprocessor that makes it possible to write multilingual include files.
The
-Md
or
-Mg
option is not needed when on RISC systems.
The software supports only one
double-precision format.
The DIGITAL UNIX C compiler does not support the following VAX C keywords:
_align
globaldef
globalvalue
noshare
readonly
variant_struct
variant_union
The DIGITAL UNIX C compiler does not support the
main_program
option.
On VAX ULTRIX systems, this option allows you to give
the
main
function a different name.
To be compatible, DIGITAL UNIX C structure and union types must be
identical.
The
vcc
compiler treats structure and union
types as compatible if they are the same size in bytes.
The types need not
be identical to be compatible.
The DIGITAL UNIX C compiler does not support applying the unary
&
(address-of) operator to a constant in the argument list of
a function call.
The
vcc
compiler supports this use of
the
&
operator.
The DIGITAL UNIX C compiler replaces comments that separate tokens in a macro definition with one space character during preprocessing. Therefore, you cannot use a comment as a concatenation character on DIGITAL UNIX systems.
On VAX ULTRIX systems, comments that separate tokens within a macro definition are deleted with no spaces. This action allows you to use a comment as a concatenation character.
On DIGITAL UNIX systems, replace a comment that you use as a concatenation
character with the ANSI-defined concatenation characters ( ## ).
On DIGITAL UNIX systems, you can redefine a macro only if the token
you use in the new macro definition is identical to the token you used in
the existing macro definition.
The
vcc
compiler allows
you to redefine macros.
The DIGITAL UNIX C and
vcc
compilers use a different
algorithm for substituting macro definitions.
These different algorithms might
cause you to notice differences in how your macros are processed on a DIGITAL UNIX
system.
By default, the DIGITAL UNIX C compiler links your application with
shared libraries, instead of archive libraries.
If you want your application
to be linked with archive libraries, use the
-non_shared
option.
For more information, see
Section 8.1.
The DIGITAL UNIX Version 2.0 and earlier systems support two levels
of profiling that you use by running the postprocessor
pixie
utility.
Profiling on VAX systems has two levels that you select with the
-p
and
-pg
options.
The DIGITAL UNIX Version
3.0 system supports these two levels of profiling as well as the
pixie
utility.
The DIGITAL UNIX C compiler supports five levels of optimization,
which are controlled by using the
-O
option.
The
vcc
compiler supports only one level of optimization, which is disabled
by default and enabled with the
-O
option.
By default, the DIGITAL UNIX C compiler optimizes as if you specified the
-O1
option.
The optimization the compiler performs is similar
to the optimizations performed by the
vcc
command.
You
disable optimizations by specifying the
-O0
option
when you use the DIGITAL UNIX C compiler.
The DIGITAL UNIX C compiler offers four levels for debugging information
(controlled by the
-g
option).
The
vcc
compiler has only two (on and off).
Both the DIGITAL UNIX C compiler and the ULTRIX
vcc
command support the
-t
and
-B
options for specifying passes and paths.
However, the DIGITAL UNIX C compiler has
more pass names.
In addition, the DIGITAL UNIX C compiler option
-h
is equivalent to the
vcc
compiler option
-B.
The
-B
option to the DIGITAL UNIX C compiler
specifies a suffix for the pass name.
The DIGITAL UNIX C compiler does not produce a listing that contains the source code, symbol table, machine code, and cross-reference information.
After you create object files for your application, use the
lint
command to find other problems.
The
lint
command gives you information about whether you use data types correctly in
your application, whether you use routines and variables correctly, whether
there are any 64-bit migration problems, and so on.
The
-Q
option is included as support for migrating
ULTRIX applications to the DIGITAL UNIX system by identifying those programming techniques
that might cause problems on a 64-bit DIGITAL UNIX system.
The techniques identified
include: pointer alignment; pointer and integer data type combinations; assignments
that cause a truncation of long data types; assignments of long data types
to another type; structure and pointer combinations; type castings; and format
control strings in
scanf
and
printf
calls.
