![]()
![]()
![]()
![]()
![]()
![]()
![]()
Compaq Tru64 UNIX fully supports the following Japanese codesets by including locales and codeset conversion support:
It also provides codeset conversion support for the following codesets:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
DEC Kanji is the codeset currently used by all Compaq Japanese products. Thus, software supporting this codeset can exchange data with existing Japanese products. This codeset is denoted as deckanji in the Compaq Tru64 UNIX system.
DEC Kanji is formed by the following character sets:
DEC Kanji uses a combination of single-byte data and two-byte data to represent ASCII characters, symbols, and ideographic characters.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
All ASCII characters or JIS X 0201 Roman letters can be represented in the form of single-byte 7-bit data in DEC Kanji. That is, the most significant bit (MSB) of these characters is always set off.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Each JIS X 0208 character is represented by a two-byte code in DEC Kanji. The MSB of both bytes is always set on to distinguish it from an ASCII/JIS Roman character or a user-defined character.
![]()
The first byte of a two-byte code determines its row number, while the second determines its column number. The following formula illustrates the code of a JIS X 0208 character in relation to its row and column numbers:
1st byte = A0 + row number
2nd byte = A0 + column number
For example, if a character is positioned at the first column of the 36th row, its encoding value can be calculated as follows:
1st byte = A0 (hex) + 36 = C4 (hex)
2nd byte = A0 (hex) + 01 = A1 (hex)
In this case, the character code is C4A1.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
In addition to the ASCII or JIS Roman Code and the JIS X 0208 Code, DEC Kanji provides an area of 2,914 positions for user-defined characters. This UDC code range is shown in Table 2-1.
Area Usage |
Row Range |
Number of Characters |
Code Range |
|---|---|---|---|
User Area |
1-31 |
2,914 |
A121-BF7E |
DEC Reserved |
32-94 |
A UDC is also represented by a two-byte code, just like a JIS X 0208 character. However, the MSB of the second byte is set off to distinguish it from a JIS X 0208 character, as shown in Figure 2-2.
![]()
The following formula illustrates the code of a UDC in relation to its row and column numbers:
1st byte = A0 + row number
2nd byte = 20 + column number
For example, if a UDC is positioned at the first column of the 16th row, its encoding value can be calculated as follows:
1st byte = A0 (hex) + 16 = B0 (hex)
2nd byte = 20 (hex) + 01 = 21 (hex)
In this case, the character code is B021.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Figure 2-3 illustrates the division of the two-byte code space and the position of JIS X 0208 and User-Defined Characters in DEC Kanji:
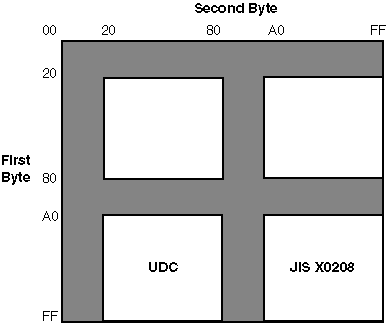
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Extended UNIX Code (EUC) is an encoding method that allows up to four character sets to be combined in a single data stream. Japanese EUC, denoted as eucJP, is the EUC codeset for representing Japanese data.
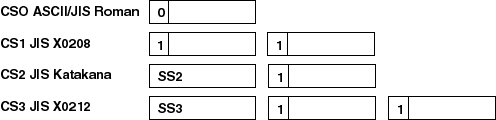
CSO is called the primary character set while CS1 through CS3 are the supplementary character sets. The MSB of the primary character set must be off while the MSB of all bytes in the supplementary character sets must be on. This scheme is used to determine the character set to which a character belongs.
The representation of ASCII/JIS Roman and JIS X 0208 characters is similar to that of DEC Kanji. In addition, two more character sets, JIS Katakana and JIS X 0212, are encoded in Japanese EUC by making use of the Single-Shift 2 (SS2) and Single-Shift 3 (SS3) control characters.
Japanese EUC provides two areas for defining a UDC as shown in Table 2-2.
