![]()
![]()
![]()
![]()
![]()
![]()
![]()
The DIGITAL UNIX operating system software supports the following Chinese character sets:
For traditional Chinese characters the CNS 11643, DTSCS, and Big-5 character sets are commonly used. GB2312-80 and Extended GB character sets are commonly used for Simplified Chinese characters. The Unicode and ISO/IEC 10646 character sets are common to both traditional and Simplified Chinese.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The CNS (Chinese National Standard) 11643 character set standard was published by the National Bureau of Standards of Taiwan in 1986. It was also called "Standard Interchange Code for Generally-used Chinese Character" (SICGCC). CNS 11643 provides 16 character planes for defining Chinese characters. Each character plane is divided into 94 rows and each row has 94 columns. Altogether, a total number of 8,836 characters can be accommodated in each plane. Character planes 1-11 are reserved for defining standard Chinese characters while character planes 12-16 are user-defined areas.
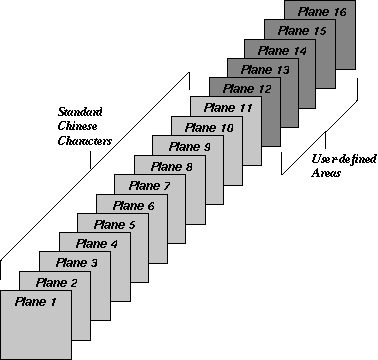
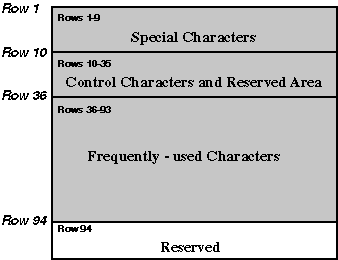
CNS 11643, published in 1986, defines certain groups of characters on the first and second character planes. Table 1-1 shows these groups of characters.
| Character Plane | Character Type | Number of Characters |
|---|---|---|
| Plane 1 | Special characters Control characters Frequently-used characters |
651 33 5,401 |
| Plane 2 | Less frequently-used characters | 7,650 |
Figure 1-2 and Figure 1-3 illustrate the positions of these characters in the first and second character planes.

As the CNS11643-1986 character set was not rich enough to meet most of the application requirements, such as names and addresses, the information industry in Taiwan requested to expand the character set. In 1991, the Bureau of National Standard formed a team to study how to expand CNS 11643. On August 4, 1992, the Bureau of National Standard published the revised CNS 11643 - Chinese Standard Interchange Code (CSIC).
The revised CNS 11643, called CNS 11643-1992, defined 651 special characters, 33 control characters and 48,027 Chinese characters, as shown in Table 1-2.
| Character Plane | Character Type | Number of Characters |
|---|---|---|
| Plane 1 | Special characters Control characters Frequently-used characters |
651 33 5,401 |
| Plane 2 | Less frequently-used characters | 7,650 |
| Plane 3 | Rarely-used characters (EDPC Part I) | 6,148 |
| Plane 4 | Used for residency system, ISO 2nd edition DIS 10646 Han characters, 171 EDPC Part II Characters | 7,298 |
| Plane 5 | Rarely-used characters (Based on the Ministry of Education publications) | 8,603 |
| Plane 6 | Variants based on the Ministry of Education publications (<=14 strokes) | 6,388 |
| Plane 7 | Variants based on the Ministry of Education publications (>14 strokes) | 6,539 |
Since the number of characters defined in CNS11643-1992 is far greater than those required for general use, the revised CNS 11643 is called "Chinese Standard Interchange Code (CSIC)".
Note
In this release, the new characters added to CNS 11643-1992 are not supported. Only the characters defined in CNS 11643-1986 and DTSCS (which will be described in the next section) are supported.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
In addition to CNS 11643, the DIGITAL UNIX operating system supports the DIGITAL Taiwan Supplemental Character Set (DTSCS). Currently, only the EDPC Recommended Character Set, which defines a total of 6,319 characters, is included in DTSCS. EDPC Recommended Character Set was first published by the Electronic Data Processing Center of Executive Yuen in June, 1988.

As a de facto standard, most of the vendors support the EDPC Recommended Character Set as the CNS 11643 character plane 14.
In the revised CNS 11643-1992, the 6,319 characters in the EDPC Recommended Character Set are assigned to the third and fourth character planes of CNS 11643, as shown in Table 1-3.
| EDPC Characters | Character Plane | Number of Characters |
|---|---|---|
| Part I | Plane 3 | 6,148 |
| Part II | Plane 4 | 171 |
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Big-5 character set, though not a national standard, is commonly used by the Taiwan information industry, particularly in the PC and workstation market. Big-5 character set was designed to meet the requirements of five major software vendors in Taiwan. Since its publication, much software and hardware, and many peripheral devices have been developed to support Big-5.
Big-5 is very similar to CNS 11643-1986. The frequently-used Chinese characters (5,401) defined in the two character sets are exactly the same except that their positions in the code table are different. For the less frequently-used Chinese characters, Big-5 defines two more characters in addition to the 7,650 characters defined in the second character plane of CNS 11643, and their positions in the code table are different.
Note
For DECwindows Motif, Big-5 is supported as a file code. That is, you can use DECwindows Motif to read, process, and output Big-5 data. However, the process code used inside DECwindows Motif and the fonts required to run Big-5 applications are in DEC Hanyu.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The GB2312-80 character set is a standard published by the State Bureau of Standardization of the People's Republic of China (PRC) in 1980 and put in force in May, 1981.
GB2312-80 defines a total of 7,445 characters, including 6,763 Chinese characters:
682 graphic symbols are defined and placed in rows 1-9.
Those are 3,755 frequently-used characters placed in rows 16-55.
Those are 3,008 less frequently-used characters placed in rows 56-87. See Figure 1-5.
The GB2312-80 code table is divided into 94 rows (Qu), numbered from 1 to 94. Each row has 94 columns (Wei), also numbered from 1 to 94.

![]()
![]()
![]()
![]()
![]()
![]()
![]()
The extended GB character set provides 8,836 (94 x 94) code points for defining user-defined characters. The 8,836 code points are divided into two regions:
The extended GB code table is similar to the GB2312 code table. It is divided into 94 rows and each row has 94 columns.
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The Unicode Standard: Worldwide Character Encoding, Version 1.0 specifies a universal character set (UCS) that contains definitions for 34,000 characters and includes a Private Use Area for vendor-defined or user-defined characters. The main features of this character set are:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
The ISO/IEC 10646 standard, which is specified in Information Technology-Universal Multiple-Octet Coded Character Set, ISO/IEC 10646, specifies a 32-bit unit, rather than 16-bit unit, for each abstract character defined in the UCS. The 16-bit character values in Unicode are zero-extended through a second 16-bit unit to conform to ISO/IEC 10646. The second, or low-surrogate, 16-bit unit is reserved for future use in both standards.
![]()
![]()
![]()
![]()
![]()
![]()
![]()