Be aware that if you never used
lint
on your ULTRIX
application, it might give you quite a bit of information about your DIGITAL UNIX
application, some of which will not be pertinent to the problems with porting
your application.
For more information about using
lint, see
lint(1).
Use the
cc
compiler to link your application.
The
linker reports errors caused by routines that do not exist on a DIGITAL UNIX system
or by global symbols that are undefined.
In some cases, these errors occur
because the DIGITAL UNIX system does not provide a routine or a global symbol definition.
In other cases, the name of the routine or global symbol has changed.
To determine whether a routine exists, see the DIGITAL UNIX documentation. Check the documentation carefully because the DIGITAL UNIX system has some routines or symbols that use names different from those on the ULTRIX system. If a DIGITAL UNIX routine or symbol exists that performs the task that the ULTRIX routine or symbol performs, modify your program. Replace each reference to the ULTRIX routine or symbol name with the appropriate DIGITAL UNIX routine or symbol name. As you make this change, check each call to ensure that it passes the correct number of parameters in the correct order and that the parameters have the appropriate data type.
If no routine exists on the DIGITAL UNIX system, remove the routine from your application and make appropriate modifications to your applications.
Some ULTRIX libraries are unavailable on DIGITAL UNIX systems. In some cases, the routines that are in the ULTRIX libraries are available in a different DIGITAL UNIX library. In other cases, the ULTRIX library routines are unavailable on the DIGITAL UNIX system. Section 7.6.1 describes ULTRIX libraries that are unavailable on DIGITAL UNIX systems.
The DIGITAL UNIX system provides two libraries for compatibility with ULTRIX systems:
The
libbsd.a
library contains routines
that are compatible with the ULTRIX BSD programming environment.
(Section 7.6.2
describes this library.)
The
libsys5.a
library contains routines
that are compatible with the ULTRIX System V programming environment
and other System V programming environments.
(Section 7.6.3
describes this library.)
You might need to link your application with one of these libraries if it depends on the behavior of a BSD or System V library routine.
The following list summarizes differences between ULTRIX and DIGITAL UNIX system libraries:
Merger of libraries into the
libc
library
Unlike ULTRIX systems, the internationalization library,
libi.a, the POSIX library,
libcP.a, and the System
V library,
libcV.a, are part of the standard C library,
libc, except where conflicts between System V and other standards
exist.
Remove references to these libraries from your
cc
or
make
command line.
Separation of libraries from the
libc
library
Unlike ULTRIX systems, the
libmld
library is not
part of the standard C library,
libc.
Add a reference to this library in your
cc
or
make
command line if you want to include these functions.
Movement of functions between libraries
On ULTRIX Version 4.3A and earlier systems, the
DXmHelpSystemOpen,
DXmHelpSystemDisplay, and
DXmHelpSystemClose
functions were contained in the
libDXm.
On DIGITAL UNIX
systems, these functions are contained in
libbkr.
(This
difference does not apply to ULTRIX Version 4.4 systems.)
Libraries supporting unavailable features
A number of libraries are not included in the DIGITAL UNIX system due to differences in features between ULTRIX and DIGITAL UNIX systems. These include:
Kerberos library routines:
libkrb.a,
libknet.a,
libdes.a, and
libacl.a
Graphics and plotting libraries
(located in
/usr/lib
on ULTRIX systems):
plot,
plotaed,
plotbg,
plotdumb,
plotgigi,
plotgrn,
plot2648,
plot7221,
plotimagen,
300,
300s,
450,
4013,
4014, and
lvp16
You must remove calls to routines in these libraries from your application if you want to compile it on a DIGITAL UNIX system. Also, be sure to omit references to these libraries from the command line you use to build the application.
The DIGITAL UNIX system provides the
libbsd.a
library
to allow you to use library routines that are compatible with ULTRIX BSD library
routines.