Area Usage |
Row Range |
Number of Characters |
Code Range |
|---|---|---|---|
JIS X 0208 |
85-94 |
940 |
F5A1-FEFE |
JIS X 0212 |
78-94 |
1,598 |
SS3 + EEA1-FEFE |
Note
JIS X 0212 characters (JIS Supplementary Kanji) are not supported in this release of the Compaq Tru64 UNIX operating system.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Super DEC Kanji, denoted as sdeckanji, is an extension to DEC Kanji which supports the CS2 (JIS Katakana) and CS3 (JIS X 0212) character sets as encoded in Japanese EUC. It is a superset of both DEC Kanji and Japanese EUC. Data encoded in both DEC Kanji and Japanese EUC can be handled with this unified codeset. This codeset was invented to ease the transition from DEC Kanji to Japanese EUC. Figure 2-5 illustrates the encoding of Super DEC Kanji.
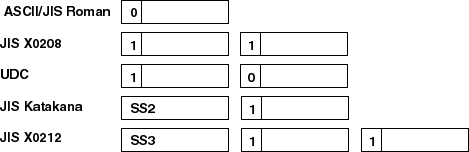
Super DEC Kanji provides three areas for defining UDCs, as shown in Table 2-3.
Area Usage |
Row Range |
Number of Characters |
Code Range |
|---|---|---|---|
JIS X 0208 |
85-94 |
940 |
F5A1-FEFE |
JIS X 0212 |
78-94 |
1,598 |
SS3 + EEA1-FEFE |
UDC |
1-94 |
8,836 |
A121-FE7E |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Shift JIS, denoted as SJIS, is a popular codeset which is widely used in the PC market.
Shift JIS codes use a combination of single-byte data and two-byte data to represent characters defined in JIS X 0201 and JIS X 0208. To allow the characters defined in these standards to be encoded in a single codeset, the first byte of each JIS X 0208 character is encoded in the ranges 81-9F and EO-FC, while the second byte is between 40 and FC, as shown in Table 2-4.
Byte |
Range |
|---|---|
First byte |
81-9F, E0-FC |
Second byte |
40-FC (except 7F) |
Figure 2-6 illustrates the first and second byte code space of Shift JIS.
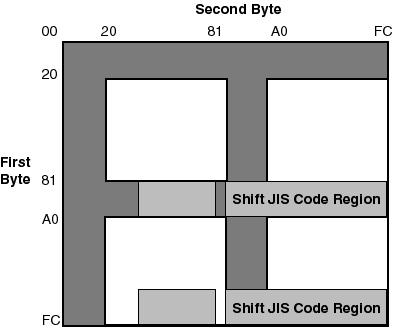
Table 2-5 illustrates the mapping from the encoding of the first byte to the corresponding character sets in the Shift JIS encoding.
Code Range of First Byte |
Character Set |
Bytes per Character |
|---|---|---|
00-7F |
JIS Roman (X 0201) |
1 |
81-9F |
JIS X 0208 |
2 |
A1-DF |
JIS Katakana (X 0201) |
1 |
E0-FC |
JIS X 0208 |
2 |
Shift JIS provides an area for defining UDC as follows:
Number of characters: |
2,444 |
Code range: |
F040 - FCFC |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The JIS Kanji codesets use the ISO 2022 methodology for encoding the JIS X 0208 and JIS X 0201 character sets. There are two types of JIS Kanji encoding: 7-bit JIS Kanji code and 8-bit JIS Kanji code.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
In 7-bit JIS Kanji encoding, all characters are represented as 7 bits. Characters are interpreted according to control sequences as follows:
Kanji in sequence (ESC $ B)
Code values following the Kanji-in sequence (ESC $ B) are treated as characters in the JIS X 0208 Kanji character set.
Kanji out sequence (ESC ( B)
Code values following the Kanji-out sequence (ESC ( B) are treated as ASCII characters.
Supplementary Kanji in sequence (ESC $ ( D)
Code values following the supplementary Kanji in sequence (ESC $ ( D) are treated as characters in the JIS X 0212 supplementary Kanji character set.
User-Defined Character (UDC) in sequence (ESC $ ( 0)
Code values following the UDC in sequence (ESC $ ( 0) are treated as characters in the vendor-defined or user-defined character set.
Kana in (SO) and Kana out (SI) sequences
Code values following the Shift-Out (SO) control character (0x0e) and preceding the Shift-In (SI) control character (0x0f) are treated as characters in the JIS X 0201 Katakana character set.
Katakana in sequence (ESC ( I)
Code values following the Katakana in sequence (ESC ( I) are treated as characters in the JIS X 0201 Katakana character set. In this case, the Kanji out sequence is used to switch back to ASCII code.
The Katakana in and Kanji out sequences are an alternative to using the Kana in and out sequences (SO/SI).
![]()
![]()
![]()
![]()
![]()
![]()
![]()
In 8-bit JIS Kanji encoding, the JIS X 0201 Katakana characters are represented as 8 bits. Using this form of encoding, control sequences have the following effect:
Kanji in sequence (ESC $ B)
Code values following the Kanji in sequence (ESC $ B) are treated as characters in the JIS X 0208 Kanji character set.
Supplementary Kanji in sequence (ESC $ ( D)
Code values following the supplementary Kanji in sequence (ESC $ ( D) are treated as characters in the JIS X 0212 supplementary Kanji character set.
User-Defined Character (UDC) in sequence (ESC $ ( 0)
Code values following the UDC in sequence (ESC $ ( 0) are treated as vendor-defined or user-defined characters.
Kanji out sequence (ESC ( B)
Code values following the Kanji out sequence (ESC ( B) are treated as ASCII characters.
Kana in and out sequences (SI/SO)
These sequences are ignored.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The JIS Kanji codesets can be used in codeset conversion and terminal display.
For codeset conversion using the iconv utility, the string JIS7 indicates 7-bit JIS Kanji code that follows a Katakana in sequence and the string jiskanji7 indicates 7-bit JIS Kanji code entered between Kana in and out sequences. The following sequences are valid within the input data that iconv does not generate these sequences when converting to JIS Kanji:
For terminal display using tty, the string jis7 indicates 7-bit JIS Kanji code and the string jis8 indicates 8-bit JIS Kanji code. When the terminal code is set to jis7, the Kana in and out sequences (SI/SO) are used for JIS X 0201 Katakana character representation.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The ISO-2022-JP codeset consists of the following character sets:
Note
JIS X 0208-1990 is a revised version of JIS X 0208-1978. Some characters of JIS X 0208-1978 were mapped to other positions.
Before a character set is used, it must be identified using an escape sequence as follows:
Escape Sequence |
Character Set |
|---|---|
ESC ( B |
ASCII |
ESC ( J |
JIS X 0201-1976 (left-hand part) |
ESC $ @ |
JIS X0208-1978 |
ESC $ B |
JIS X 0208-1990 |
It is assumed that the starting code of a line is ASCII (including CR alone and LF alone, but not including the combination CRLF). If there are JIS X 0208 characters on a line, there must be a switch to ASCII or to the left-hand part of (Roman letters) before the end of the line (in other words, before the CRLF, or carriage return and line feed).
For example, if a line starts with the ASCII character 9, followed by the JIS X 0208-1978 character at row 16 column 1, the line is encoded as follows:
39h ESC $ @ 30h 21h .... ESC ( B .... CRLF
If a line starts with the JIS X 0208-1978 character at row 16 column 1, followed by the ASCII character 9, then the line is encoded as follows:
ESC $ @ 30h 21 ESC ( B 39h .... CRLF
Once a character set is designated, there is no need to redesignate the character set if the adjacent character belongs to the same character set. For example, the following practice is not recommended:
Currently, the ISO-2022-JP codeset can be used in codeset conversion.
The iconv utility uses the following escape sequences when code is converted to ISO-2022-JP.
Escape Sequence |
Character Set |
|---|---|
ESC ( B |
ASCII |
ESC $ B |
JIS X 0208 |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The extended ISO-2022-JP codeset, denoted as ISO-2022-JPext, is an extended version of the ISO-2022-JP codeset. It is extended to support narrow JIS X 0201 Katakana characters, JIS X 0212 characters, and user-defined characters (UDC).
This codeset can be used in codeset conversion.
The iconv utility uses the following escape sequences when code is converted to ISO-2022-JPext:
Escape Sequence |
Character Set |
|---|---|
ESC ( B |
ASCII |
ESC $ B |
JIS X 0208 |
ESC ( I |
JIS X 0201 Katakana |
ESC $ ( D |
JIS X 0212 |
ESC $ ( 0 |
UDC |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
UCS is a standard character encoding for the universal character set specified in the Unicode and ISO/IEC 10646 standards. UCS has two forms; UCS-2 (16-bit, or 2 octet units) and UCS-4 (32-bit, or 4 octet units). Unicode uses the UCS-2 form, which is commonly used on personal computers. ISO/IEC allows either UCS-2 or UCS-4 encoding. UCS-4 encoding is in use on systems that can support the larger data unit size.