Table 7--2
lists the routines in the library
and describes the BSD compatibility they offer.
The most significant behavior
of the routines in this library are
siginterrupt()
and
signal(), which restart system calls that are interrupted by signals.
(The default, in compliance with the POSIX standard, is not to restart system
calls that are interrupted by signals.)
To use the BSD functions, use the
-D_BSD
and
-lbsd
options on the compilation line.
The DIGITAL UNIX system provides the
libsys5.a
library
to allow you to use library routines that are compatible with System V library
routines.
Table 7--2
lists the routines in the library
and describes the System V compatibility they offer.
This library contains
routines for those
libc
routines whose behavior is incompatible
with POSIX or X/Open standards.
The ULTRIX system also provides a System V
compatibility library,
libcV.a, which supplies a number
of features similar to those that
libsys5.a
provides.
The most significant behavior of the routines in this library is the compatibility
with System V nonblocked signals.
For more information about the System V (SVID-2) features in DIGITAL UNIX systems, see the System V Compatibility User's Guide.
The DIGITAL UNIX
system supports two versions of the
termcap
library and
two versions of the
curses
library.
To use the default
termcap
library (similar to the BSD 4.3
termcap
library), use the
-ltermcap
option in the compilation
line.
To use the BSD 4.3-5
termcap
curses
functions (similar to ULTRIX Version 4.2), use the
-D_BSD
and
-lcurses
options in the compilation line.
The
ULTRIX system supports one version of the
termcap
library
and two versions of the
curses
library:
The X/Open
curses
functions, which are
part of the
cursesX
library
The BSD 4.2
curses
functions, which are
part of the
curses
library
Table 7--2 helps to clarify how to port ULTRIX specific applications to the DIGITAL UNIX system.
| If You Use this ULTRIX Option | Use this DIGITAL UNIX Option | Library Used by C Compiler |
-ltermcap
or
-ltermlib |
-D_BSD -ltermcap
or
-D_BSD-ltermlib |
BSD 4.2
termcap
library
(IBM AIX library on a DIGITAL UNIX system; similar to BSD 4.3 library) |
-D_BSD -lcurses -ltermcap
or
-lcurses -ltermlib |
-D_BSD -lcurses -ltermlib |
BSD 4.2
termcap
and
curses
libraries (BSD 4.3-5
curses
and
termcap
functions on a DIGITAL UNIX system) |
-lcursesX |
-lcurses |
X/Open
curses
library
(System V Release 3
curses
and
terminfo
functions on a DIGITAL UNIX system) |
-lcurses |
-D_BSD -lcurses |
BSD 4.2
curses
library
(BSD 4.3-5
curses
functions on a DIGITAL UNIX system) |
In addition, the
/usr/include/cursesX.h
header file
is replaced by
/usr/include/curses.h, so that you must
change all pertinent
cursesX
references in your source
files and makefile.
As described earlier, there are different versions of some library calls included for compatibility with the ULTRIX system. There are a few areas where ULTRIX specific library behavior is not in the DIGITAL UNIX system. The following list describes the known differences in library behavior that are not reflected by changes in the call interface or header file. These differences require that you change your source code.
The
ULTRIX
sprintf
routine returns its first argument for success
and end-of-file (EOF) for failure.
The DIGITAL UNIX
sprintf
routine
returns the number of displayable characters in the output (not necessarily
the number of bytes) for success and a negative number for failure.
The number
returned for success does not include the terminating
\0
character.
The
printf,
sprintf,
and
fprintf
routines do not support the use of the
%D
parameter.
If applications use the
%D
parameter
to display a long number in decimal format, the routines print the character
D instead of the number.
Instead, use the
%d
or
%ld
parameter in your print routines.
On
ULTRIX systems, if you call
malloc
for a zero length buffer,
a pointer to the buffer is returned.
The DIGITAL UNIX
malloc
call
returns a NULL pointer and sets
errno
to EINVAL.