The current version of the Compaq Tru64 UNIX operating system supports both UCS-2 and UCS-4 encoding. UCS-4 is available in some Japanese locales, and can be used in codeset conversion. For information about codeset conversion, see Section 2.13. For information about locales, see Chapter 3, Locales.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Unicode and ISO/IEC 10646 standards define transformation formats for the universal character set. For the most part, the following UCS transformation formats (UTFs) exist to transform UCS values into sequences of bytes for handling by various byte-oriented protocols:
UTF-16, a transformation format that allows systems that can process only 16-bit units (specified by UCS-2 encoding) to support the extended character definition space that is included in UCS-4.
The current version of the Compaq Tru64 UNIX operating system supports UTF-8. UTF-8 can be used in codeset conversion and in locales. For information about codeset conversion, see Section 2.13. For information about locale variants, see Chapter 3, Locales.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The IBM Kanji System character set, denoted as ibmkanji, is developed by IBM Corporation and widely used on IBM mainframe systems. The IBM Kanji System character set consists of JIS X 0208, approximately 40 IBM-specific characters, and user-defined characters (UDC). Each character is two bytes; the character set does not contain any one byte code. IBM Kanji code is always used with Extended Binary-Coded-Decimal Interchange Code (EBCDIC).
EBCDIC, developed by IBM Corporation, is used by many mainframe system vendors. EBCDIC contains one byte code with some derivatives. For example, the EBCDIC Kana code contains one byte English characters (uppercase), numerical characters, Katakana characters, and some control codes.
The shift codes used to distinguish IBM Kanji and EBCDIC are shown in the following table.
| Meaning | Code Value |
|---|---|
| Begin IBM Kanji | 0x0e |
| End IBM Kanji | 0x0f |
Code values following 0x0e are treated as characters of IBM Kanji until the code value of 0x0f appears. Code values following 0x0f are treated as characters of EBCDIC until the code value of 0x0e appears, and so on.
The IBM Kanji System character set can be converted to and from DEC Kanji, Super DEC Kanji, Japanese EUC, and SJIS.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Japanese processing Extended Feature (JEF) code, developed by Fujitsu Ltd., is used mainly for its FACOM mainframe systems. Similar to the IBM Kanji System character set, JEF contains only two byte code (JIS X 0208, some Fujitsu-specific characters, and UDCs). JEF code is always used with EBCDIC. The shift codes used to distinguish JEF code and EBCDIC are shown in the following table.
| Meaning | Code Value |
|---|---|
| Begin JEF code | 0x28 |
| End IBM Kanji | ox29 |
JEF code can be converted to and from DEC Kanji, Super DEC Kanji, Japanese EUC, and SJIS.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Kanji processing Extended Information System (KEIS) code, developed by Hitachi Ltd., is used mainly for its mainframe systems. Similar to the IBM Kanji and JEF character sets, KEIS contains only two byte code (JIS X 0208, Hitachi-specific characters and UDCs). KEIS code is always used with EBCDIC. The shift codes used to distinguish KEIS code and EBCDIC are shown in the following table.
| Meaning | Code Value |
|---|---|
| Begin KEIS code | 0x0a42 |
| End KEIS code | 0x0a41 |
KEIS code can be converted to and from DEC Kanji, Super DEC Kanji, Japanese EUC, and SJIS.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The iconv utility provided by Compaq Tru64 UNIX converts the encoding of characters in one codeset to another and writes the results to standard output. The following pairs of Japanese codeset converters are provided:
DEC |
Japan- |
Super |
Shift |
JIS7 |
ISO- |
ISO- |
UCS-4 |
UTF-8 |
IBM |
JEF |
KEIS |
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|
DEC Kanji |
- |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Japanese EUC |
Y |
- |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Super DEC Kanji |
Y |
Y |
- |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Shift JIS |
Y |
Y |
Y |
- |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
Y |
JIS7 |
Y |
Y |
Y |
Y |
- |
N |
N |
N |
N |
N |
N |
N |
ISO-2022-JP |
Y |
Y |
Y |
Y |
N |
- |
N |
N |
N |
N |
N |
N |
ISO-2022-JPext |
Y |
Y |
Y |
Y |
N |
N |
- |
N |
N |
N |
N |
N |
UCS-4 |
Y |
Y |
Y |
Y |
N |
N |
N |
- |
Y |
N |
N |
N |
UTF-8 |
Y |
Y |
Y |
Y |
N |
N |
N |
Y |
- |
N |
N |
N |
IBM Kanji |
Y |
Y |
Y |
Y |
N |
N |
N |
N |
N |
- |
N |
N |
JEF |
Y |
Y |
Y |
Y |
N |
N |
N |
N |
N |
N |
- |
N |
KEIS |
Y |
Y |
Y |
Y |
N |
N |
N |
N |
N |
N |
N |
- |
For example, you can enter the following command to convert a DEC Kanji file to a Shift JIS file:
% iconv -f deckanji -t SJIS <file>
Use the strings shown in Table 2-6 as the parameters to the iconv utility.