On
ULTRIX systems, the default definition of the
getpgrp
system
call is:
int getpgrp(pid_t, pid_t)
The POSIX-conformant definition
of
getpgrp
on DIGITAL UNIX systems states that
getpgrp
is called without arguments and returns the process group of the
current process:
pid_t = getpgrp();
The ULTRIX system's mechanism for setting a process's group ID is:
void = setpgrp(int, int);
This system call is
supported on DIGITAL UNIX systems for compatibility only.
In new applications, use
the POSIX-standard
setgpid
call:
pid_t = setpgid(pid_t, pid_t);
On ULTRIX systems, read operations on directories are supported by the following statements:
#include <sys/dir.h> struct direct *readdir(dirp); DIR *dirp;
On DIGITAL UNIX systems, read operations on directories are supported by the following statements:
#include <sys/dirent.h> struct dirent *readdir(DIR *dirp);
See
opendir(3)
for more information.
On DIGITAL UNIX systems, the
setsysinfo
and
getsysinfo
system calls have been expanded
to provide unaligned access control similar to that found on ULTRIX systems.
In addition,
SSI_UACPROC
and
SSI_UACPARNT
options accept three other options as arguments:
UAC_NOPRINT
Suppresses the printing of the unaligned error message to the user.
UAC_NOFIX
Instructs the operating system not to fix the unaligned access fault.
UAC_SIGBUS
Forces a
SIGBUS
signal to be delivered to the thread.
These options are defined in
sys/proc.h, and can
be specified in any combination on a per task basis.
UAC
settings are inherited by children, so forked
processes will have the same
UAC
characteristics as their
parent.
The
SSI_UACSYS
option only accepts the
UAC_NOPRINT
option and suppresses unaligned fixup messages regardless
of the users' setting.
Only the superuser is allowed to use this option.
The following example shows the
setsysinfo
call usage
in an application:
#include <sys/sysinfo.h> #include <sys/proc.h>
.
.
.
int buf[2], val, arg;
.
.
.
/* Do not print the warning to the user */ buf[0] = SSIN_UACPROC; buf[1] = UAC_NOPRINT; error = setsysinfo(SSI_NVPAIRS, buf, 1, 0, 0);
.
.
.
/* Do not print the warning and deliver a SIGBUS signal */ buf[0] = SSIN_UACPROC; buf[1] = UAC_NOPRINT | UAC_SIGBUS; error = setsysinfo(SSI_NVPAIRS, buf, 1, 0, 0);
.
.
.
On ULTRIX systems, the
catopen
routine opens a message catalog and returns a catalog descriptor
if successful.
On DIGITAL UNIX systems, the
catopen
routine does
not open the message catalog.
Instead, it is the
catgets
routine that opens a message catalog.
Therefore, if your application checks
whether a message catalog was successfully opened, you must change your program
to reflect this change.
For example, the following ULTRIX code will not work
on a DIGITAL UNIX system:
catd = catopen("example.cat", 0);
if (catd == (nl_catd) -1)
/* message catalog was not opened */
else
/* message catalog was opened */
The following code shows
how the previous code is modified to use the
catgets
routine:
catd = catopen("example.cat", 0);
if (catgets(catd, 1, 1, NULL) == NULL)
/* message catalog was not opened */
else
/* message catalog was opened */
The manner for establishing controlling terminals is an implementation-defined
process that is different for DIGITAL UNIX and ULTRIX systems.
On the DIGITAL UNIX system
(and according to the POSIX standard), a process must be a session leader
to establish a controlling terminal.
The DIGITAL UNIX system defines allocation of
a control terminal with an explicit call to
ioctl().
When
porting source code, you need to obtain a controlling terminal in the following
way:
(void) setsid();
fd = open("/dev/tty01", O_RDWR );
(void) ioctl(fd, TIOCSCTTY, 0);
The manner for establishing and
controlling modem connections is different for DIGITAL UNIX and ULTRIX systems.
The DIGITAL UNIX
system uses POSIX conventions for modem control.
Information about a serial
line can be inspected and altered in the POSIX
termios
structure, using the
tcgetattr()
and
tcsetattr()
library routines.
On ULTRIX systems, modem control was accomplished
using the TIOCCAR, TIOCNAR, and TIOCWONLINE requests to the
ioctl()
system call.
These requests are not supported on a DIGITAL UNIX system.
When porting source code, open a serial line in the following manner:
fd = open(ttyname,O_RDWR | O_NONBLOCK);
The O_NONBLOCK flag enables you to complete a read request, in case the CLOCAL flag is not set and you are monitoring the modem status lines.
Get the current line attributes; set the CLOCAL flag, in case it is not already set; and turn off the O_NONBLOCK flag in the following manner:
tcgetattr(fd,&tty_termios); /* get current line attributes */
if ((tty_termios.c_cflag & CLOCAL) == 0) {
tty_termios.c_cflag |= CLOCAL;
tcsetattr(fd,TCSANOW,&tty_termios);
}
flags = fcntl(fd, F_GETFL)
fcntl(fd, F_SETFL, flags & ~O_NONBLOCK)
You can now use your implementation-defined process for dialing the phone number and negotiating with the modem. After this, monitor the modem signals by doing the following:
tty_termios.c_cflag &= ~CLOCAL; tcsetattr(fd,&tty_termios); /* watch for modem signals now */ alarm(40); /* set a timer; do not wait forever */ read(fd,buffer,count); /* this read() blocks, pending the appearance of modem signals */ alarm(0); /* turn off timer */
See Appendix D for a comparison of an ULTRIX application using modem control and a DIGITAL UNIX application using modem control. The comparison is for an outgoing call. In addition, Appendix D also contains a sample application for an incoming call.
The Transmission Control Protocol (TCP) and
User Datagram Protocol (UDP) transport providers are supported by both ULTRIX
and DIGITAL UNIX X/Open Transport Interface (XTI).
However, when creating a transport
end point with the
t_open
call, ULTRIX does not need device
information to specify a transport provider.
In the DIGITAL UNIX system, this information
must be present because XTI is implemented using the
xtiso
pseudostreams driver.
You must change all your
t_open
calls to reflect
this change for both TCP and UDP transport providers or change your application
to determine the end point at run time.
For example:
#ifdef _ _osf_ _
t_open ("/dev/streams/xtiso/tcp", ...)
#else
t_open ("tcp", ...)
#endif
On ULTRIX systems, XTI is layered on sockets.
If you call
select
for an incoming asynchronous XTI
connection, the socket becomes writable.
On DIGITAL UNIX systems, XTI is layered on
streams.
If you call
select, the socket becomes readable.
You can either modify your application to work with the DIGITAL UNIX
select
call or substitute the
poll
call for the
select
call and modify your application to use this call.
See the
Network Programmer's Guide
for more information on XTI.
The ULTRIX
ccmn_ccbwait()
function is replaced
by the DIGITAL UNIX
ccmn_send_ccb_wait()
function.
The DIGITAL UNIX function
sends a CAM Control Block (CCB) to the transport (XPT) layer and sleeps on
the address of the CCB at the passed priority level, waiting for the CCB to
complete.
For more information, see the
Writing Device Drivers for the SCSI/CAM Architecture Interfaces
manual.
On ULTRIX
systems, if you call
open
with a null pathname, it defaults
to the current directory.
On DIGITAL UNIX systems, if you call
open
with a null pathname, it returns an error.
After your application links successfully, you are ready to run and
test it.
Correct run-time errors by using the
dbx
debugger
as an aid.
After you correct the semantic errors, your application is ported to the DIGITAL UNIX system. In some cases, it might still not work properly. One possible problem area is differences in the way certain routines on DIGITAL UNIX systems are called or the return values. See Section 7.8 and Appendix B for more information.