Codeset |
String |
|---|---|
DEC Kanji |
deckanji |
Japanese EUC |
eucJP |
Super DEC Kanji |
sdeckanji |
Shift JIS |
SJIS |
JIS7 (ESC ( I for katakana) |
JIS7 |
JIS7 (SO/SI for katakana) |
jiskanji7 |
ISO-2022-JP |
ISO-2022-JP |
Extended ISO-2022-JP |
ISO-2022-JPext |
UCS-2 |
UCS-2 |
UCS-4 |
UCS-4 |
UTF-8 |
UTF-8 |
Hitachi KEIS |
KEIS |
Fujitsu JFE |
JFE |
IBM Kanji |
ibmkanji |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
There are four supported Japanese codesets that are used in the Japanese locales. They are DEC Kanji, super DEC Kanji, Japanese EUC, and SJIS. Each one has its own UDC ranges. There is a predefined mapping for UDC among these four codesets, as shown in the following table:
| SJIS | Deckanji | sdeckanji | eucJP |
|---|---|---|---|
| 0xf040-0xf4fc | 0xa121-0xaa7e | 0xa121-0xaa7e | 0xf5a1-0xfefe |
| 0xf540-0xf9fc | 0xab21-0xb47e | 0xab21-0xb47e | 0x8ff5a1-0x8ffefe |
| 0xfa40-0xfcfc | 0xb521-0xbb7e | 0xb521-0xbb7e | 0x8feea1-0x8ff3fe |
If you try to modify the codeset of a UDC, the UDC manager will ask if you want the other codeset values to be changed accordingly. Always choose the default answer to avoid problems with other software. For instance, if you define a SJIS UDC value of 0xf040, it will be mapped to the deckanji and sdeckanji value of 0xa121 and the eucJP value of 0xf5a1 automatically.
You should not use UDC outside the ranges defined in the above table; if you do, the automatic mapping wil not work properly.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Compaq Tru64 UNIX operating system provides a mechanism by which you configure your system to run applications with peripherals, such as terminals and printers, supporting different codesets. You can specify the codesets for the applications, terminals, and printers independently as shown in Table 2-7. The Compaq Tru64 UNIX software automatically converts data to the appropriate codeset.
The DEC terminal codeset is similar to DEC Kanji, but has support for Kana characters (in eucJP) as well. It has support for JISX0208 and JISX0208-1978, but not JISX0212 of eucJP. The dec78 codeset supports an older version of JISX0208-1978 which has characters that are slightly different from JISX0208-1983 supported in dec and deckanji.
Application Code |
Terminal Code |
Printer Code |
|---|---|---|
DEC Kanji |
DEC (dec) |
DEC Kanji |
Japanese EUC |
Japanese EUC |
Japanese EUC |
Super DEC Kanji |
|
Super DEC Kanji |
Shift JIS |
Shift JIS (SJIS) |
Shift JIS (SJIS) |
UTF-8 |
UTF-8 |
|
Note
Japanese DECterm software supports the deckanji, sdeckanji, or eucJP codeset (except for the user-defined characters) as its terminal code. The dxterm does not support UTF-8 as a terminal code. Use dtterm when UTF-8 is required for a terminal code.
For the details about setting up terminal code and printer code, please see Writing Software for the International Market or Nihongo Kinou Guide Book (written in Japanese).
![]()
![]()
![]()
![]()
![]()
![]()
![]()